标签:zookeeper keep 简化 集群 ring key alt 基本 mapr
HBase 虽然可以存储数亿或数十亿行数据,但是对于数据分析来说,不太友好,只提供了简单的基于 Key 值的快速查询能力,没法进行大量的条件查询。现有hbase的查询工具有很多如:Hive,Tez,Impala,Shark/Spark,Phoenix等。今天主要说Hive,Hive方便地提供了Hive QL的接口来简化MapReduce的使用, 而HBase提供了低延迟的数据库访问。如果两者结合,可以利用MapReduce的优势针对HBase存储的大量内容进行离线的计算和分析。
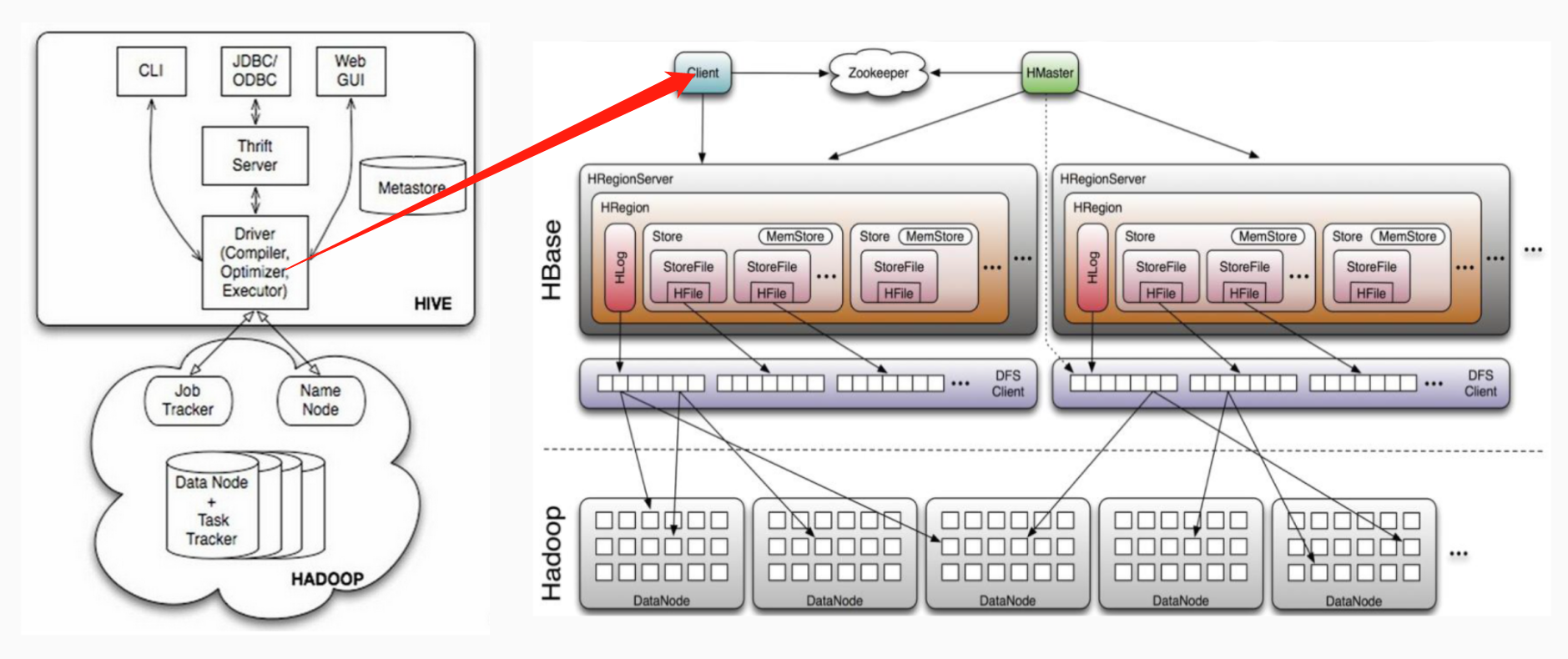
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,这种相互通信是通过$HIVE_HOME/lib/hive-hbase-handler-{hive.version}.jar工具类实现的。通过HBaseStorageHandler,Hive可以获取到Hive表所对应的HBase表名,列簇和列,InputFormat、OutputFormat类,创建和删除HBase表等。Hive访问HBase中表数据,实质上是通过MapReduce读取HBase表数据,其实现是在MR中,使用HiveHBaseTableInputFormat完成对HBase表的切分,获取RecordReader对象来读取数据。对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map;读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤;Scanner通过RPC调用RegionServer的next()来获取数据;
基本通信原理如下:
新建hbase表:
create ‘test‘, ‘f1‘
插入数据:
put ‘test‘,‘1‘,‘f1:c1‘,‘name1‘
put ‘test‘,‘1‘,‘f1:c2‘,‘name2‘
put ‘test‘,‘2‘,‘f1:c1‘,‘name1‘
put ‘test‘,‘2‘,‘f1:c2‘,‘name2‘
put ‘test‘,‘3‘,‘f1:c1‘,‘name1‘
put ‘test‘,‘3‘,‘f1:c2‘,‘name2‘
这里hbase有个列簇f1,有两个列c1和c2,新建hive表关联hbase的这两列:
SET hbase.zookeeper.quorum=zkNode1,zkNode2,zkNode3;
SET zookeeper.znode.parent=/hbase;
ADD jar hive-hbase-handler-{hive.version}.jar;
CREATE EXTERNAL TABLE test.test (
rowkey string,
c1 string,
c2 string
) STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler‘
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:c1,f1:c2")
TBLPROPERTIES ("hbase.table.name" = "test");
这里使用外部表映射到HBase中的表,hive对应的hdfs目录是空的,数据仍然在hbase中,这样在Hive中删除表,并不会删除HBase中的表,否则,就会删除。
另外,除了rowkey,其他三个字段使用Map结构来保存HBase中的每一个列族。
其中,参数解释如下:
指定HBase使用的zookeeper集群,默认端口是2181,可以不指定,如果指定,格式为zkNode1:2222,zkNode2:2222,zkNode3:2222
指定HBase在zookeeper中使用的根目录
Hive表和HBase表的字段一一映射,分别为:Hive表中第一个字段映射:key(rowkey),第二个字段映射列族f1:c1,第三个字段映射列族发:f1:c2。
HBase中表的名字
也可以直接在Hive中创建表的同时,完成在HBase中创建表。
在hive中查询hbase表:
hive> select * from test.test;
OK
1 name1 name2
2 name1 name2
3 name1 name2
也可以插入数据:
insert into test.test select ‘4‘, ‘name4‘, ‘name4‘;
查看hbase的数据:
hive> select * from test.test;
OK
1 name1 name2
2 name1 name2
3 name1 name2
4 name4 name4
hive关联hbase实际是底层是MR,速度较慢,此时可以使用spark读取hive表,进行查询操作,从而访问hbase数据。
关注公众号:Java大数据与数据仓库,领取资料,学习大数据技术。
标签:zookeeper keep 简化 集群 ring key alt 基本 mapr
原文地址:https://www.cnblogs.com/data-magnifier/p/14305429.html