标签:计算资源 利用 网络模型 模糊 改进 不容易 oss bsp 感受
AlexNet中的trick:AlexNet将CNN用到了更深更宽的网络中,其效果分类的精度更高相比于以前的LeNet,其中有一些trick是必须要知道的.
ReLU的应用:AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题。
Dropout随机失活:随机忽略一些神经元,以避免过拟合。神经网络的一个比较严重的问题就是过拟合问题,论文中采用的数据扩充和Dropout的方法处理过拟合问题。在全连接层中去掉了一些神经节点,达到防止过拟合的目的,AlexNet在第六层和第七层都设置了Dropout。
重叠的最大池化层:在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。论文中说,在训练模型过程中,覆盖的池化层更不容易过拟合。
提出了LRN层:局部响应归一化,对局部神经元创建了竞争的机制,使得其中响应小打的值变得更大,并抑制反馈较小的。
使用了GPU加速计算:使用了gpu加速神经网络的训练
数据增强:数据扩充是防止过拟合的最简单的方法,只需要对原始的数据进行合适的变换,就会得到更多有差异的数据集,防止过拟合。常用的数据增强的方法有 水平翻转、随机裁剪、平移变换、颜色、光照、对比度变换。
主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
之前面试遇到一个问题:说说你对卷积核的理解。
使用2个3x3卷积核可以来代替5*5卷积核:
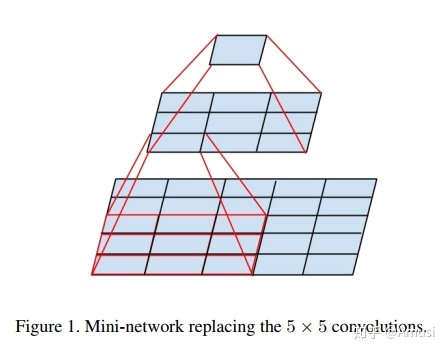
小卷积核减少了参数;而且3x3卷积核有利于更好地保持图像性质。
- VGG16包含了16个隐藏层(13个卷积层和3个全连接层)
- VGG19包含了19个隐藏层(16个卷积层和3个全连接层)
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
VGG优点
VGG缺点
在计算机视觉里,特征的“等级”随增网络深度的加深而变高,研究表明,网络的深度是实现好的效果的重要因素。然而梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。有一些方法可以弥补,如归一初始化,各层输入归一化,使得可以收敛的网络的深度提升为原来的十倍。然而,虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差。
resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是y=x的恒等映射。
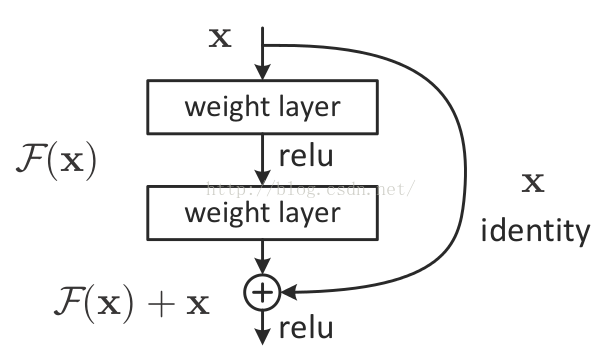

实验证明,这个残差块往往需要两层以上,单单一层的残差块(y=W1x+x)并不能起到提升作用。
还有一点,实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
残差网络是加上跳转链接,非线性映射关系:X(t)=H(X(t-1))+X(t-1)
ResNets的一个优点是,梯度可以直接通过恒等函数从后面的层流向前面的层。但是,恒等函数和H的输出是累加的,这可能会阻碍网络中的信息流。为了改善不同层之间信息流的的问题,DenseNet采用直接将所有输入连接到输出层。
与残差网络不同的是不用相加而是连接,输入直接传入到输出如图1,非线性映射关系:
X(t)=H([X0,X1,X2,...,X(t-1)])
稠密块:定义了输入输出之间的连接关系
过渡层:控制通道数
生长率(Growth rate)为几表示每个稠密层输出feature map维度是几。
为了确保layers之间的最大信息流,将所有的layers直接连接起来。
为了保持前馈特性,每个层的输入是所有前面层映射输出,也将自己的特征映射结果作为后面层的输入。
池化层:当特征大小改变时,连接操作不再适用。然而卷积层常在下采样提取特征时改变特征大小。池化层用在解决使用稠密块后带来通道数剧增,使用过多稠密块模型过于复杂的问题。
各个版本:DenseNet-B在原始DenseNet的基础上,加入Bottleneck layers, 主要是在Dense Block模块中加入了1*1卷积,使得将每一个layer输入的feature map都降为到4k的维度,大大的减少了计算量。DenseNet-BC在DenseNet-B的基础上,在transitionlayer模块中加入了压缩率θ参数,论文中将θ设置为0.5,这样通过1*1卷积,将上一个Dense Block模块的输出feature map维度减少一半。
