标签:计算机视觉 选择性 包括 inf 进一步 load 选择 相关 多个
paper地址:arxiv.org/pdf/2007.08113.pdf
code地址:https://github.com/vinthony/depth-distillation
1. 使用预先训练好的网络作为正则化深度蒸馏,同时学习离焦图(defocus map)。
2. 设计一个监督引导的注意块(SAB: Supervision-guided Attention Block),用于对每个侧边输出特征的每一层重新加权。
3. 在每个解码器中设计选择性接收域块(SRFB: Selective Reception Field Block), SRFB能提取更大的感受野,用于构建更丰富的特征金字塔,并使用全局选择注意力去加权重要的特征。
4. 通过将深度估计引入到离焦模糊检测(DBD), 以及设计相关模块(2,3),使提出的方法比其他的方法具有更高的性能。
以上属于个人总结出来的,下面放出了原文。

离焦模糊,在摄影中也被称为散景效果,在日常照片中得到了广泛的应用。对焦区域强调突出的物体,而失焦模糊可以保护出现在照片中的人的隐私。此外,检测这种模糊也是至关重要的,因为检测到的离焦区域可能在执行任务时有用。这些任务包括自动重对焦[1]、显著目标检测[14]和图像重定位[15]。
传统方法聚焦在设计新颖的手工特征,比如说梯度特征或频率特征。然而,这些方法提取的特征有限,缺乏高层次的语义信息。因此,在场景复杂的情况下,很难通过特定的特征来区分离焦区域。
近年来,基于深度学习的方法在各种计算机视觉任务和离焦模糊检测中表现出了优异的性能。例如Park等[27]训练CNN,对图像中每个局部patch的锐度进行分类。将DBD视为场景分割,提出了更深层次的全卷积方法[45,43,44,34]。虽然这些方法强调了图像尺度在DBD中的重要性,但它们仍然是从二维的角度考虑DBD,并且仅仅依赖于数据集和神经网络的力量。本文从摄影中散焦模糊产生的原因入手。如图1(a)所示,由于相机只拍摄一定深度范围内的清晰照片,所以形成了sharp focus region,也称为depth- offfield (DOF[35])。当光波在成像平面的后方或前方相交时(图1(a)中的红绿线),其产生的区域在最终图像中会变得模糊。由于DBD中的均匀区域通常包含多个目标,且很难被边缘或语义特征检测到,因此摄像机与场景目标之间的距离(深度)为分类提供了较强的先验性。然而,无约束深度估计是一个不适定问题。为了评估现有的DBD数据集,并与之前的方法进行公平的比较,我们提出使用预先训练好的网络[3]作为正则化深度蒸馏,同时学习离焦图。此外,我们设计了一个监督引导的注意块(SAB),用于根据每个水平的侧输出重新加权学习特征。最后,模糊置信度是相对的,这意味着当我们放大一个尖锐的patch时,我们可以认为它是模糊的,反之亦然。虽然以前的方法[43,44,34]已经讨论了多流或跨层融合网络,但我们认为在每个解码器中设计选择性接收域块(SRFB)是一种有效的方法。我们的块提取更大的接收字段来构建更丰富的特征金字塔,并使用全局选择性注意力来加权有用特征的重要性。通过在DBD和所提出的块中加入深度估计,我们的网络在散焦检测方面优于其他方法。如图1 (b)-(i)所示,之前的DBD方法对颜色比较敏感,而在我们的网络中,DBD和深度估计任务是相互建立的,并能很好地预测结果。
我们将DBD定义为一个有监督的基于像素的二分类问题,并以DOF为关注对象。提出方法的算法为:
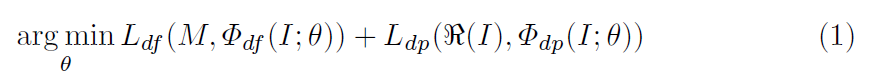
其中,I和M为输入源图像和对应的DOF标签,Φdf(I;Θ)和Φdp
一般来说,知识蒸馏[9,24]的目的是将知识转移到网络结构优化中。具体来说,如图2(a)所示,除了使用预测的离散硬目标传递知识外,他们在连续软标签(Softmax的输出)空间中使用更大的(教师)网络对紧凑(学生)模型进行正则化。
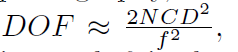
