标签:服务器 http 可扩展性 目标 方式 多个 redis 集群 压力 安装
现存的问题:
使用集群的方式可以快速解决上述问题
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果 ,数据分开存放, 组成一组数据的整体,对外体现整体
集群作用
分散单台服务器的访问压力,实现负载均衡
分散单台服务器的存储压力,实现可扩展性
降低单台服务器宕机带来的业务灾难
数据存储设计
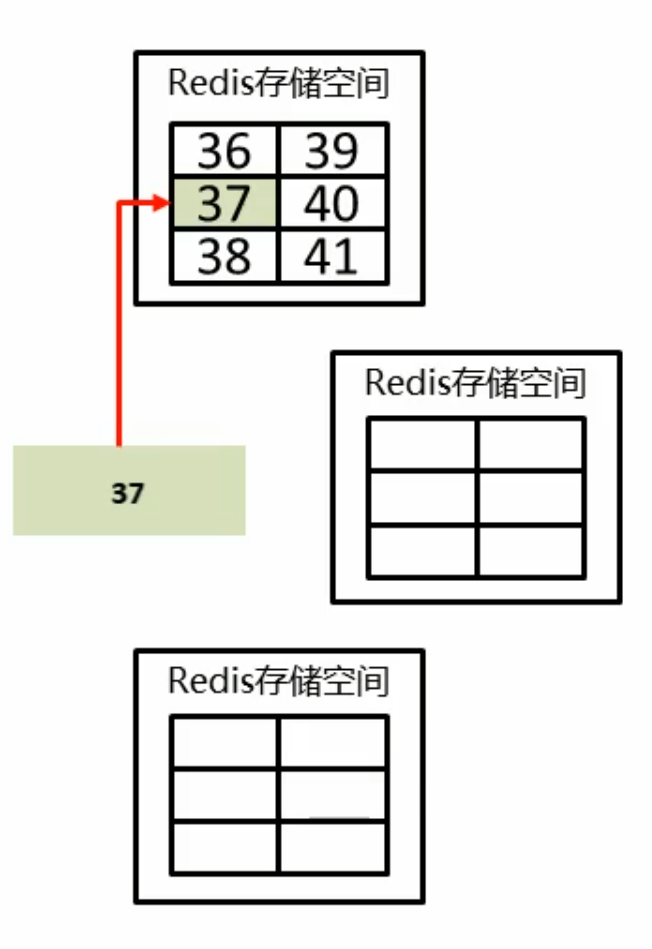
例如如下的示意图中,此时key计算出的值为37,即放到集群中上面的这台机子中
集群体系的可扩展性:
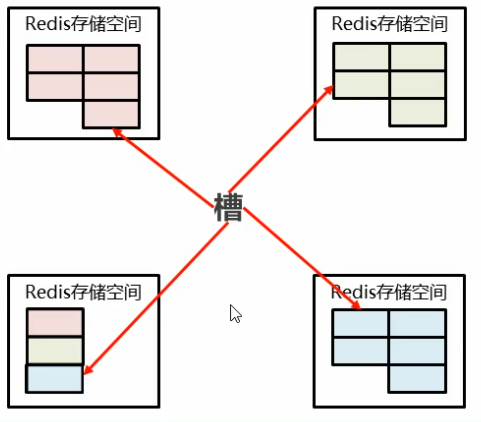
上面说到,Redis集群将整体数据 分成16384份, 每个集群的节点,都保存一部分的数据,但是此时,若需要再加一台机子,或者减去一台, 将对Redis集群中的数据进行重新分配
如下示意图:
当增加机器时,会将现存集群的节点各取若干份槽,交由 新的机器保存,保存数据的对等,
若减去时,也是一样,将自己的数据平分给剩下的机器
集群的内部通讯
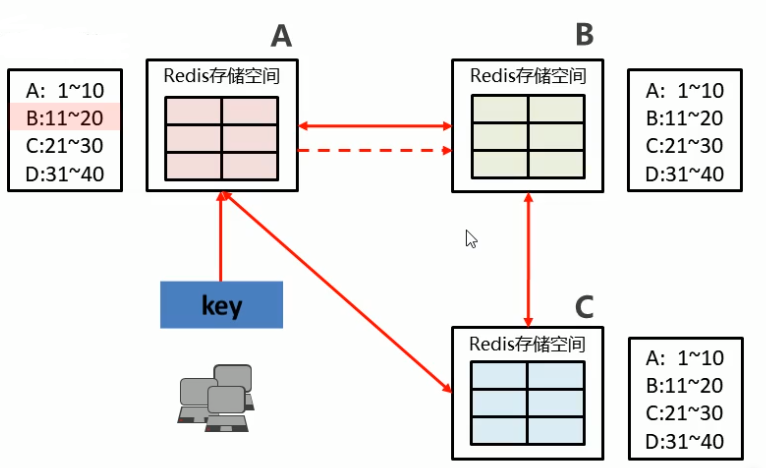
集群的内部也保持通讯,因为 集群内部有可能会因为节点的增加减少发生数据转移,
所以集群中的各个节点,都实时记录着其他节点所存储的槽区域,
当有一个key 计算出,在本机器操作时, 若直接命中,即可进行操作
若没有命中,则本机器将在记录的其他节点的区域中寻找,并将结果返回给客户端,客户端重新连接新的目标
所以最多进行两次连接
如下示意图:
介绍 Redis cluster 搭建过程,集群为三主三从 ,使用同台服务器,多个配置文件的方式
配置文件如下:
port 6379
daemonize yes
***
//除了常规的配置,还需配置如下三个项
//启用集群模式
cluster-enabled yes
//cluster配置文件名,该文件自动生成指定位置
cluster-config-file /var/redis/nodes-6379.conf
//节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout 10000
将此配置文件复制六份,端口依次递增修改, 使用命令redis-server redis6379.conf启动服务,并指定对应的配置文件,如下,六个节点则全部启动成功

