标签:距离 基于 递归 细节 残差 否则 区分 速度 vertica
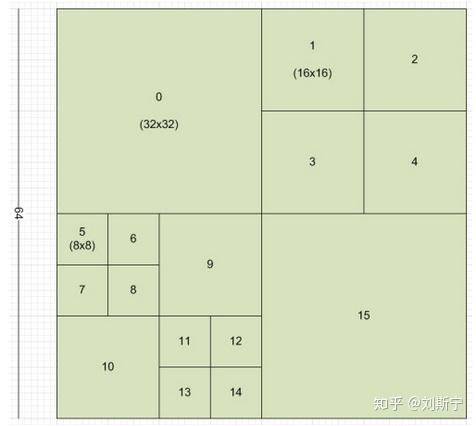
H.265将图像划分为“树编码单元(coding tree units, CTU)”,而不是像H.264那样的16×16的宏块。根据不同的编码设置,树编码块的尺寸可以被设置为64×64或有限的32×32或16×16。很多研究都展示出更大的树编码块可以提供更高的压缩效率(同样也需要更高的编码速度)。每个树编码块可以被递归分割,利用四叉树结构,分割为32×32、16×16、8×8的子区域,下图就是一个64×64树编码块的分区示例。每个图像进一步被区分为特殊的树编码块组,称之为切割(Slices)和拼贴(Tiles)。编码树单元是H.264的基本编码单位,如同H.264的宏块。编码树单元可向下分成编码单元(Coding Unit,CU)、预测单元(Prediction Unit,PU)及转换单元(Transform Unit,TU)。
每个编码树单元内包含1个亮度与2个色度编码树块,以及记录额外信息的语法元素。一般来说影片大多是以YUV 4:2:0色彩采样进行压缩,因此以16 x 16的编码树单元为例,其中会包含1个16 x 16的亮度编码树区块,以及2个8 x 8的色度编码树区块。
编码单元是H.265基本的预测单元。通常,较小的编码单元被用在细节区域(例如边界等),而较大的编码单元被用在可预测的平面区域。
实线为编码单元,虚线为转换单元。
CTU是H.265/高效率视讯编码(High Efficiency Video Coding, HEVC)的处理单元。此处理单元类似H.264/高阶视讯编码(Advanced Video Coding, AVC)中的宏区块(Macroblock)。编码树单元的大小可以从16x16到64x64,使用比H.264更大的处理单元得到更好的压缩效果
单元(Unit)与区块(Block)
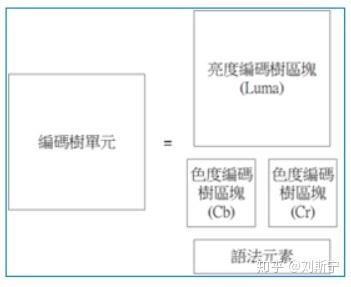
区块是真正储存资料的地方,许多区块加上语法元素组成一个单元。输入影像采用YUV的格式,所以一个编码树单元是由一个亮度(Luma)编码树区块(Coding Tree Block,CTB)、两个色度(Chroma)编码树区块及语法元素(Syntax Element)组成。
由于输入影像采用4:2:0的取样方式,因此亮度编码树区块的大小为色度编码树区块的四倍,如图一所示。
 图一 CTU = Syntax(CTB_Y, CTB_Cb, CTB_Cr)
图一 CTU = Syntax(CTB_Y, CTB_Cb, CTB_Cr)
编码树单元与AVC的宏区块最大的不同之为编码树单元可以变得更大且大小可以调整,而宏区块的大小固定为16。HEVC的编码树单元支援更大的大小可以让编码器对高分辨率的影像编码时更有效率。编码树单元的大小定义在序列参数集(Sequence Parameter Set, SPS)内,高效率视讯编码内支援的大小为LxL,其中L=16、32或64。
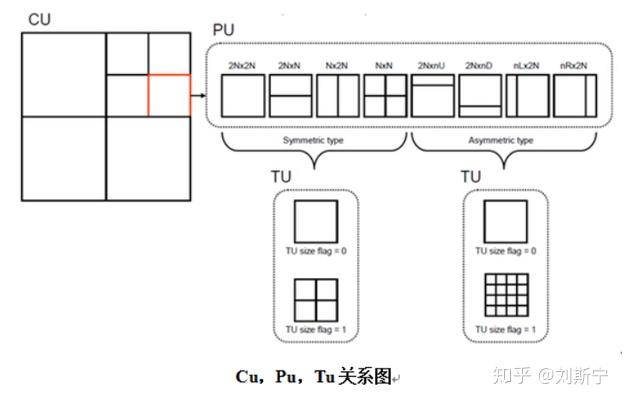
除了编码树单元,高效率视讯编码(HEVC)中还有另外三种单元分别为编码单元(Coding Unit, CU)、预测单元(Prediction Unit, PU)及转换单元(Transform Unit, TU)。
编码单元 CU 是码树 CT 结构上的一个叶子 Leaf Node.