梯度消失经常出现,一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid,梯度爆炸一般出现在深层网络和权值初始化值太大的情况下。解决方案是:尽量缩短前层和后层之间的连接。
残差网络Highway Networks通过旁路信息将上一层信息直接传递给下一层。随机深度网络,随机dropping layers分型网络,多条短路径相连接。
加强特征传播
每一层都可以直接从损失函数和原始输入信号中获取梯度,从而实现隐含的深度监控
鼓励特征重用
前向传递中每经过一层传递信息都将改变,ResNet利用相加保留了这部分信息。随着近几年研究表明许多层贡献很小,可以在训练中随机删去某些层。这使得ResNet有些像RNN,但是ResNet的参数很大,因为每层都需要自己的权重。
DenseNet明确区分了添加到网络中的信息(改变的信息)和被保护的信息(重用的信息)。
DenseNet层是非常窄的(例如,每层12个过滤器),只在网络的集合知识中添加一小部分feature-maps,并保持其余的feature-maps不变,最终的分类器根据网络中的所有feature-maps做出决策。
大幅度减少参数数量:
网络比较窄,参数少,其feature maps=4k,k是生长率,一般比较小。
不需要学习冗余的特征映射。
有正则化,可以在小数据集上减少过拟合,文中解释为参数减少的原因。
获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(每一层卷积核数或者神经元数),但是这里一般设计思路的情况下会出现如下的缺陷:
1.参数太多,若训练数据集有限,容易过拟合;
2.网络越大计算复杂度越大,难以应用;
3.网络越深,梯度越往后穿越容易消失,难以优化模型。
解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差。
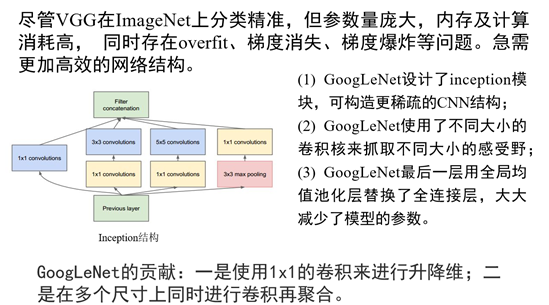
搬运来自:https://blog.csdn.net/yaochunchu/article/details/95526388,讲的很清楚
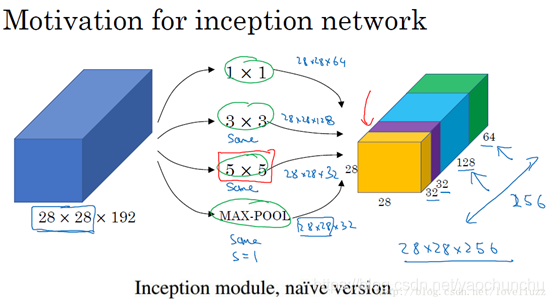
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野(1×1,3×3,5×5),最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1*1、3*3和5*5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
4 . 网络在越靠前时,感受野越小,关注到的越细节(汽车的细节纹理),所以根本看不出来特征是什么。越到后面特征越抽象,且每个特征涉及的感受野也更大(车轮,车身),所以越到后面越能看清特征是什么东西。随着层数的增加,3x3和5x5卷积的比例也要增加。
Inception的作用:代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数,采用哪些过滤器组合。
naive版本的Inception网络的缺陷:计算成本。使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。为减少计算成本,采用1x1卷积核来进行降维。
googlenet的主要思想就是围绕这两个思路去做的:
(1).深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2).宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,
但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
图见连接:
对上图做如下说明:
(1)显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
(2)网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
(5)上述的GoogLeNet的版本成它使用的Inception V1结构。
标签:计算资源 利用 网络模型 模糊 改进 不容易 oss bsp 感受
原文地址:https://www.cnblogs.com/cn-gzb/p/14344189.html