标签:mkdir spl eve art sparksql safe 输入数据 shuf 支持

面向对象的操作方式
可以处理任何类型的数据
RDD 的缺点
运行速度比较慢, 执行过程没有优化
API 比较僵硬, 对结构化数据的访问和操作没有优化
DataFrame 的优点
针对结构化数据高度优化, 可以通过列名访问和转换数据
增加 Catalyst 优化器, 执行过程是优化的, 避免了因为开发者的原因影响效率
DataFrame
只能操作结构化数据
只有无类型的 API, 也就是只能针对列和 SQL 操作数据, API 依然僵硬
Dataset 的优点
结合了 RDD 和 DataFrame 的 API, 既可以操作结构化数据, 也可以操作非结构化数据
既有有类型的 API 也有无类型的 API
在 Spark 中有很多场景需要存储对象, 或者在网络中传输对象
Task 分发的时候, 需要将任务序列化, 分发到不同的 Executor 中执行
缓存 RDD 的时候, 需要保存 RDD 中的数据
广播变量的时候, 需要将变量序列化, 在集群中广播
RDD 的 Shuffle 过程中 Map 和 Reducer 之间需要交换数据
算子中如果引入了外部的变量, 这个外部的变量也需要被序列化
RDD 因为不保留数据的元信息, 所以必须要序列化整个对象, 常见的方式是 Java 的序列化器, 和 Kyro 序列化器
Dataset 和 DataFrame 中保留数据的元信息, 所以可以不再使用 Java 的序列化器和 Kyro 序列化器, 使用 Spark 特有的序列化协议, 生成 UnsafeInternalRow 用以保存数据, 这样不仅能减少数据量, 也能减少序列化和反序列化的开销, 其速度大概能达到 RDD 的序列化的 20
Structured Streaming 已经支持了连续流模型, 也就是类似于 Flink
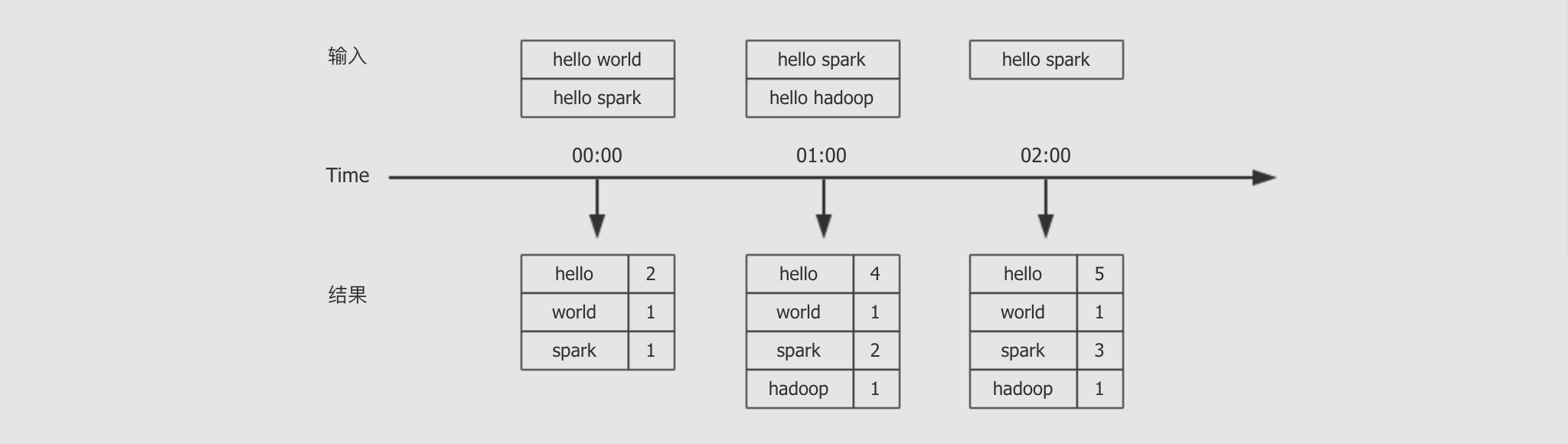
对消息中的单词进行词频统计
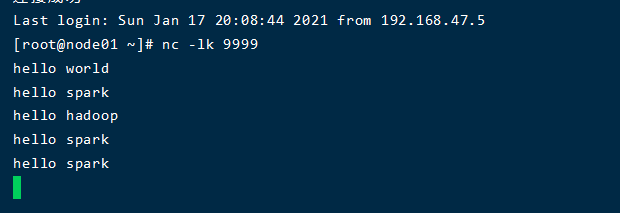
2、运行代码
package sparkStreaming import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SocketWordCount { def main(args: Array[String]): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("socket_structured") .getOrCreate() spark.sparkContext.setLogLevel("WARN") import spark.implicits._ // 2. 数据集的生成, 数据读取 val source: DataFrame = spark.readStream .format("socket") .option("host", "192.168.47.100") .option("port", 9999) .load() val sourceDS: Dataset[String] = source.as[String] // 3. 数据的处理 val words = sourceDS.flatMap(_.split(" ")) .map((_, 1)) .groupByKey(_._1) .count() // 4. 结果集的生成和输出 words.writeStream .outputMode(OutputMode.Complete()) .format("console") .start() .awaitTermination() } }
3、结果集

Structured Streaming 依然是小批量的流处理
Structured Streaming 的输出是类似 DataFrame 的, 也具有 Schema, 所以也是针对结构化数据进行优化的
从输出的时间特点上来看, 是一个批次先开始, 然后收集数据, 再进行展示, 这一点和 Spark Streaming 不太一样
Structured Streaming 中的编程模型依然是 DataFrame 和 Dataset
Structured Streaming 中依然是有外部数据源读写框架的, 叫做 readStream 和 writeStream
Structured Streaming 和 SparkSQL 几乎没有区别, 唯一的区别是, readStream 读出来的是流, writeStream 是将流输出, 而 SparkSQL 中的批处理使用 read 和
可以理解为 Spark 中的 Dataset 有两种, 一种是处理静态批量数据的 Dataset, 一种是处理动态实时流的 Dataset, 这两种 Dataset 之间的区别如下
流式的 Dataset 使用 readStream 读取外部数据源创建, 使用 writeStream 写入外部存储
批式的 Dataset 使用 read 读取外部数据源创建, 使用 write

Structured Streaming 程序处理数据import os for index in range(100): content = """ {"name": "Michael"} {"name": "Andy", "age": 30} {"name": "Justin", "age": 19} """ file_name = "/data/spark/test/text{0}.json".format(index) with open(file_name, "w") as file: file.write(content) os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -mkdir -p /spark/dataset/") os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -put {0} /spark/dataset/".format(file_name))
package sparkStreaming import org.apache.spark.sql.SparkSession import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.types.StructType object HDFSSource { def main(args: Array[String]): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .appName("hdfs_source") .master("local[6]") .getOrCreate() // 2. 数据读取, 目录只能是文件夹, 不能是某一个文件 val schema = new StructType() .add("name", "string") .add("age", "integer") val source = spark.readStream .schema(schema) .json("hdfs://node01:8020/spark/dataset") // 3. 输出结果 source.writeStream .outputMode(OutputMode.Append()) .format("console") .start() .awaitTermination() } }
Structured Streaming 从 HDFS 中读取数据并处理
Structured Streaming
标签:mkdir spl eve art sparksql safe 输入数据 shuf 支持
原文地址:https://www.cnblogs.com/MoooJL/p/14290130.html