标签:mic top use 需要 性能测试 多少 als gbk group
------------恢复内容开始------------
------------恢复内容开始------------
------------恢复内容开始------------
------------恢复内容开始------------
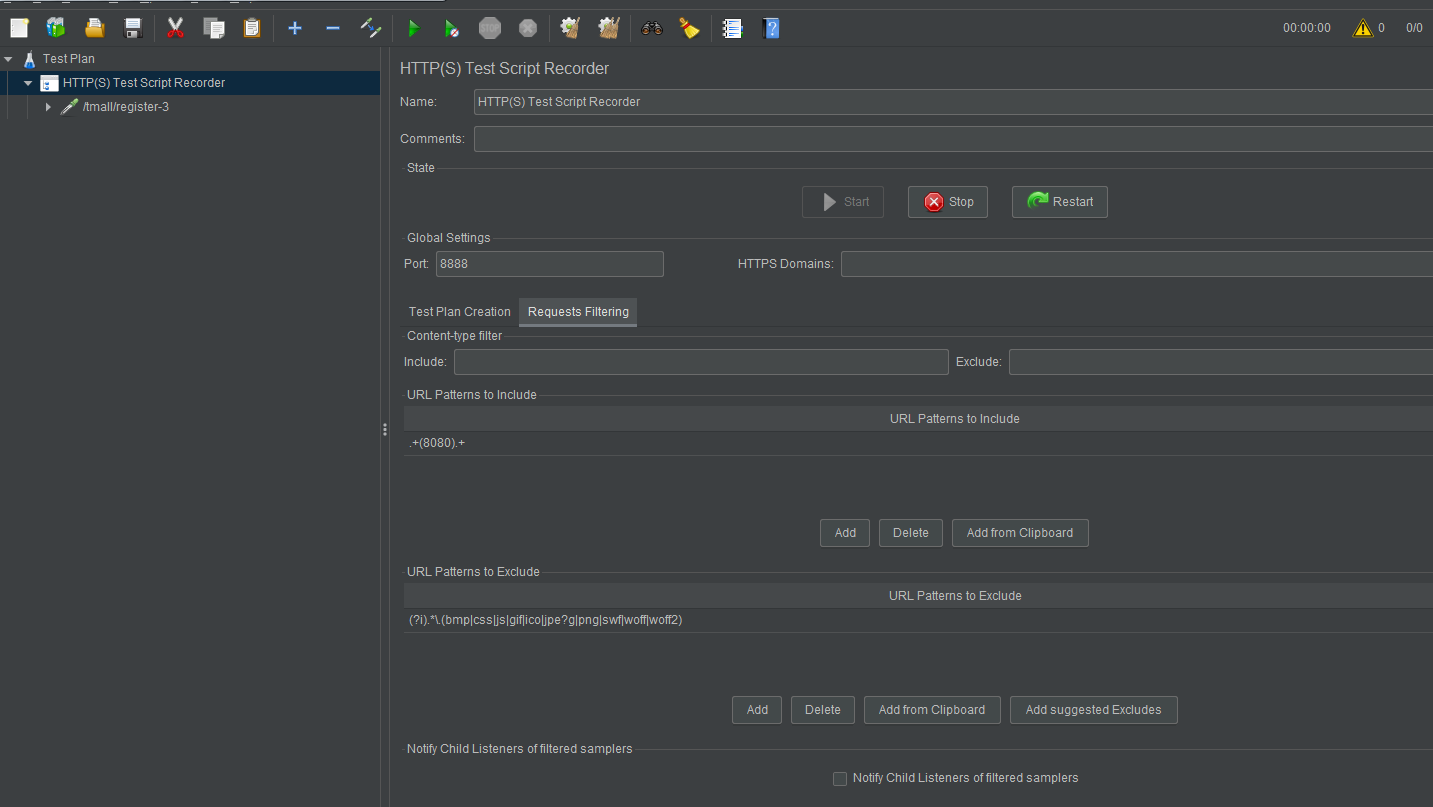
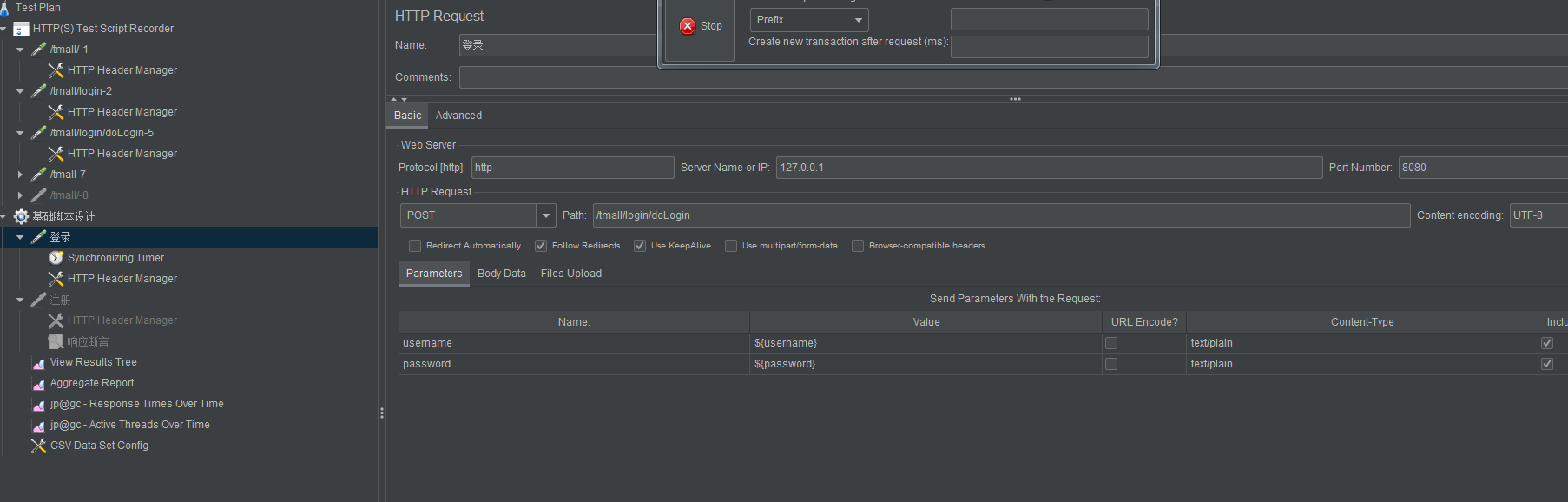
