标签:dup cat 内容 png ISE 图片 查看 sum 逻辑
1.1 利用numpy库中的array方法生成多维数组,存储数据,可以为1维,2维...n维
1.11 一维数组
import numpy as np \n np.array([1,2,3,4]) *
结果:

且该数组具有列表的特性,可切片,更改

1.12 多维数组

同样具有列表的所有特性
2.1 Series数据结构
生成类似一维数组的数据结构
pd.Series([1,2,3,4],index=[‘a‘,‘b‘,‘c‘,‘d‘])
结果:

左边为索引列,索引标签默认为数字,从0、1、2...,右边为数据列
对Series数据结构同样可以按照列表规则进行索引
可以通过参数index对索引标签进行修改
Series的数据来源可以是列表,也可以是字典

字典的键直接充当了索引
可以通过方法astype()更改数据类型

插入数据

2.2 DateFrame 数据框结构
数据框支持多种数据类型,数据来源可以是列表与元组
数据框可以看作多个Series结构向右堆叠而成
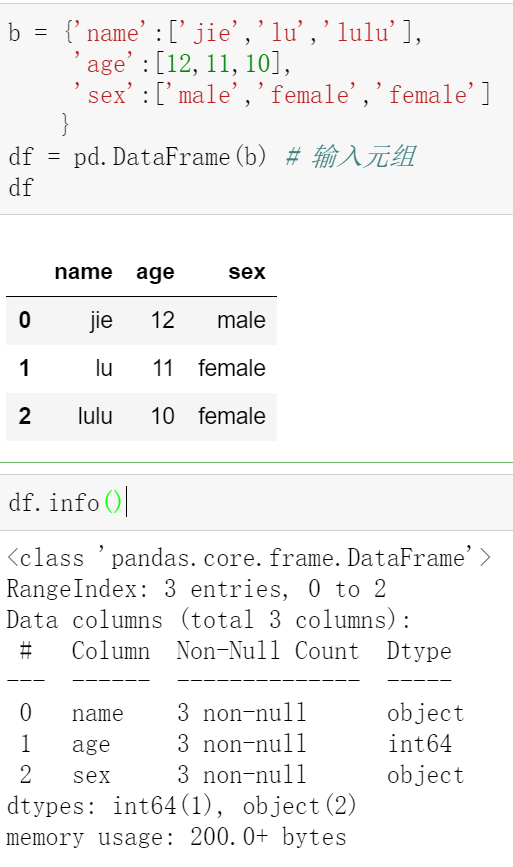
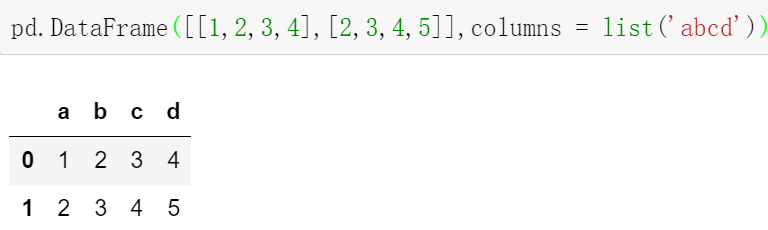
数据框可以通过columns参数对数据列标签进行修改
数据框索引可以分为两个方向,列和行
列方向的索引

