标签:panda fit lang mod inf image nump compile lib
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv("E:/datasets/dataset/credit-a.csv", header = None) # 获取数据
x = data.iloc[:, :-1]
y = data.iloc[:, -1].replace(-1, 0)
data.head()
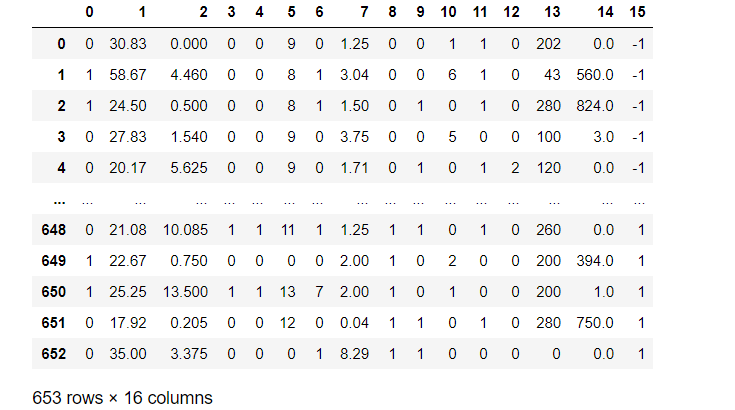
观察发现,最后一列(label)非0即1。因此,这是一个二分类问题。可以考虑把-1全都替换成0
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4, input_shape = (15, ), activation = ‘relu‘))
model.add(tf.keras.layers.Dense(4, activation = ‘relu‘))
model.add(tf.keras.layers.Dense(1, activation = ‘sigmoid‘))
model.summary()

这个模型第一层,有4个神经元,因为输入是15个参数,因此参数个数为\(4*15+4=64\)。这里使用ReLU作为激活函数;
模型第二层,有4个神经元,输入是4个参数,因此参数个数为\(4*4+4=20\)。这里使用ReLU作为激活函数;
模型第三层,有1个神经元,输入是4个参数,因此参数个数为\(1*4+1=5\)。这里使用Sigmoid作为激活函数。
这里总共有89个参数
model.compile(
optimizer = ‘adam‘,
loss = ‘binary_crossentropy‘,
metrics = [‘acc‘] # 设置显示的参数
)
这里是二分类问题,因此损失函数可以设置为binary_crossentropy
history = model.fit(x, y, epochs = 1000) # 训练1000次

下面我们来看一下模型的一些参数
history.history.keys()
发现有loss和acc两个参数
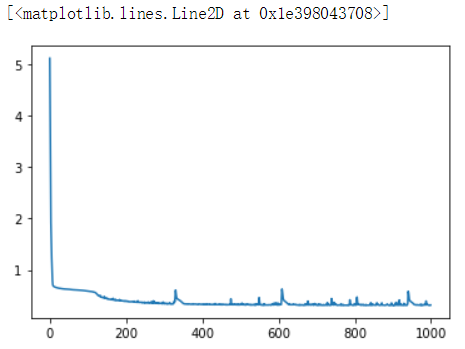
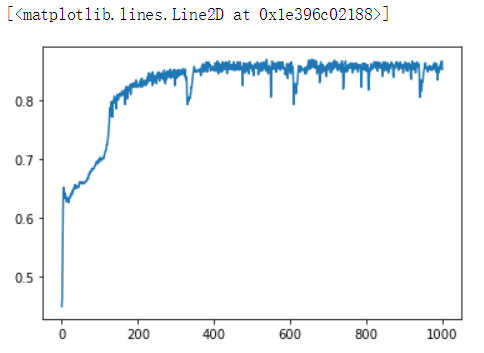
然后,我们再画出随着训练轮数的增加,loss和acc的变化曲线图
plt.plot(history.epoch, history.history.get(‘loss‘))
plt.plot(history.epoch, history.history.get(‘acc‘))
loss变化曲线图:
acc变化曲线图:
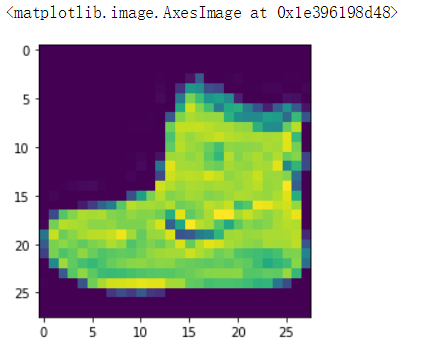
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data() # 获取数据
plt.imshow(train_image[0]) # 显示第一张图片
数据归一化:
train_image = train_image / 255
test_image = test_image / 255
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = (28, 28)))
model.add(tf.keras.layers.Dense(128, activation = ‘relu‘))
model.add(tf.keras.layers.Dense(10, activation = ‘softmax‘))
因为输入图像是二维的(28*28),因此需要先将其变换成一维向量。
第一层128个神经元,激活函数为ReLU
第二层10个神经元,激活函数为softmax
model.compile(
optimizer = ‘adam‘,
loss = ‘sparse_categorical_crossentropy‘,
metrics = [‘acc‘]
)
这里因为是多分类问题,并且标签是一般的数值标签,因此损失函数使用sparse_categorical_crossentropy
model.fit(train_image, train_label, epochs = 10) # 训练10次

在测试集上评估训练的模型
model.evaluate(test_image, test_label)

train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
model.compile(
optimizer = ‘adam‘,
loss = ‘categorical_crossentropy‘,
metrics = [‘acc‘]
)
因为使用的是one-hot编码,因此损失函数使用categorical-crossentropy
标签:panda fit lang mod inf image nump compile lib
原文地址:https://www.cnblogs.com/miraclepbc/p/14311509.html