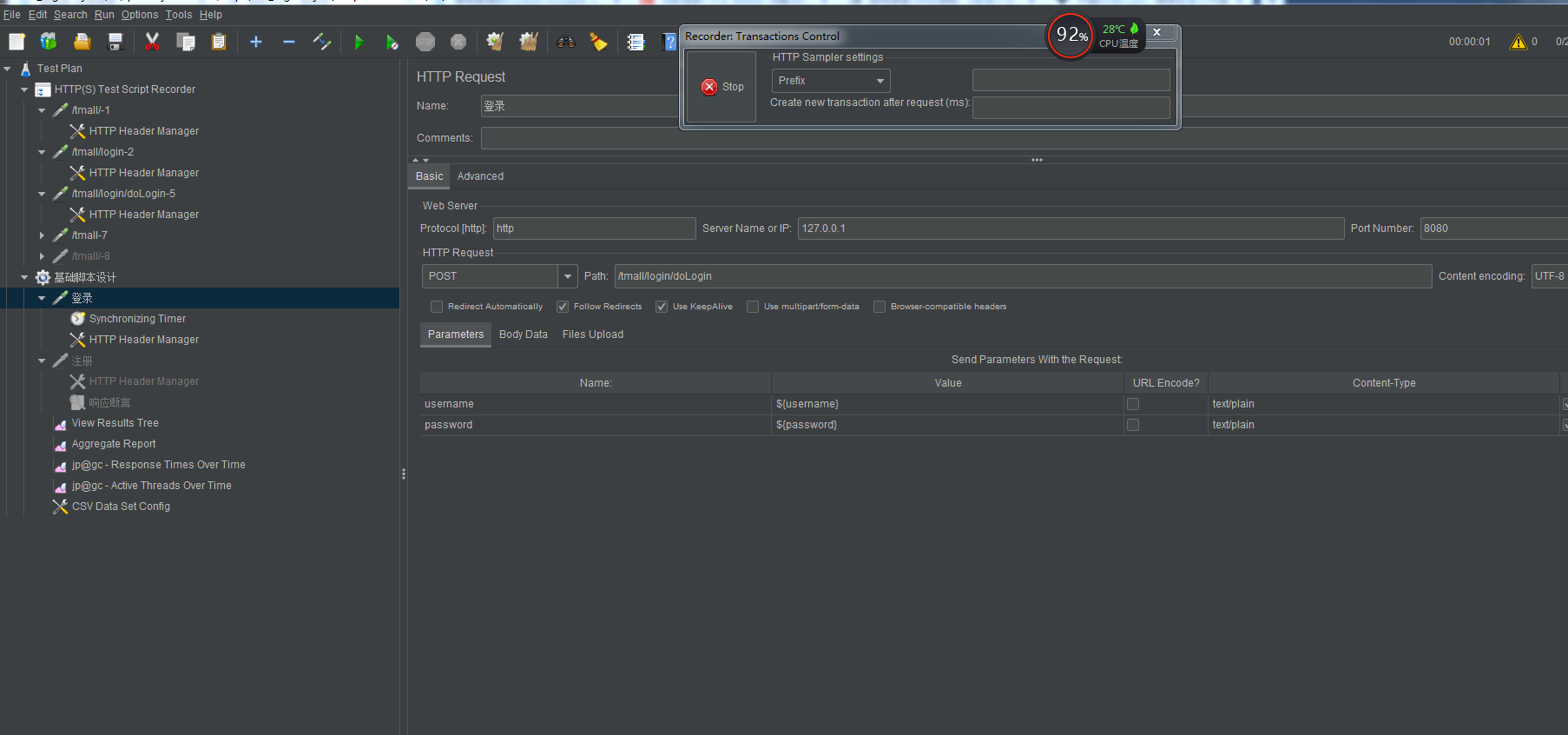
1.在选择Http(S) Test Script Recorder
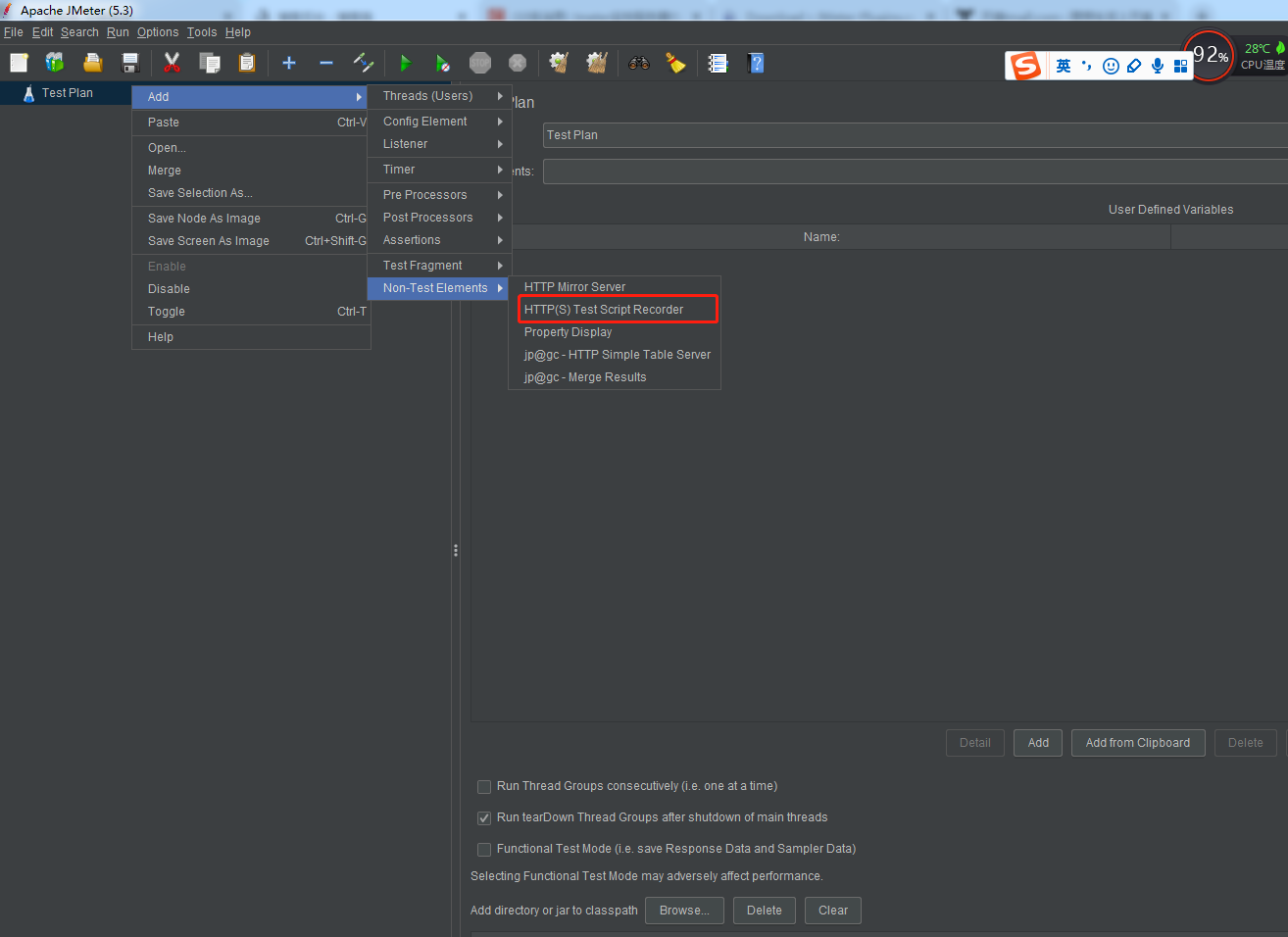
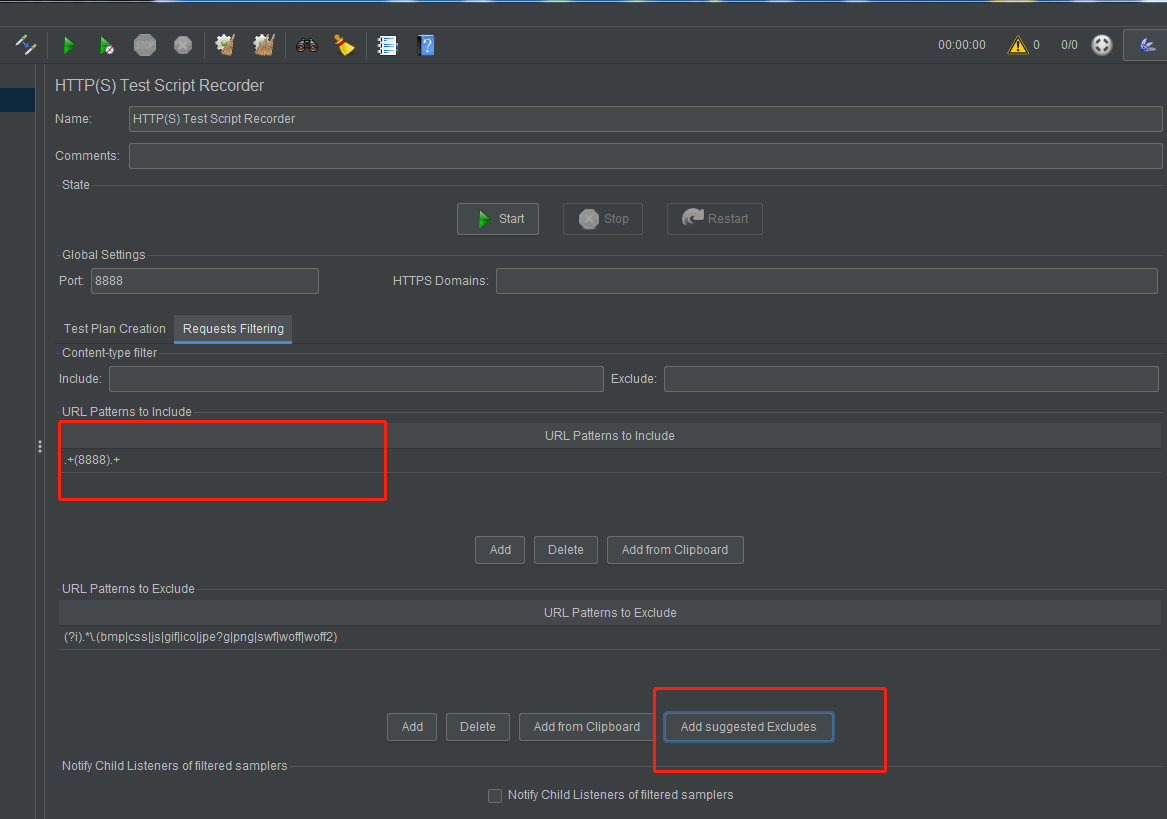
添加完成之后点击start 启动代理服务器
开始进行录制
性能测试报告中要注意数据的横向对比(优化前和优化后)和纵向对比。