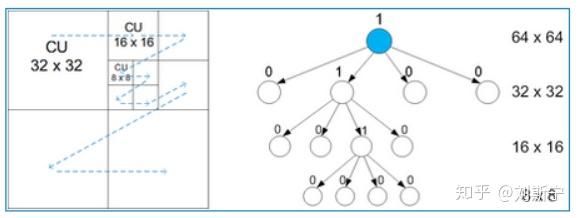
码树单元(CTU)可以包含有一个编码单元(Coding Unit, CU)或是切割成多个较小的编码单元,如图二(左)所示。
 图二
图二
高效率视讯编码 (HEVC) 用编码单元 CU 指示这个单元是属于画面内预测(Intra Prediction)或是画面间预测(Inter Prediction)。
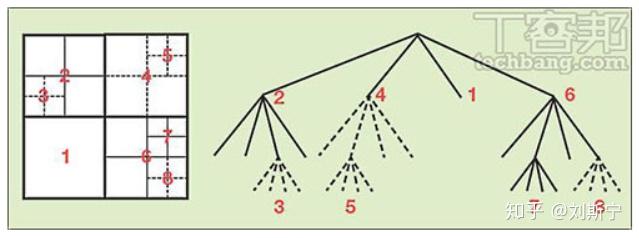
这些编码单元CU可以很方便地利用四分树(Quadtree)的方式呈现,如图二(右)所示。
四分树是一种递回结构,四分数上的数字表示这个节点是否继续做分割,若此节点会继续分割则为1,若不继续分割则为0。由图二可看出节点上的数字为0时,此节点为编码单元。换句话说,在编码树内叶子节点(Leaf Node)为编码单元。编码树的顺序如图三左的虚线所示,在编码单元上采用Z-scan的方式,对编码树来说即为深度优先遍历。
编码单元CU的大小支援2Nx2N,其中N=4、8、16或32,因此高效率视讯编码(HEVC)的四分树最高深度(Depth)为4。
对于YUV=420的彩色视频:一个CU由一个CB_luma samples、2个CB_choma samples和相关的语法元素。
CU = Syntax(CB_Y, CB_Cb, CB_Cr)
一个Luma CB是2^N x 2^N(此处的N与CTU中的N大小不同)的像素区域,而相应的choma CB是2^(N-1) x 2^(N-1)的像素区域,
N的值同样在编码器中确定,并在SPS中传输。
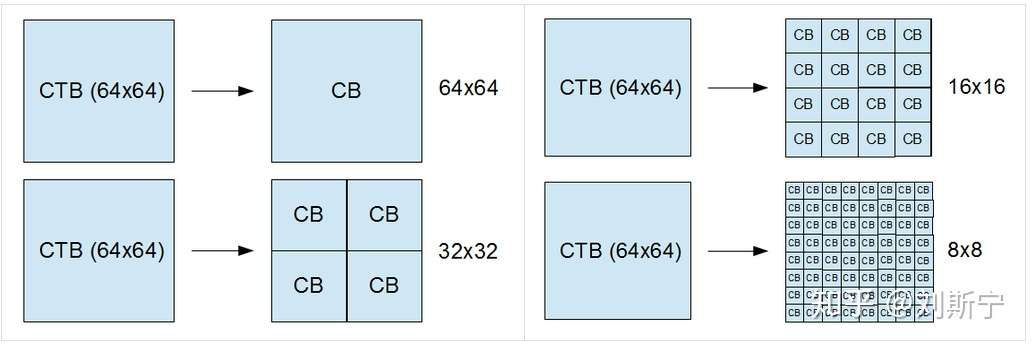
CB是之前已经分割好的CTB根据块中的图像内容而自适应划分的(划分规则:相对比较平坦的区域采用大尺寸的CB,而细节多的区域则采用较小尺寸的CB)。
通常情况下,CB的形状是正方形,亮度分量CB的尺寸可以由8x8大小到亮度CTB的大小,色度CB的尺寸可以由4x4大小到色度CTB的大小(也就是说,亮度CTB的尺寸是亮度CB的最大可支持的尺寸;色度CTB的尺寸是色度CB的最大可支持的尺寸)。如下图所示。
CU可以分为两类:跳过型CU(Skipped CU)和普通CU。
通常,在图像的右边界和下边界,一些CTU可能会覆盖部分超出图像边界的区域,这时CTU四叉树会自动分割,减小CB尺寸,使整个CB刚好进入图像。
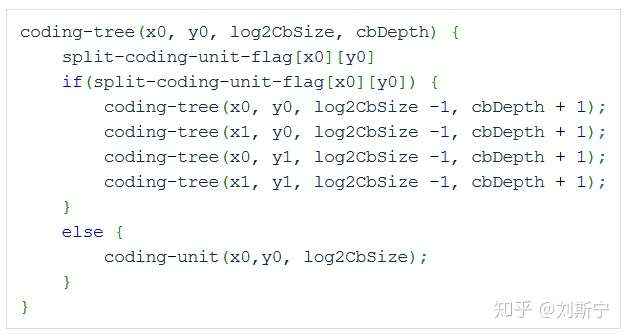
编码时,在CTU layer通过传输split_cu_flags标志指明CTU是否进一步划分成四个CU。
类似地,对于一个CU,也通过一个split_cu_flags标志指明是否进一步划分成子CU。
CU通过split_cu_flags标志指示进行递归的划分,直到split_cu_flags==0或者达到最小的CU尺寸(mininum CU size). 对于达到最小尺寸的CU,不需要传输split_cu_flags标志,
CU的最小尺寸参数(通过CTU深度确定)在编码器中确定,并在SPS中进行传输。
所以CU的大小范围是:minunum size CU ~CTU,一般情况设置CTU为64,最小CU为8(通过CTU深度确定),所以此时CU大小可取8、16、32、64。
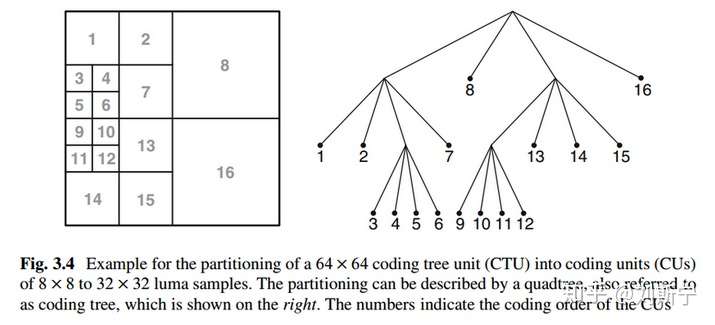
