标签:不同的 int lazy 字符 get 一点 slides name 大小
TensorFlow优化器及用法
函数在一阶导数为零的地方达到其最大值和最小值。梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降。
在回归中,使用梯度下降来优化损失函数并获得系数。本文将介绍如何使用 TensorFlow 的梯度下降优化器及其变体。
按照损失函数的负梯度成比例地对系数(W 和 b)进行更新。根据训练样本的大小,有三种梯度下降的变体:
首先确定想用的优化器。TensorFlow提供了各种各样的优化器:
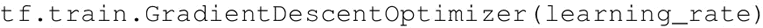


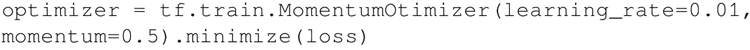

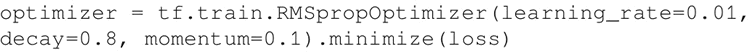
Adadelta 和 RMSprop 之间的细微不同可参考 http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf 和 https://arxiv.org/pdf/1212.5701.pdf。
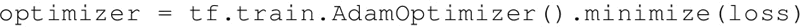

通常建议从较大学习率开始,并在学习过程中将其降低。这有助于对训练进行微调。可以使用 TensorFlow 中的 tf.train.exponential_decay 方法来实现这一点。
根据 TensorFlow 文档,在训练模型时,通常建议在训练过程中降低学习率。该函数利用指数衰减函数初始化学习率。需要一个 global_step 值来计算衰减的学习率。可以传递一个在每个训练步骤中递增的
TensorFlow 变量。函数返回衰减的学习率。
变量:
实现指数衰减学习率的代码如下:

标签:不同的 int lazy 字符 get 一点 slides name 大小
原文地址:https://www.cnblogs.com/wujianming-110117/p/14347929.html