启动抓包工具:
启动抓包工具并且输入对应需要抓包的页面,选择8888的这个选项:
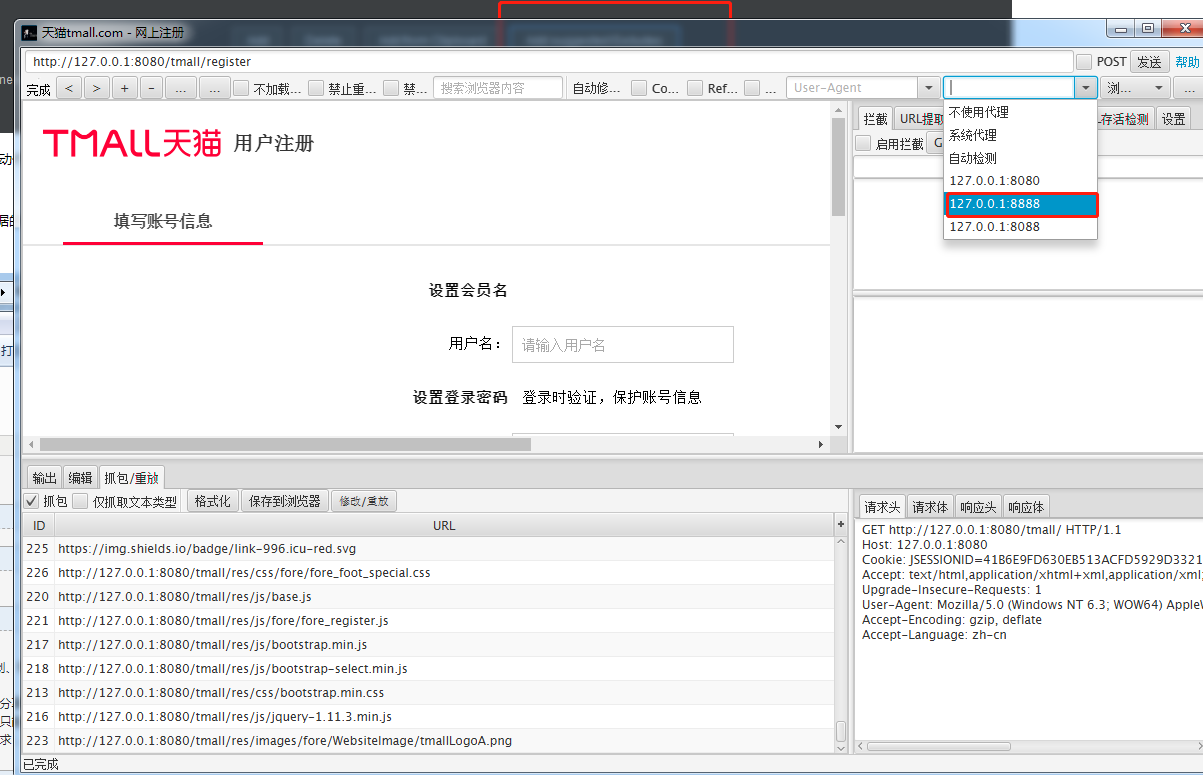
点击页面发送按钮。在jmster 这边对应的接口就录制到了。
录制到接口之后进行单接口的调式,
单接口可以正常访问了之后,可以进行并发场景的测试:
并发场景需要设置集合点:
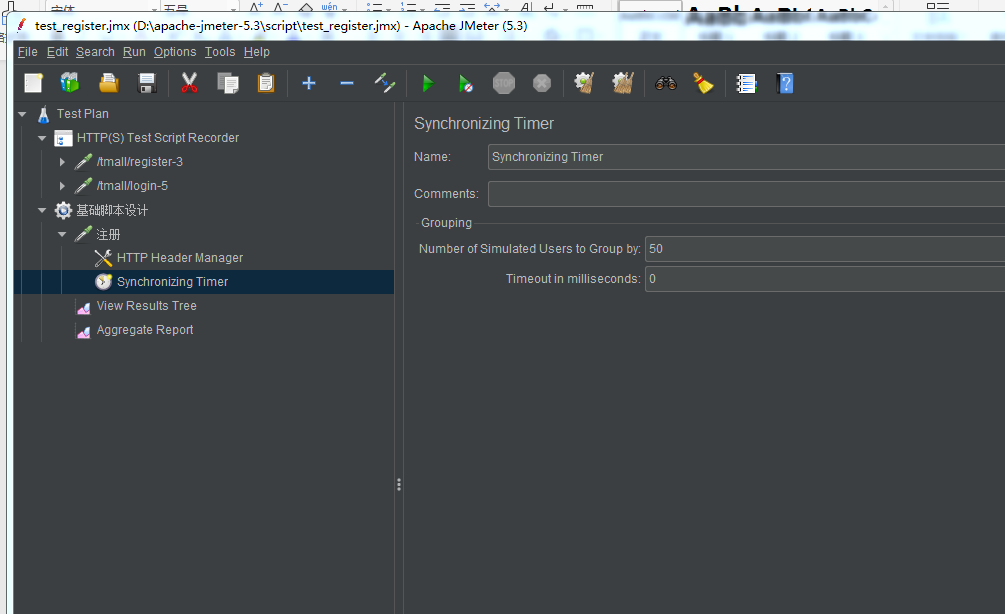