有趣的是,我们发现DBD(discrete, classification task)和深度估计(continuous, regression task)与知识蒸馏中硬标签和软标签之间的关系相似。在摄影中,锐焦区域(DOF)在数学上被定义上面公式,其中N分别是镜头的f个数,C是模糊圈,f是焦距。深度D是唯一一个不是相机参数。
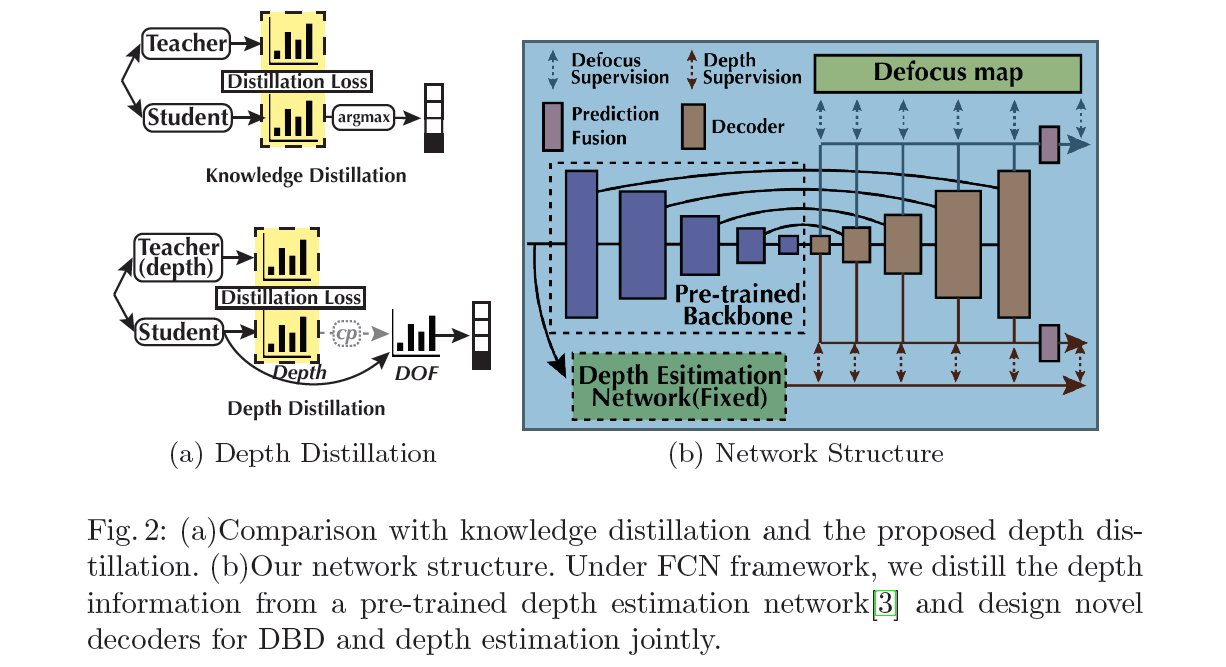
如图2(a)所示,我们提出深度蒸馏来帮助离焦模糊检测。详细地说,我们认为深度是近似软标签,并从预先训练好的网络中提取深度信息作为DBD的正则化。由于相机参数不可用,该网络可以预测离焦和提取深度,而不是直接从深度图计算DOF,再通过知识蒸馏推断离焦。深度蒸馏和知识蒸馏的结构虽然相似,但目标完全不同:我们的目标是将三维信息融入到DBD任务中,而不是从教师网络中提取一个紧凑的模型。为了实现,我们设计了一个简单而有效的框架来实现前面的分析。如图2(b)所示,我们生成多个深度估计输出,这些输出由一个预先训练好的网络监督。然后,通过fusion (1x1 Conv.)块融合所有侧输出以获得最终深度。然而,单幅图像的深度估计是病态的,因为稠密的深度很难采集,尤其是在无约束的情况下。因此,我们选择相对深度网络(Chen et al.[3])作为教师网络。具体来说,它们旨在学习场景对象之间的关系,而不是精确的深度值。因此,他们将800对点之间的空间关系(如点A,点B具有相同的深度,点A比点B更靠近摄像机,点B更靠近摄像机)作为监督标记为前图像。然后,利用大规模训练样本,神经网络可以预测密集相对深度。
像深度蒸馏一样将深度信息利用到DBD有很多好处。首先,深度蒸馏帮助我们的网络更好地理解场景,除了二元分类(类似于知识蒸馏中的关系)。输入的模糊区域也给出了图3所示的解码器的详细结构,其中红色箭头分别表示离焦监督和深度蒸馏。
对相对深度估计的密集提示。最后,通过深度蒸馏,我们在测试中不需要预先训练的深度网络,这也有助于建立一个高效的算法。从相对深度网络中提取也很关键。由于DBD的训练数据集只有600张图像,因此预先训练好的相对深度网络(野外421K训练图像)从更大规模的数据集到我们的网络和任务中包含了更精确的3D特征。此外,我们发现Chen等人的网络能够自动定位突出目标并预测其相对深度。幸运的是,DBD有一个类似的目标,因为摄影师经常使用散焦模糊来强调重要的观点。
我们的网络结构是基于全卷积网络(FCN[23])。如图2(b)所示,我们在ImageNet上预先训练的ResNeXt101[38]中,在每个MaxPooling层之前提取多尺度特征(共5层)。这些多尺度特征既包含高层次语义特征,又包含低层细节,以便进一步检测。在每个解码器中,如图3所示,我们使用带有卷积的上采样层代替反卷积层(或转置卷积层),以避免棋盘格伪影[18,26]。然后,在考虑尺度在DBD中的重要性的基础上,从多尺度特征建模和保存的几个方面进行了研究。一方面,我们在解码器的每一级设计辅助分类器,如[10,21,18],以防止过拟合,产生多尺度结果。不同的是,在解码器的每一层,我们分别设计了两个辅助分类器用于DBD和深度蒸馏的监督。每个辅助分类器被定义为一个1x1卷积层用于边预测,我们重用这些边输出作为监督引导的注意块(SAB)用于空间注意(如图3所示)。然后,将所有多尺度的中间输出图合并,以1x1卷积层作为图2(b)中的预测融合块,得到最终的离焦和深度图。另一方面,我们在解码器的每一层对多尺度接收域进行建模,并提出选择性接收域块(Selective reception Field Block, SRFB)来有效地选择和合并多环境下的特征。接下来,我们提供建议区块的细节。
Defocus Blur Detection via Depth Distillatio
标签:计算机视觉 选择性 包括 inf 进一步 load 选择 相关 多个
原文地址:https://www.cnblogs.com/haifwu/p/14332111.html