但是 Redis 集群并没有搭建完成,此时这些实例都不知道其他实例的存在,都是孤立的并没有形成一个集群。也没有形成主从,
在Redis 5 之前,可以使用Redis自带的集群管理工具redis-trib.rb 操作集群,默认在Redis目录下的src下
在5之后,将不支持只能使用使用redis-cli连接,并使用cluster 指令操作,可以自行百度学习,
此例中使用redis-trib.rb ,但因该工具是用ruby开发的,所以需要准备相关的依赖环境。
# 准备redis-trib.rb的运行环境
wget https://cache.ruby-lang.org/pub/ruby/2.5/ruby-2.5.1.tar.gz
yum -y install zlib-devel
tar xvf ruby-2.5.1.tar.gz
cd ruby-2.5.1/
./configure -prefix=/usr/local/ruby
make
make install
cd /usr/local/ruby/
cp bin/ruby /usr/local/bin
cp bin/gem /usr/local/bin
# 安装rubygem redis依赖
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install -l redis-3.3.0.gem
使用redis-trib.rb 操作集群
指定集群主从结构
//此命令表示创建主从结构, 1代表,一个master 带一个 slave, 那此时六个节点,就是三主三从
// 会自动将后面指定的 ip进行划分, 若为1的话,则表示前三个为 主,后三个为从
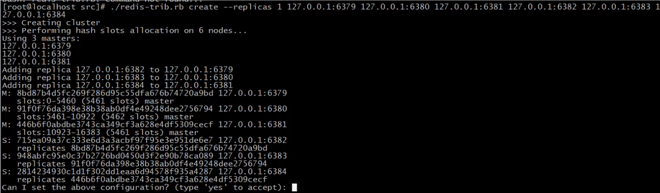
./redis-trib.rb create --replicas 1
127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
执行返回结果如下, 表示 6379,6380,6381,为master,和其对应的slave,并且还显示了各个主所划分的槽区域,
输入yes,开始划分
待执行完毕后, 再查看各个节点的自动生成的配置文件,可以看出, 都记录了自己和其他各个节点的分配的槽信息

存放获取数据测试
当我们像往常一样,使用 redis-cli 连接master 节点,并执行 命令 set name xjw 时,将会发生错误

因为此时计算出, key为 5789, 应该放在6380下面,如果没有对应上,将会发生错误
此时我们可以使用 redis-cli -c的方式,进行连接,这时,即使cli没有连接上应该存放的目标地址,也会自动的将值set到对应的位置,返回信息如下,自动重定向到了 6380

get数据也是一样,同样使用-c 的方式获取slave中的数据,自动重定向到目标地址
在上述的集群中,若此时 某个slave下线,将会被master标记,此时slave不可用,对整体没有什么影响
若 master掉线, 对应的slave节点,将会进行重连,重复cluster-node-timeout 次,一秒一次,若超过设定的超时时间, 此时此slave将晋升为master 节点,
若后来原先的master节点重新上线后, 将变成slave节点,连接新的master的节点,并同步数据
标签:服务器 http 可扩展性 目标 方式 多个 redis 集群 压力 安装
原文地址:https://www.cnblogs.com/xjwhaha/p/14364939.html