启动的线程数:
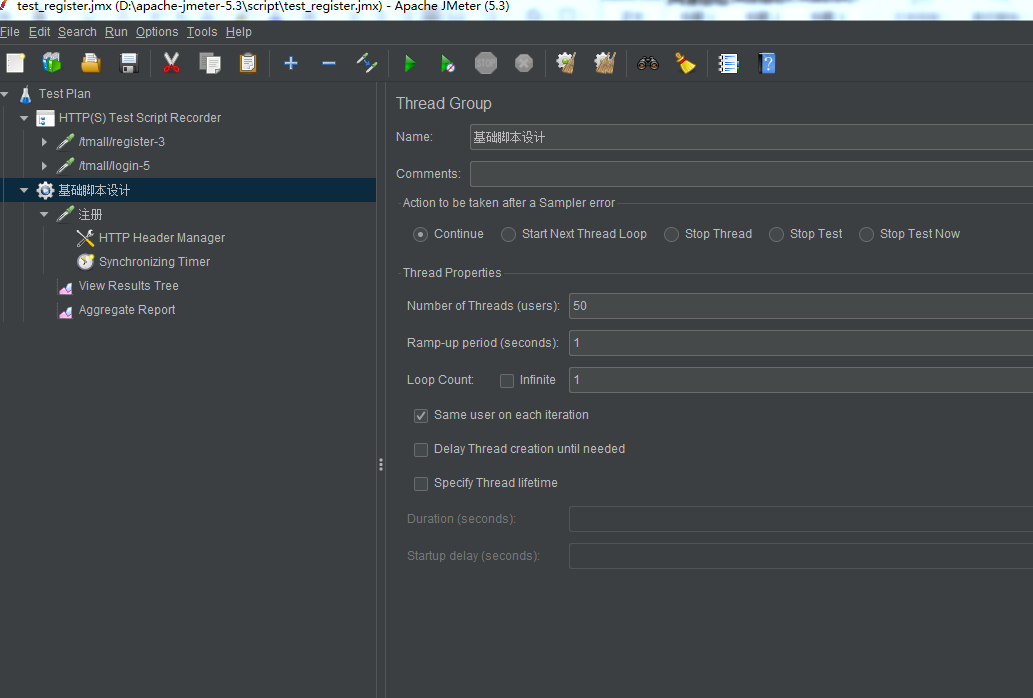
线程数需要大于等于集合点,集合点是需要集合线程数去发送请求,如果线程数低于集合点的线程数,集合点会一直等待线程满足集合点的数量,但是会一直不满足导致请求无法发出去。
Timeout in milliseconds:300 是隐式等待,我只等待300毫秒,在300毫秒以内无论我集合了多少线程,都会优先的并发发不去。(剩下的线程就不管了,就按照正常的逻辑去做?)
