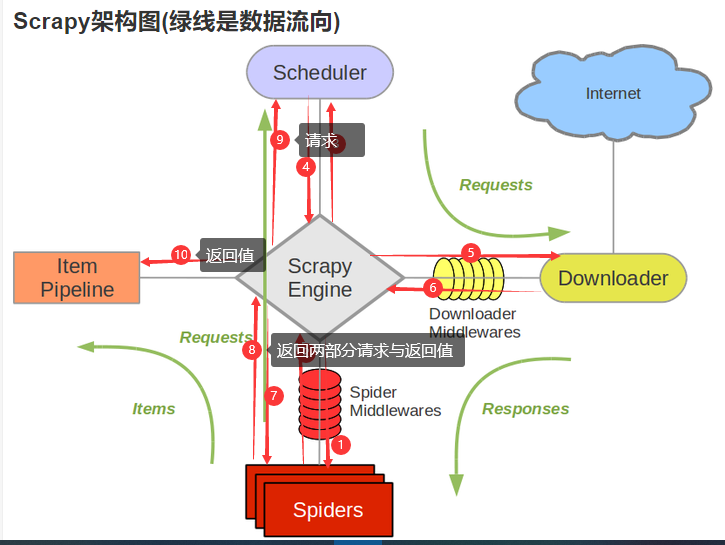
标签:info 载器 开始 中间件 load spi png xxx 入队
scrapy框架流程
原文地址:https://www.cnblogs.com/wbf980728/p/14366905.html