一个CTU进行编码时,是按照深度优先的顺序进行CU编码,类似于z-scan,如下图:右边表示CTU的递归四叉树划分,左边表示CTU中CU的编码顺序。
视频序列的分辨率(长和宽参数)也会在SPS中传输,要求长宽必须是mininum CU size的整数倍,但是可以不是 CTU size的整数倍。对于长宽不是CTU size整数倍的情况,图像边界处的CTU被认为已经分割成和图像边界重合(the CTUs at the borders are inferred to be split until the boundaries of the resulting blocks coincide with the picture boundary),对于这种边界处默认的分割,不需要传输split_cu_flags标志。
CU块是进行决策帧间、帧内、Skip/Merge模式的基本单元。
编码单元的简单语法

在转换和量化之前,首先是预测阶段(包括帧内预测和帧间预测)。一个编码单元CU可以使用以下八种预测模式中的一种进行预测。

HEVC在CU layer决定prediction mode,并将一个CU的prediction mode传输在bitstream中。
PU是是进行预测的基本单元,有一个PB_luma、2个PB_choma和相应的语法元素syntax element组成。
PU = Syntax(PB_Y, PB_Cb, PB_Cr)
一个编码单元(CU)可以根据预测模式的切割类型(Splitting Type)分割成一个、两个或是四个预测单元(Prediction Units, PUs)。
帧内编码的编码单元只能使用2N×2N或N×N的平方划分。帧间编码的编码单元可以使用平方和非对称的方式划分。
编码单元与预测单元的不同之处在于预测单元只能被切割一次,而且示基于编码单元做切割。预测单元是一个预测资讯的呈现区块,在一个预测单元内使用同预测方式(Prediction Process)。
高效率视讯编码 (HEVC) 依照不同的预测模式将编码单元CU分成三类,分别为以下三种,其分割方法如图三所示:
 图四
图四
略过的编码单元(Skipped CU):此为画面间编码单元的特例,意指移动向量差值(Motion Vector Difference)与残余能量(residual energy)皆为零。略过的编码单元内只允许2Nx2N的方式。
如果一个CU的prediction mode是intra prediction
对于luma CU
有35个可选的帧内预测方向
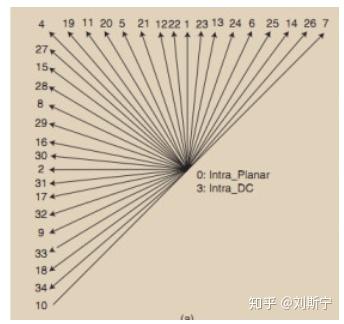
对于mininum size的luma CB,可以平均划分成4个方形的subblocks,对于每个subblock进行独立的帧内预测,有独立的intra prediction mode。
也就是说对于帧内预测的CU,可以进行2Nx2N和NxN两种PU划分模式,且NxN模式只有对mininum size CB可以使用。
帧内预测模式可以应用于4×4、8×8、16×16和32×32的变换单元。
一个帧内luma PU块,预测模式确定之后,需要对预测模式进行编码。
HEVC在进行帧内预测模式编码时,先为每个intra PU确定3个最可能模式(确定策略后面介绍),假设为S={M1,M2,M3}。
然后通过判断luma PU的帧内预测模式是否在S中,