集合点总结:
集合点超时时间=0,固定等待,一定要线程数满足集合数,才会发起请求
结合点超时时间!=0 ,隐式等待,超时时间内,无论集合了多少线程都会优先并发
没有加集合点的数据:
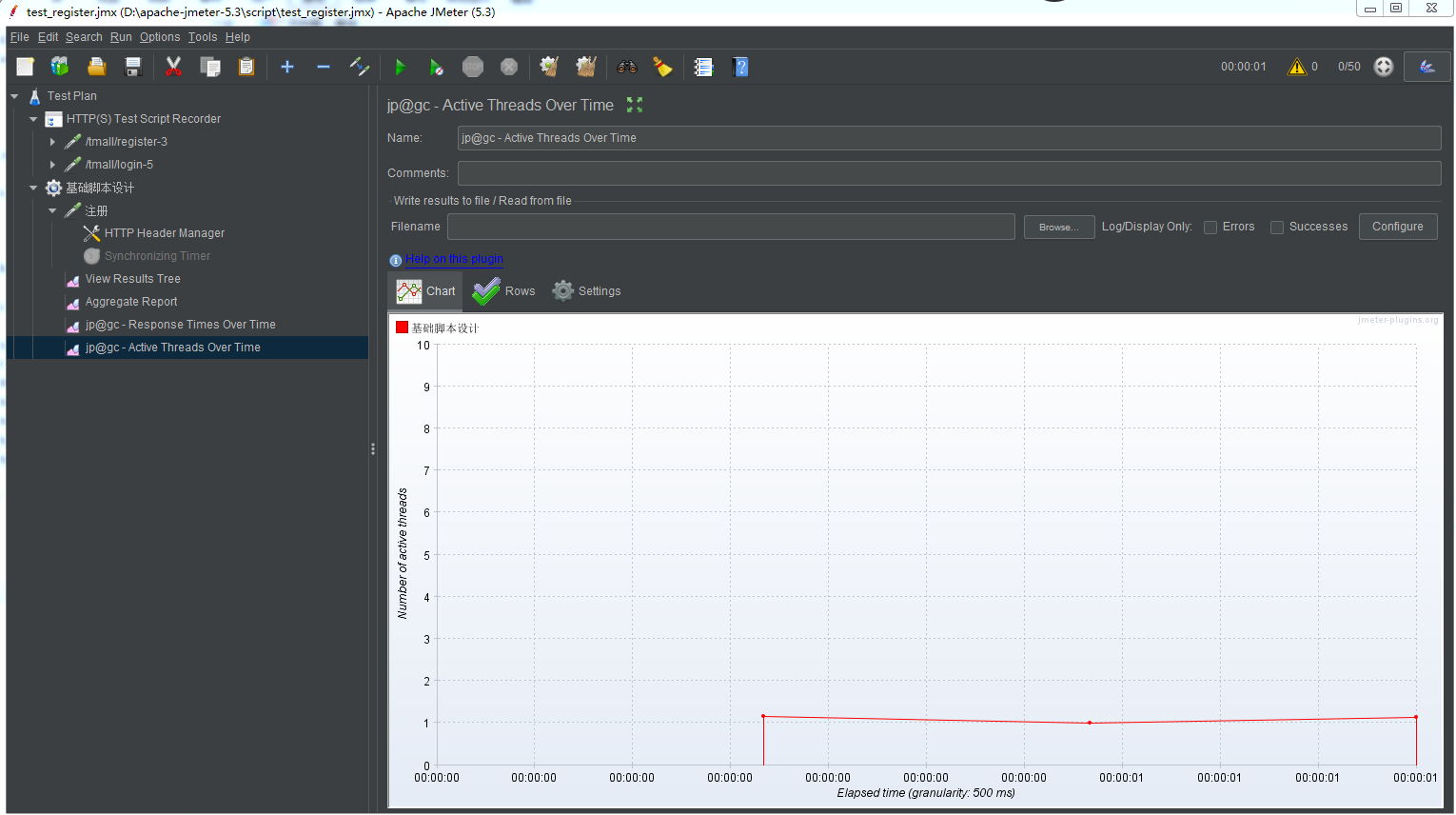
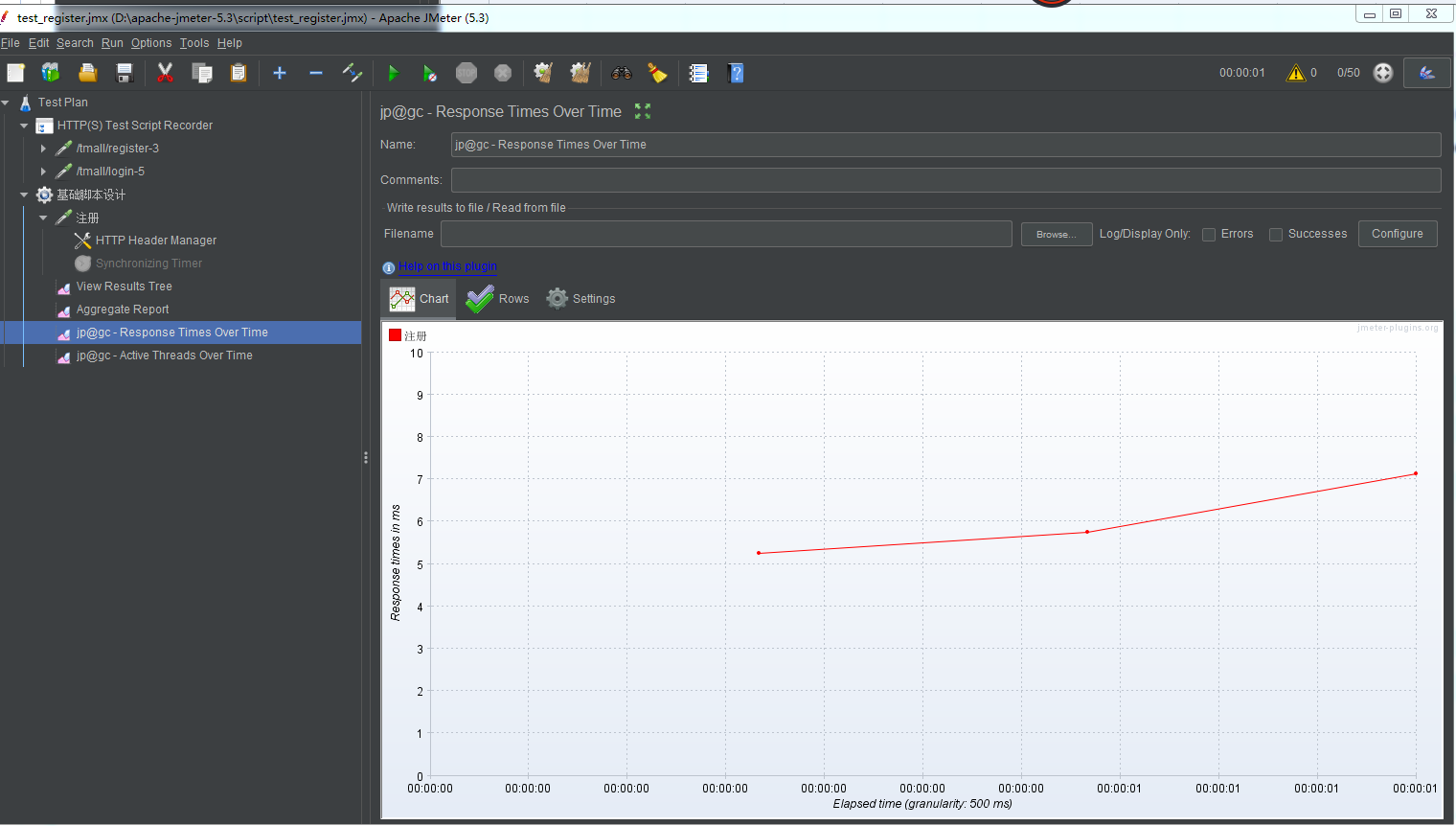
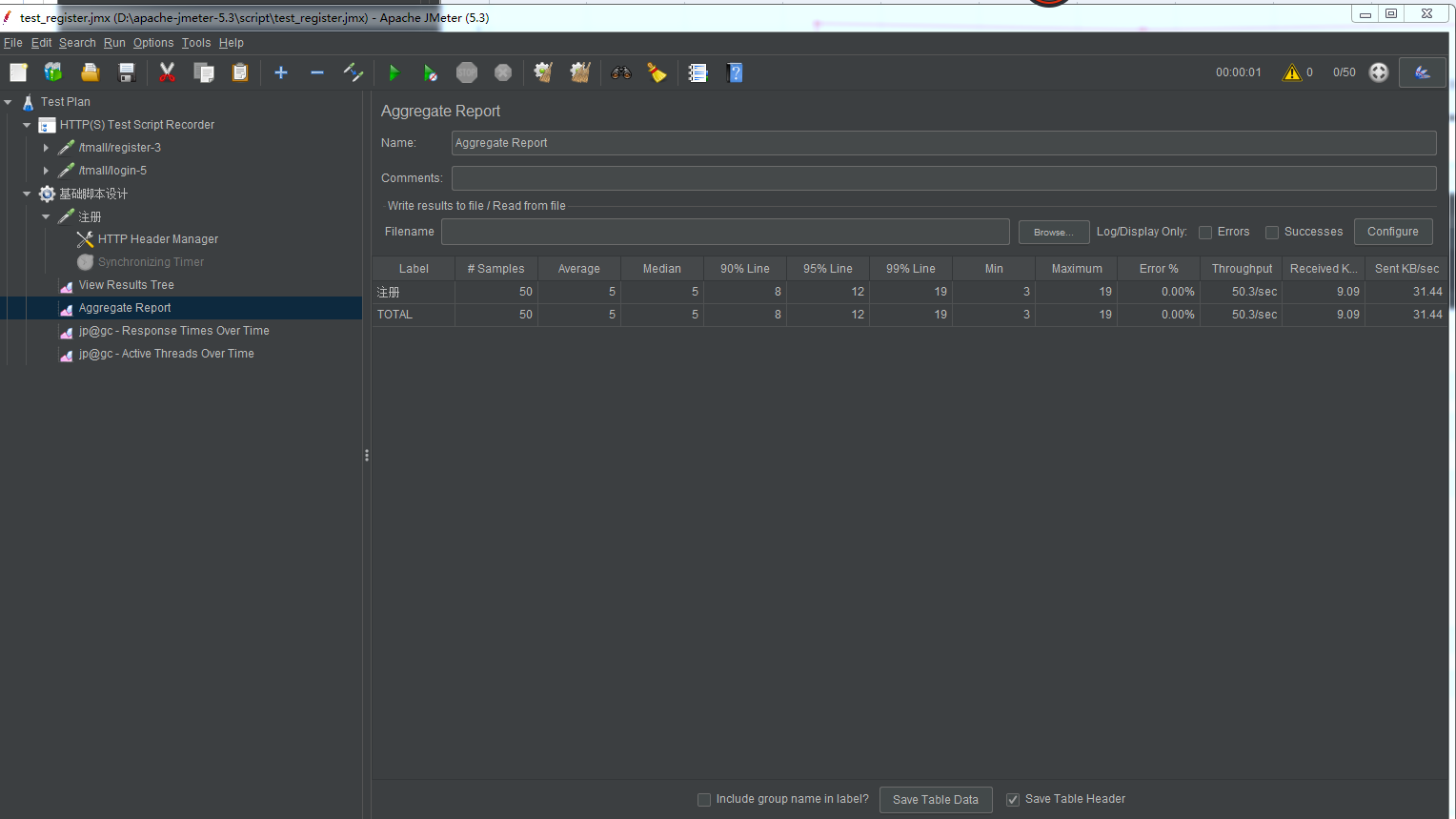