将Dateframe变为Series,还可继续对Series进行索引和修改值

还可以对列进行多重索引

行方向的索引-loc iloc
df.loc(‘index索引标签‘,‘列标签‘)loc[0:1,‘列标签‘]
df.iloc(index数字,‘列数字’)/iloc[0:1,1]
当行无标签时,loc为闭区间,iloc为左开右闭区间
‘==‘为逻辑判断,返回值为布尔量
loc可用于布尔过滤率,iloc不适用
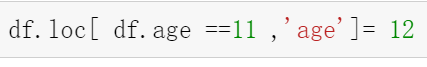
2.3 read_csv
通过pandas库方法read_csv读取csv文件到数据框
pd.read_csv(‘dataAnalyst_utf.csv‘,encoding =‘gbk‘)主要注意encoding参数,一般情况不是gbk就是utf8
可利用方法head(),tail()查看前几行,和后几行
也可用query()对内容进行过滤
2.32 parse_dates参数,boolean or list of ints or names or list of lists or dict, default False
boolean. True -> 解析索引
list of ints or names. e.g. If [1, 2, 3] -> 解析1,2,3列的值作为独立的日期列;
list of lists. e.g. If [[1, 3]] -> 合并1,3列作为一个日期列使用
dict, e.g. {‘foo’ : [1, 3]} -> 将1,3列合并,并给合并后的列起名为"foo"
2.4 df.sort_values()
by参数,排序依据,可为字符串可为列表,ascending=True降序,ascending=False升序
df.sort_index()按照索引序号排序
2.5 df.rank
df[‘rank‘] = df.avg.rank(axis=0,ascending = False,method = ‘first‘) #ascending 表示升序还是降序,可选择升序-True,降序-False #method 表示排列方式,按照平均排名排序-average,按照排名最小值排序-min,按照排名最大值排序-max,按照顺序排序-first
2.6 DateFrame.resample()
根据时间聚合重新采样
2.7 DateFrame.idxmax() 最大值所在的行标签
2.8 value_counts() 分组统计,自动去重,将非空重复值统计,一般是对Series操作,结果为Serise结构
2.9 DateFrame.cumsum() 累加方法,一般操作对象为Serise数据
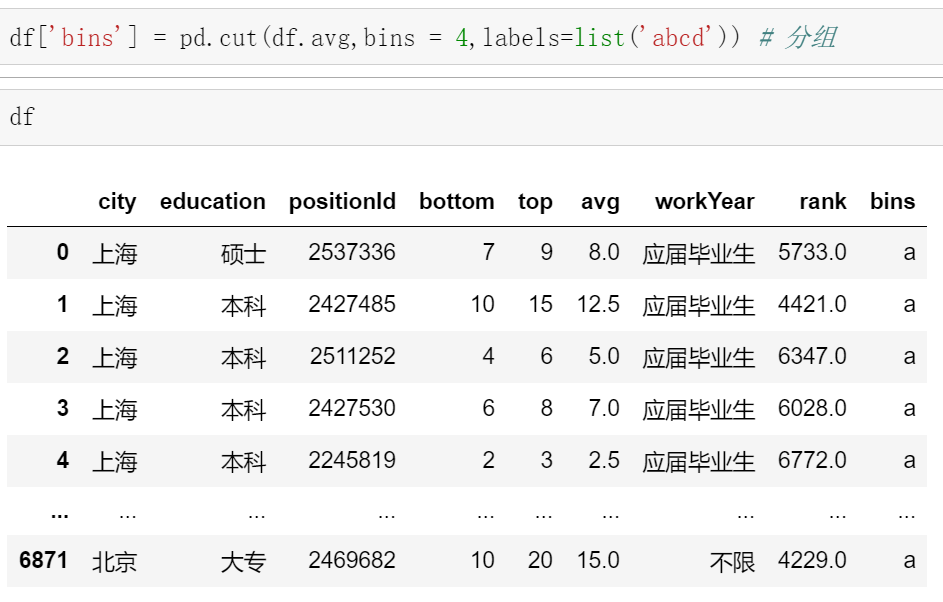
3.0 pandas.cut() 进行分组
3.1 grpupby() 分组,将分组数据存放到元组中,可以用for遍历,也可用mean,sum,max,min,median,sta,count,var 进行聚合操作
4.关联 merge join concat
merge 相当于sql的join
join 按照索引为依据,有重复列无法拼接
concat 堆叠,axis=0 按照上下堆叠,axis=1按照左右堆叠,相当于sql中的union
5.空值
5.1 设置空值
一般用numpy.nan
5.2 填充
DateFrame.fillna()
5.3 删除空值
DateFrame.dropna() #删除含有空值的行axis = 0 删除行,axis = 1 删除列
6.去重
6.1 duplicated() 返回指示重复行的布尔级数(False 或 True),可选地只考虑某些列。
参数:
subset : column label or sequence of labels, optional 子集: 列标签或标签序列,可选
Only consider certain columns for identifying duplicates, by default use all of the columns
只考虑标识重复项的某些列,默认情况下使用所有列
keep : {‘first’, ‘last’, False}, default ‘first’
first : Mark duplicates as True except for the first occurrence. 将重复项标记为True(第一次出现的除外)。
last : Mark duplicates as True except for the last occurrence. 将重复项标记为True(最后一次出现的除外)。
False : Mark all duplicates as True. 将所有重复项标记为True。
6.2 drop_duplicates() 返回删除重复行后的DataFrame,可以仅选择某些列。索引、时间型索引都是被忽略。
参数:
subset : column label or sequence of labels, optional 子集: 列标签或标签序列,可选
Only consider certain columns for identifying duplicates, by default use all of the columns
只考虑标识重复项的某些列,默认情况下使用所有列
keep : {‘first’, ‘last’, False}, default ‘first’
first : Drop duplicates except for the first occurrence. 删除重复行,只剩下第一次出现的重复行。
last : Drop duplicates except for the last occurrence. 删除重复行,只剩下最后一次出现的重复行。
False : Drop all duplicates. 删除全部重复行。
inplace : boolean, default False 默认为返回一个副本
Whether to drop duplicates in place or to return a copy
是直接在原数据上修改,还是返回一个副本
标签:dup cat 内容 png ISE 图片 查看 sum 逻辑
原文地址:https://www.cnblogs.com/lulu-1221/p/14269411.html