标签:add max 转换 合规 rgs als pre http simple
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Map {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
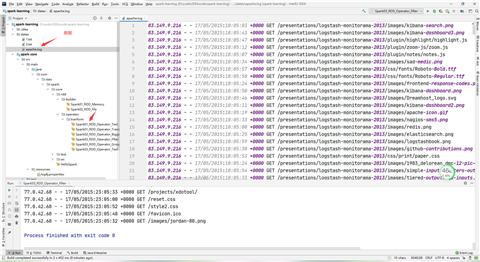
val rdd: RDD[String] = sc.textFile("datas/apache.log")
val value: RDD[String] = rdd.map({
line => {
val address: String = line.split(" ")(6)
address
}
})
value.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_RDD_Operator_MapPartitions {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
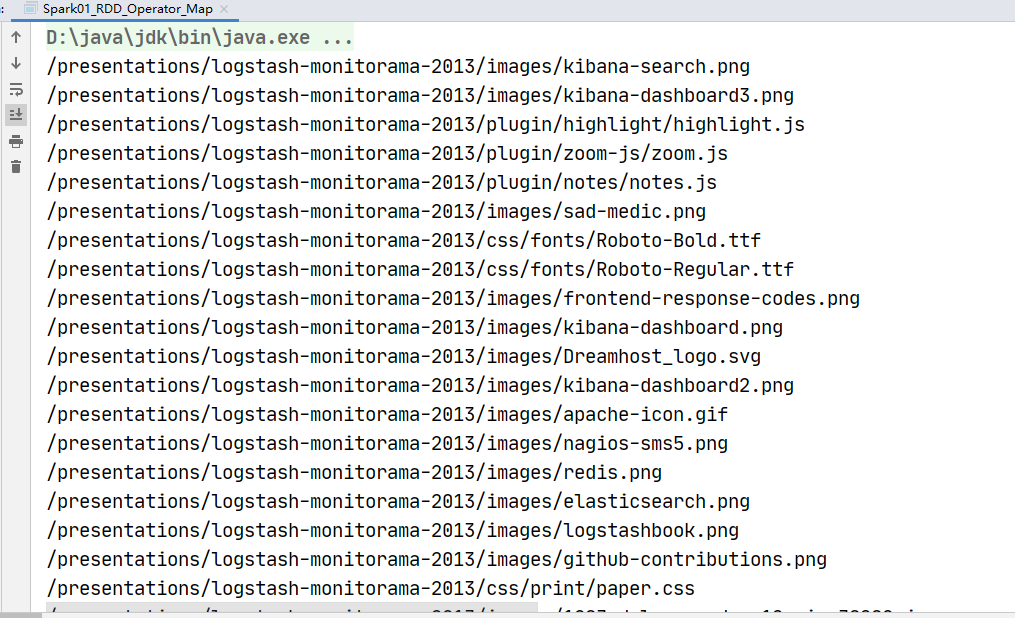
// 求每个分区的最大值
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),numSlices = 2)
val value: RDD[Int] = rdd.mapPartitions(
iter => {
List(iter.max).iterator
}
)
value.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_MapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
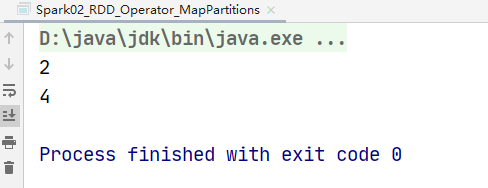
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),numSlices = 2)
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex(
(index, iter) => {
iter.map(
num => {
(index, num)
}
)
}
)
value.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_FlatMap {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
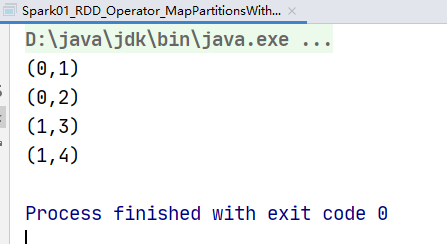
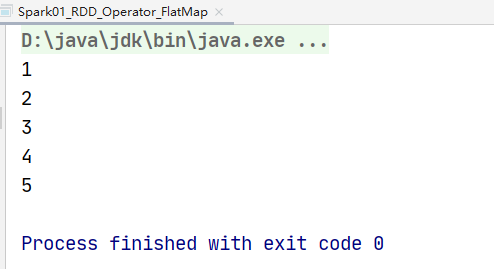
val rdd: RDD[Any] = sc.makeRDD(List(List(1, 2), 3, List(4, 5)))
val value: RDD[Any] = rdd.flatMap(
// 用模式匹配
data => {
data match {
case list: List[_] => list
case dat => List(dat)
}
}
)
value.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Glom {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
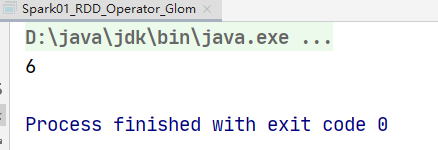
// 【1,2】【3,4】
// 【2】【4】
// 6
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),numSlices = 2)
// 变成数组
val glomRDD: RDD[Array[Int]] = rdd.glom()
// 取最大值
val maxRDD: RDD[Int] = glomRDD.map(
array => {
array.max
}
)
println(maxRDD.collect().sum)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_GroupBy {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
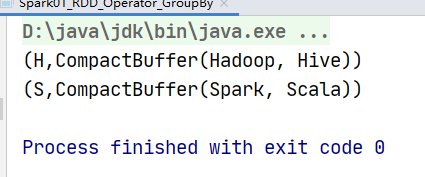
// 按照首字母进行分组
// val rdd: RDD[String] = sc.makeRDD(List("Hadoop","Spark","Scala","Hive"))
//
// val value: RDD[(Char, Iterable[String])] = rdd.groupBy(_.charAt(0))
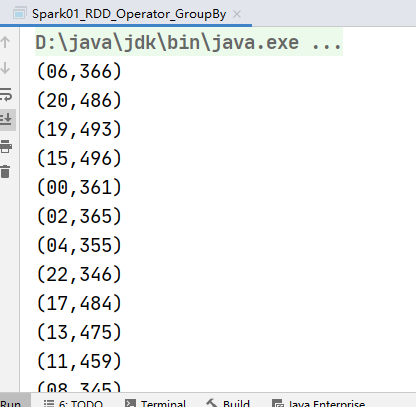
// 从服务器日志数据 apache.log 中获取每个时间段访问量
val rdd: RDD[String] = sc.textFile("datas/apache.log")
val timeRDD: RDD[(String, Iterable[(String, Int)])] = rdd.map(
line => {
val time: String = line.split(" ")(3)
val sdf = new SimpleDateFormat("dd/MM/yy:HH:mm:ss")
val date: Date = sdf.parse(time)
val sdf1 = new SimpleDateFormat("HH")
val hour: String = sdf1.format(date)
(hour, 1)
}
).groupBy(_._1) // _._1 获取元组第一个元素 ._1:取第一个元素
val value: RDD[(String, Int)] = timeRDD.map {
case (hour, iter) => (hour, iter.size)
}
value.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Filter {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("datas/apache.log")
val timeRDD: RDD[String] = rdd.filter(
line => {
val time: String = line.split(" ")(3)
time.startsWith("17/05/2015")
}
)
timeRDD.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
spark-------------RDD 转换算子-----value类型(一)
标签:add max 转换 合规 rgs als pre http simple
原文地址:https://www.cnblogs.com/yangxiao-/p/14326296.html