加了集合点的数据:
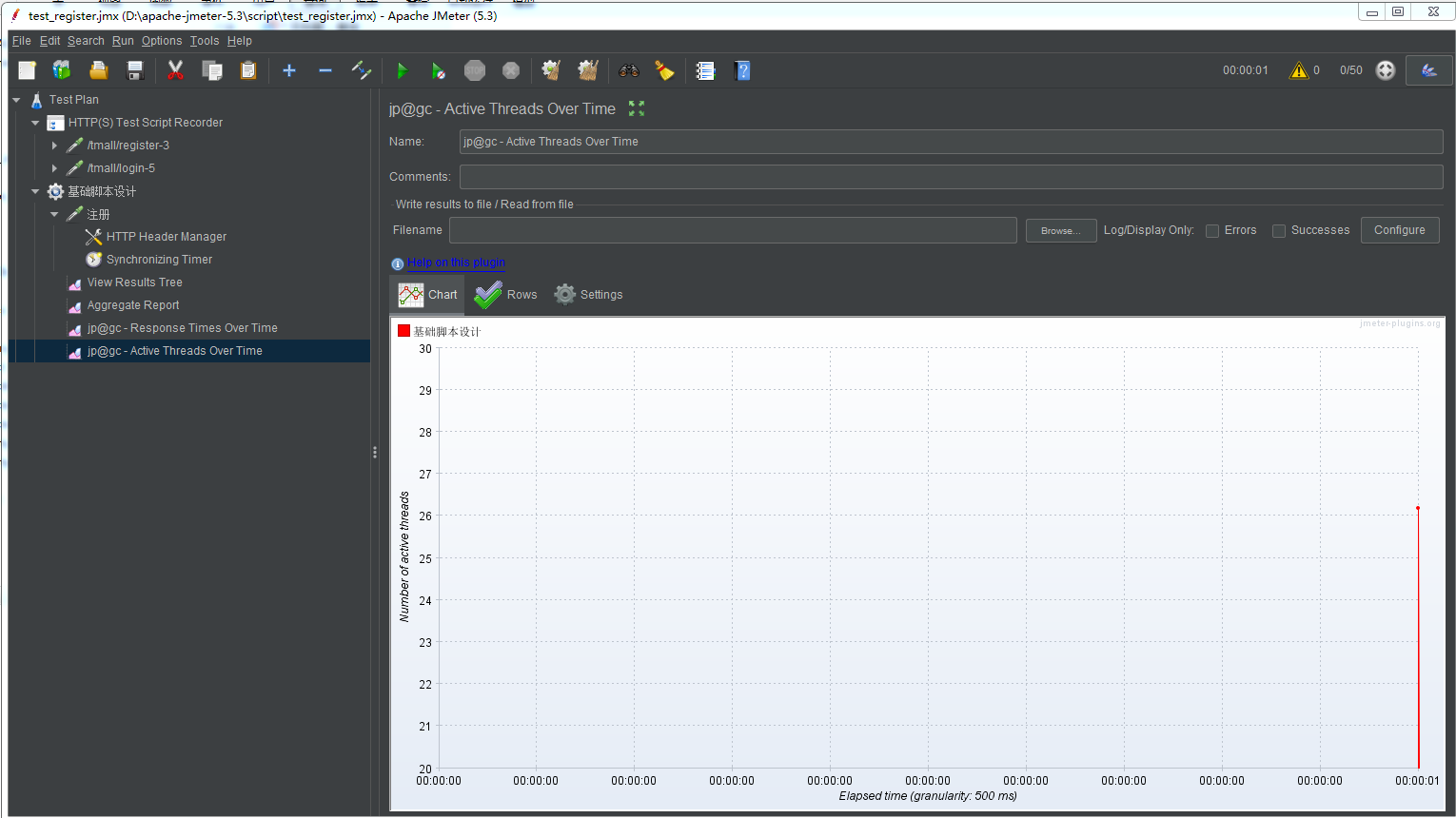
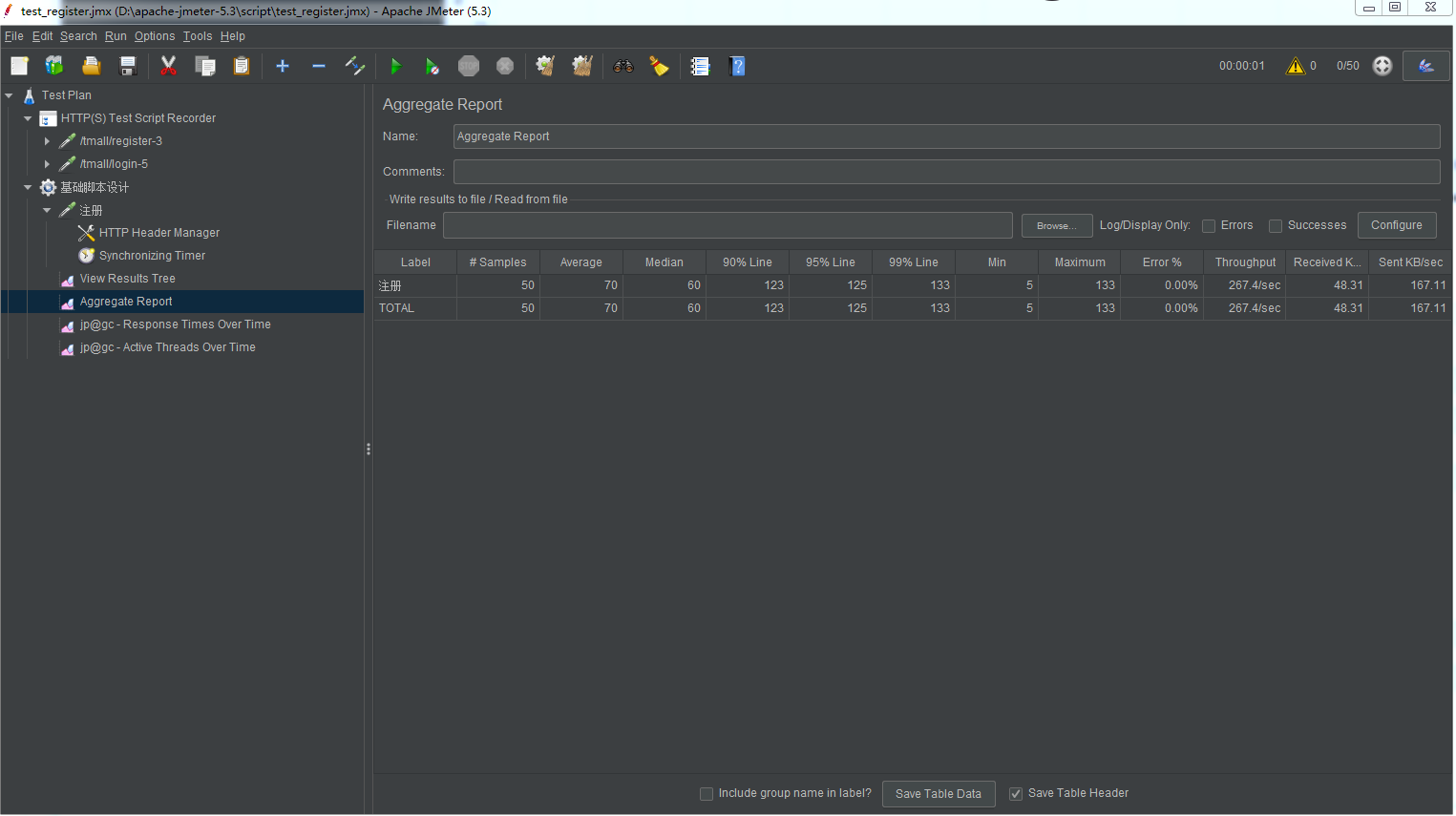