最可能模式策略
对于luma PU,确定最可能3个预测模式是根据当前PU左边和上边的预测模式,假设左边和上边的预测模式分别是A和B,
确定好A和B之后:
当A=B时,如果A,B都大于2,即A和B都不是Planar或DC,那么:
M1=A;
M2=2+((A-2-1+32)%32)
M3=2+((A-2+1)%32)
当A=B时,如果A,B至少有一个小于2,即A或B是Planar或DC,那么:
M1=Planar,M2=DC,M3=26(竖直方向预测)
当A!=B时,M1=A,M2=B,对于M3按照下面规则决定:
如果A和B都不是Planar,那么M3=Planar;
如果A和B都不是DC,那么M3=DC;
否则,说明{A,B}={Planar,DC},那么M3=26。
对于choma CU
有5个可选的帧内预测方向
对于预测模式的编码,通过0表示luma PU的预测方向,100、111、101和110分别表示Planar/0、DC/1、Vertical/26和Horizontal/10。
另外,在进行帧内预测时,如果CU是mininum size CU,且将CU划分成4个PU时,那么要保证TU小于等于PU,如下图:
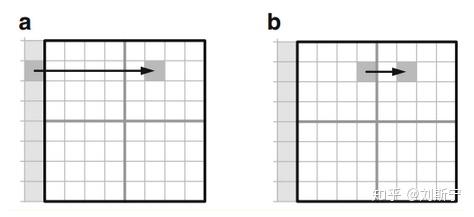
表示一个8x8的CU块分成4个PU,那么必须分成四个4x4的TU块,至于每个TU是否进一步划分成更小的TU不作限定,只根据正常TU划分的条件判断。这是为了提高intra预测的精确度。
图a表示如果CU不化成4个TU,那么intra预测的距离就会较远。
图b则表示了将CU划分成4个TU,这时候预测右边的小PU时,左边的PU已经预测完成,并进行了变换和重建,可以保证预测距离更近。
如果一个CU的prediction mode是inter prediction
针对运动向量预测,H.265有两个参考表:L0和L1。每一个都拥有16个参照项,但是唯一图片的最大数量是8。
H.265运动估计要比H.264更加复杂。它使用列表索引,有两个主要的预测模式:合并和高级运动向量(Merge and Advanced MV.)。
对于inter PU,luma PB和choma PBs拥有相同的PU划分模式和motion parameters(包括运动估计方向数目(1/2),参考帧索引,和对每个运动估计方向的运动矢量MV)。
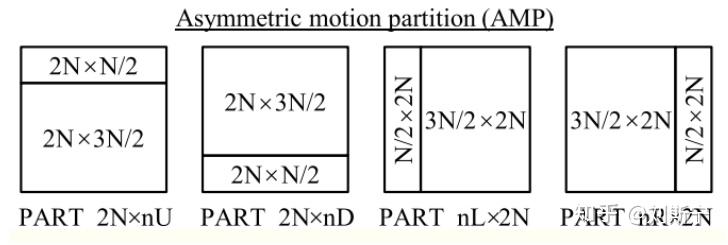
HEVC中有8中PU划分模式(2Nx2N、NxN、2个SMP和4个AMP),如下图所示:
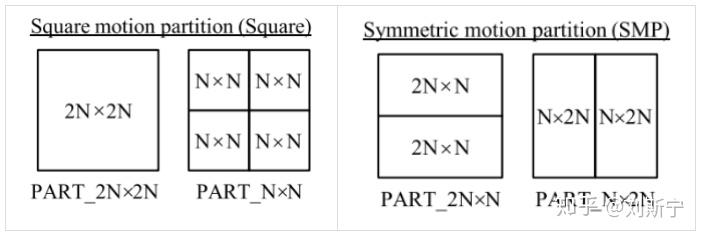
对于NxN模式,只有mininum size CU可以使用,且8x8CU不能使用。
对于AMP模式,只有32x32和16x16的CU可以使用,8x8和64x64的CU不能使用,所以inter PU的最小尺寸为8x4和4x8,这是因为TU最小尺寸为4x4,进行变换的最小单元也是4x4。另外,HEVC可以在SPS中通过一个syntax禁用AMP。
从H.262到HEVC过程中,PU的可选大小变化如下图:

如果一个CU的prediction mode是Skip
那么PU的划分模式只能是2N x 2N。
PS:对于4x8和8x4,HEVC规定只能用单向预测,不能用双向预测。
