标签:union 类型转换 empty utils OLE array code file 学习
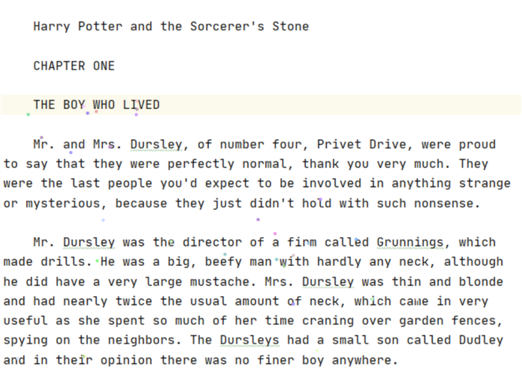
@Test//词频统计 def WordCount(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("wordCount") val sc=new SparkContext(conf) val result=sc.textFile("dataset/HarryPotter.txt") .flatMap(item=>item.split(" ")) .filter(item=>StringUtils.isNotEmpty(item)) .map(item=>(item,1)) .reduceByKey((curr,agg)=>curr+agg) .sortBy(item=>item._2,ascending = false) .map(item=>s"${item._1},${item._2}") .take(10) result.foreach(println(_)) }
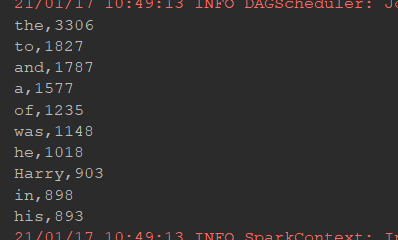
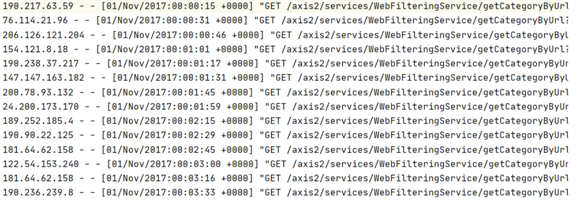
@Test//日志文件出现最多的ip def logIpTop10(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) sc.setCheckpointDir("checkpoint") val result=sc.textFile("dataset/access_log_sample.txt") .map(item=>(item.split(" ")(0),1)) .filter(item=>StringUtils.isNoneEmpty(item._1)) .reduceByKey((curr,agg)=>curr+agg) .cache()//缓冲区 result.checkpoint() val top10=result.sortBy(item => item._2, ascending = false).take(10) top10.foreach(println(_)) val max=result.sortBy(item => item._2, ascending = false).first() val min=result.sortBy(item => item._2, ascending = true).first() println("max:"+max+" min:"+min) }
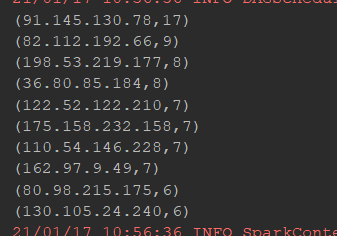

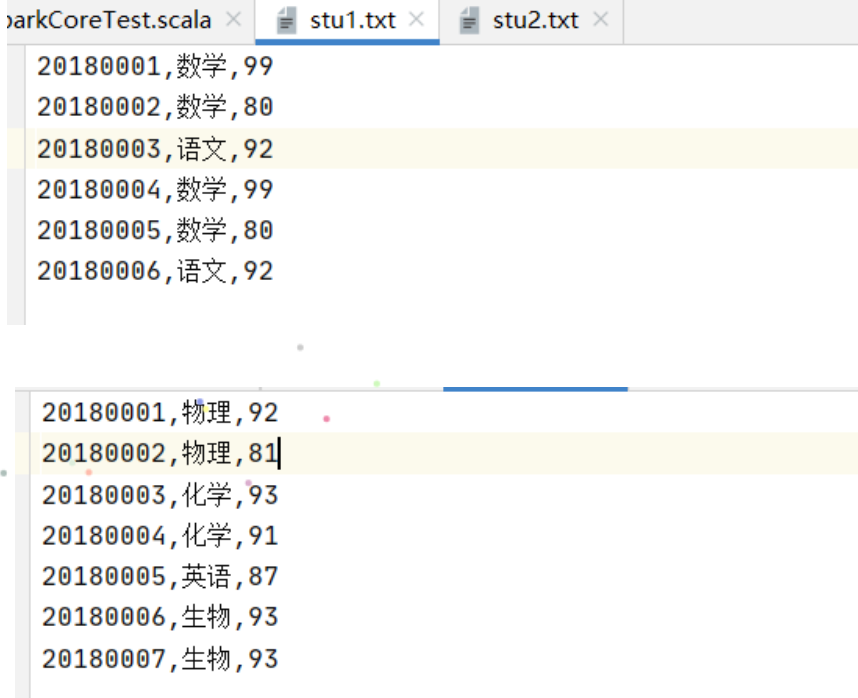
@Test//统计学生数,课程数,学生平均成绩 def stuGrade(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) val stu1=sc.textFile("dataset/stu1.txt") val stu2=sc.textFile("dataset/stu2.txt") val stu=stu1.union(stu2) val stuNum=stu.map(item=>(item.split(",")(0),(item.split(",")(1),item.split(",")(2)))) .groupByKey() .count() val courseNum=stu.map(item=>(item.split(",")(1),(item.split(",")(0),item.split(",")(2)))) .groupByKey() .count() println("学生数:"+stuNum+" 课程数:"+courseNum) val result=stu.map(item=>(item.split(",")(0),item.split(",")(2).toDouble)) .combineByKey( createCombiner = (curr: Double) => (curr, 1), mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1), mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2) ) .map(item=>(item._1,item._2._1/item._2._2)) .collect() result.foreach(println(_)) }

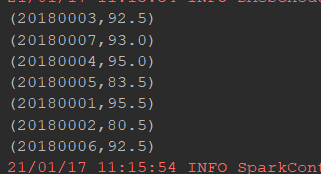
如下给出combineByKey的定义,其他的细节暂时忽略(1.6.0版的函数名更新为combineByKeyWithClassTag)
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null)
如下解释下3个重要的函数参数:
val initialScores = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 93.0), ("Wilma", 95.0), ("Wilma", 98.0)) val d1 = sc.parallelize(initialScores) type MVType = (Int, Double) //定义一个元组类型(科目计数器,分数) d1.combineByKey( score => (1, score), (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore), (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2) ).map { case (name, (num, socre)) => (name, socre / num) }.collect
@Test//按年月统计某省PM总数 def pmProcess(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) val source = sc.textFile("dataset/pmTest.csv") val result = source.map( item => ((item.split(",")(1), item.split(",")(2)), item.split(",")(6)) ) .filter( item => StringUtils.isNotEmpty(item._2) && ! item._2.equalsIgnoreCase("NA") ) .map( item => (item._1, item._2.toInt) ) .reduceByKey( (curr, agg) => curr + agg ) .sortBy( item => item._2, ascending = false) .map(item=> s"${item._1._1},${item._1._2},${item._2}") .collect() result.foreach(println(_)) }

标签:union 类型转换 empty utils OLE array code file 学习
原文地址:https://www.cnblogs.com/dazhi151/p/14287063.html