标签:构建 hash 算法 instance 分析 数据 load member 存储
Core Idea: 对于 GC 主要有两种方式,reference count 和 mark and sweep。这片文章主要讨论了如何高效的进行 mark and sweep 过程。
Mark and sweep 思想是先遍历所有的 chunk,然后对于 GC 之后不再需要的 chunk 进行标记。对于被标记的 chunk 进行 sweep 操作。对于已经被标记的 chunk 进行删除操作所需要的时间主要依赖于数据布局,对于整个 GC 而言,整个时间的大头主要在于 sweep 阶段,但是 mark 阶段在新的系统中往往是瓶颈。如何本篇文章对于如何遍历进行标记提出了两种思路:Logical 上的和 Physical 上的,并且在 Physical 上的遍历有着更好的 performance。
实际当中,由于经常进行 Client 的增量备份和数据去重技术的出现,数据备份的数量已经非常多。并且,由于数据去重技术,重复引用的数据块对于GC也有一定的挑战。第二点,由于文件数量的大量增加,如今的备份已经从之前的打包备份逐渐转移到对于整个文件夹下大量单个文件整体的备份。这种备份方式同之前按照版本进行 GC 的方式也有一定差别。
Mark 阶段会对要遍历的文件构建一个基本的树形结构,使用哈希树把需要 chunk 进行连接,然后从上至下进行遍历。一共有6层,L6 为最高层 root 节点,L0 为最底层,chunk 节点,是真正的文件数据。连续的L0 节点的指纹构成了L1 的数据,并且这个L1 节点指向开始的 chunk 节点。从下往上构成了一棵树。一个文件本身就是一棵树,所以如果文件数量很多,就会有很多树。如果文件本身过小,可能无法形成一个树高为6的树,但此时仍然把最上层的节点称为L6节点。
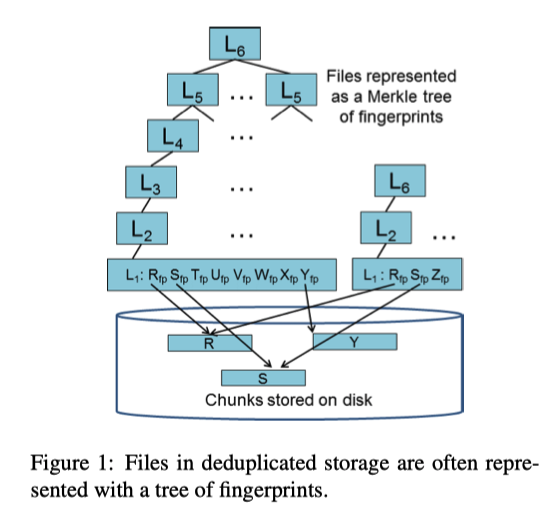
在此数据结构之上,有两种不同的 chunk 遍历方式:
Logical 级别:
Logical 级别枚举的坏处:由于去重算法的提升,实际生产中高压缩比会导致逻辑空间很大,但是实际存储的物理空间很小的情况。同时,由于枚举的是逻辑上连续的文件数据,实际上在物理空间中可能并不连续,此时的 IO 成为了 Random IO,需要的时间则进一步增加。论文中的 Fig3,Fig4 可以看到压缩比越高,GC 需要的时间就越长,文件数量越多,GC 需要的时间就越长。所以提出了 PGC ,在 Physical 级别进行枚举,
Physical 级别:使用了 perfect hash 作为辅助数组,并且枚举 container 中的 live chunk 而不是逻辑上的每个文件。
使用 perfect hash vector 进行 membership query 的查询。对于一个指纹信息,将 PHV 中对应的哈希值设置为1,对于 L1 到 L6 层的每一个 chunk,都设置不同的 PHV,进行映射。
为了保证 GC 过程的正确性,使用了 checksum 的方式进行校验。对于每一层的数据,都使用了两个 checksum 进行校验。使用了 Parent 和 Child 从上到下和从下到上进行校验。如果没有出错,那么 P 和 C 的校验值就会相等。
【Fast17】The Logic of Physical Garbage Collection in Deduplicating Storage
标签:构建 hash 算法 instance 分析 数据 load member 存储
原文地址:https://www.cnblogs.com/wAther/p/14291170.html