在HM1中,实际可以通过inter_4x4_enabled_flag(在SPS中)指示是否使用4x4的PU。
预测单元的切割在不同的预测模式有不同的限制,讨论如下:
转换单元是呈现残量(Residual)或是转换系数(Transform Coefficients)的区块,这个区块主要是做整数转换(Integer Transform)或是量化(Quantization)。[1][3]转换单元(Transform Unit, TU)与预测单元(PU)相似,因为编码单元可以只有一个转换单元或是由许多个较小的转换单元所组成。不同之处为转换单元可以递回地往下继续分割,也是用四分树(Quadtree)的方式储存,而预测单元只能在编码单元做分割一次。图五显示出编码单元与转换单元的关系,实线为编码单元,虚线为转换单元,虚线的四分树会长在实线四分树的叶子节点,这是因为只有实线四分树的叶子节点是编码单元。[1]转换单元内只有支援方形的分割方割(Square Partition),其大小为64、32、16、8、4。
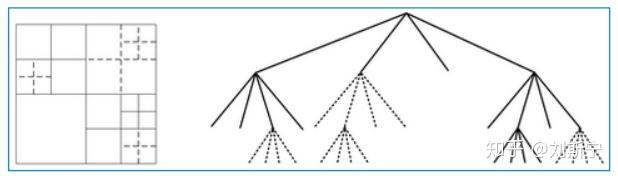 图五、编码单元与转换单元的关系,实线为编码单元,虚线为转换单元。
图五、编码单元与转换单元的关系,实线为编码单元,虚线为转换单元。
转换单元TU的编码树CT可以称为转换树(Transform Tree)或是残量四分树(Residual Quadtree, RQT)。
残量四分树可以分成两类,分别为方形残量四分树(Square Residual Quadtree, SRQT)或是非方形残量四分树(Nonsquare Residual Quadtree, NSRQT),
但是在最后的草案中非方形残量四分树(NSRQT)被移除掉。
图六为非方形残量四分树的切割方式。
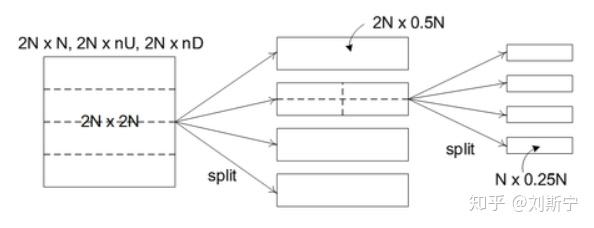 图六、非方形残量四分树的切割方式。
图六、非方形残量四分树的切割方式。
CU划分成TU中,TU的大小范围取决于max TU size、min TU size和max TU depth三个参数决定,这三个参数在SPS level进行传输。
对于intra predition,要确保PU大于等于TU(即TU不跨多个intra PU),而inter predition没有相应的限制。
另外,对于一个CU,最多有一个trasform tree syntax,所以一个CU的luma CB 和choma CBs拥有相同的TU划分。但是除了对于8x8的luma CB划分成4x4的TB时,4x4的choma CBs不会划分成2x2的TB。
在相同编码单元(CU)内的预测单元(PU)与转换单元(TU),转换单元的大小可以比预测单元的大小还要来的大,在同一个编码单元内不同预测单元的残量(Residuals)可以一起被转换。换句话说,当编码单元的大小等于转换单元的大小时,转换是对整个编码单元去做转换而不是对单一的预测单元一个一个做转换。而这种情况只会出现在画面间编码单元(Inter Coded CU)中,因为画面内编码单元(Intra Coded CU)总是会造成转换单元(TU)分割。
原文链接:https://zhuanlan.zhihu.com/p/67303770
标签:距离 基于 递归 细节 残差 否则 区分 速度 vertica
原文地址:https://www.cnblogs.com/sddai/p/14365572.html