标签:归一化 mat 时间 blank sum 描述 abc 预测 https
什么是Seq2Seq
Seq2Seq模型,全称Sequence to sequence,由Encoder和Decoder两个部分组成,每部分都是一个RNNCell(RNN、LSTM、GRU等)结构。Encoder将一个序列编码为一个固定长度的语义向量,Decoder将该语义向量解码为另一个序列。输入序列和输出序列都可以是不定长序列。
Seq2Seq可以用于机器翻译、文本摘要生成、对话生成等领域。
Seq2Seq结构
Seq2Seq包含一个RNN作为Encoder对输入序列进行编码,一个RNN作为Decoder对输出序列进行解码。下面参考https://zhuanlan.zhihu.com/p/70880679介绍两种最常用的Seq2Seq结构。
为简化描述,这里都以RNN代替LSTM和GRU,并且省略偏置项。
结构1
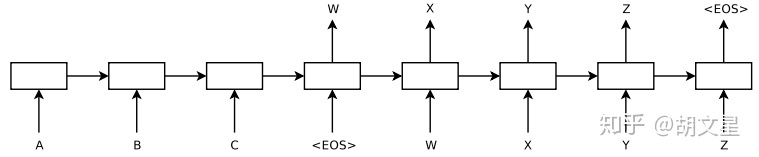
Encoder输入序列ABC,生成语义向量 c 作为Decoder的初始隐藏状态,Decoder中初始时刻输入 \(<EOS>\)作为开始标志,直至输出\(<EOS>\)结束预测。
Encoder第i个时刻的隐藏状态和输出为:
Encoder输出的语义向量为最后一个时刻T的隐藏状态:
Decoder第t个时刻的隐藏状态和输出为:
Decoder的初始隐藏状态为Encoder编码的语义向量,即:
结构2
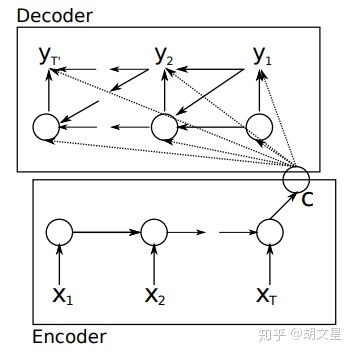
结构1的Encoder所编码的语义向量只作用于Decoder的第一个时刻,而结构2的语义向量作用于Decoder的每一个时刻。
结构2的Encoder部分与结构1一致,唯一一点小区别是会对语义向量做一个非线性变换:
Decoder部分,结构2首先会初始化一个开始信号\(y_0\)(如\(<Start>\))以及一个初始隐藏状态\(s_0\),Decoder第t个时刻的隐藏状态和输出为:
Seq2Seq+Attention
Seq2Seq+Attention都是基于上述结构2,即Encoder生成的语义向量c会传给的Decoder每一个时刻。但这显然是不合理的。比如翻译一句话,I like watching movie.翻译成:我喜欢看电影。,其中喜欢基本上是由like得来的,I like watching movie.中每个词对翻译成喜欢的影响是不同的。所以,在Decoder中,每个时刻的语义向量 \(c_t\) 都应该是不同的。Seq2Seq+Attention基于的就是这一想法。
这里参考https://zhuanlan.zhihu.com/p/70905983介绍两种Seq2Seq+Attention的方法,分别为Bahdanau Attention和Luong Attention。
Bahdanau Attention
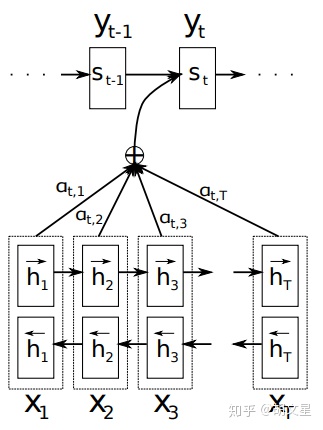
Encoder部分与前面所述一致,Decoder部分每个时刻的语义向量 \(c_t\) 通过以下方式生成:
其中\(\alpha_{ti}\)为输入序列第i个字符对输出序列第t个字符的归一化权重,\(e_{ti}\)为归一化前的权重,\(v_a^T\)和\(W_a\)为Attention的可学习参数。
Decoder第t个时刻的隐藏状态和输出为:
Luong Attention
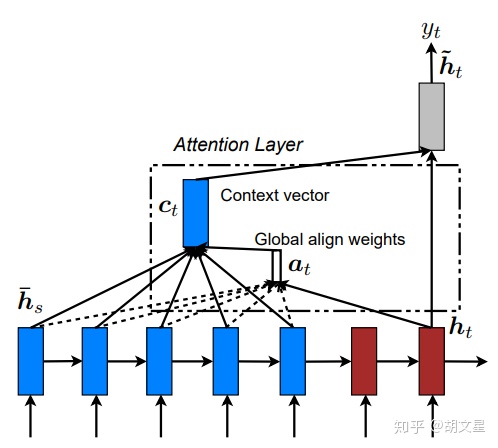
Luong Attention与Bahdanau Attention不同的地方在于归一化前的权重计算,其计算方式为:
然后计算注意力层的隐层状态和输出:
需要注意的是Decoder传给下一个时刻的隐藏状态是\(s_t\)而不是\(\widetilde s_t\)。
Bahdanau Attention与Luong Attention两种注意力机制大体结构一致,区别在于计算影响程度的对齐函数。在计算时刻的影响程度时,前者使用\(s_{t-1}\)和\(h_i\)来计算,后者使用\(s_t\)和\(h_i\)来计算。从逻辑来看貌似后者更合逻辑,但两种机制现在都有在用,效果应该没有很大差别。
Seq2Seq训练
Seq2Seq对Encoder和Decoder进行联合训练,目标是使得给定输入序列的目标序列的条件概率最大化,即:
损失函数为:
预测时需要将Decoder上一个时刻的输出作为下一个时刻的输入,在训练中我们也可以将标签序列(训练集的真实输出序列)在上?个时间步的标签作为解码器在当前时间步的输?。这叫作强制教学(teacher forcing)。一般设置一个强制教学的比例,如50%使用强制教学,剩下的50%将Decoder上一个时刻的输出作为下一个时刻的输入。
Seq2Seq预测
设输出词汇表大小为|Y|(包括\(<EOS>\)),输出序列的最大长度为\(T‘\)。
穷举模式(exhaustive search)
穷举所有可能的\(|Y|^{T‘}\)个输出序列然后选择最优序列。但这样时间空间消耗都非常的大,一般不用。
贪婪模式(greedy search)
每个时刻都选择当前时刻条件概率最大的词,即:
?旦搜索出\(<EOS>\),或者输出序列长度已经达到了最大长度T′,便完成输出。
贪婪模式不能保证搜索出全局最优。
束搜索(beam search)
束搜索(beam search)是对贪婪搜索的?个改进算法。它有?个束宽(beam size)超参数。我们将它设为 k。在时间步 1 时,选取当前时间步条件概率最?的 k 个词,分别组成 k 个候选输出序列的?词。在之后的每个时间步,基于上个时间步的 k 个候选输出序列,从 k |Y| 个可能的输出序列中选取条件概率最?的 k 个,作为该时间步的候选输出序列。
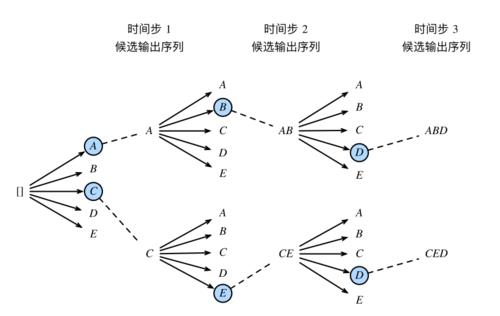
由于束搜索倾向于选择长度较短的输出序列,因此一般对长度进行归一化,每个序列的得分为:
当\(\alpha\)取0时不进行长度归一化,取1时进行标准长度归一化。取值是试探性的,可以尝试不同的值,看哪一个能得到最好的结果。一般取0.7。
束搜索的PyTorch实现方式可以参考:https://blog.csdn.net/u014514939/article/details/95667422。
BLEU得分
BLEU(bilingual evaluation understudy,双语互译质量评估辅助工具),是用来评估机器翻译质量的一个指标,其计算公式为:
其中,\(P_n\)为n-gram对应的得分,\(w_n\)为n-gram的权重,k为希望匹配的最长的子序列长度,BP为长度惩罚项。
其中,\(Count_n\)为翻译序列中所有n-gram的数量,\(Count_n^{clip}\)为翻译序列中所有n-gram与所有参考翻译的匹配数量,例如对于某个n-gram,其在翻译序列中出现次数为3,在3个参考翻译中出现次数为2,4,1,则\(Count_n^{clip}=min(3,max(2,4,1))=3\)。
一般将各n-gram的作用视为等重要的,即取权重服从均匀分布,即:
由于对于较长序列,其\(P_n\)往往较小,因此较长序列的BLEU得分往往偏小。BP项对短序列施加惩罚:
其中c为翻译序列长度,r为所有参考序列中最大的长度。
标签:归一化 mat 时间 blank sum 描述 abc 预测 https
原文地址:https://www.cnblogs.com/lyq2021/p/14325262.html