脚本参数化,1.种方式参数化,2计数器,3随机数。
1.随机数:
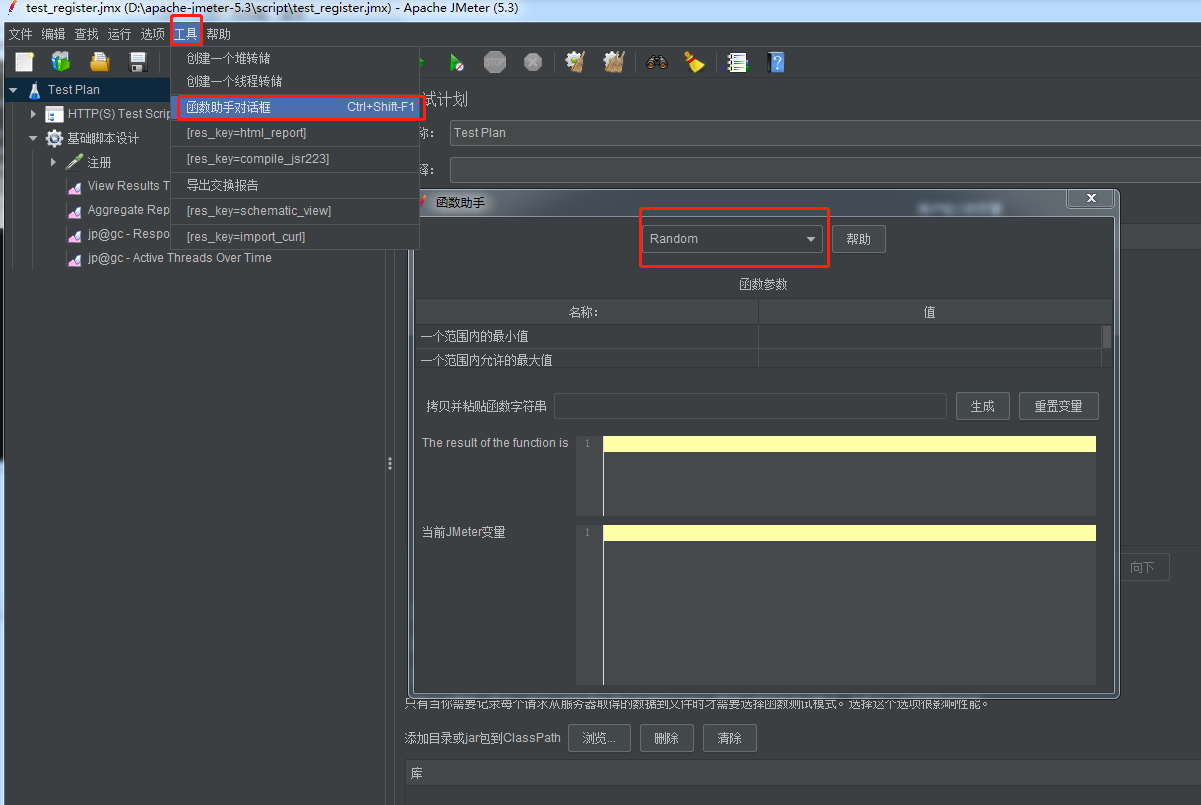
设置好了对应的最大值和最小值,点击生成按钮。如下图:
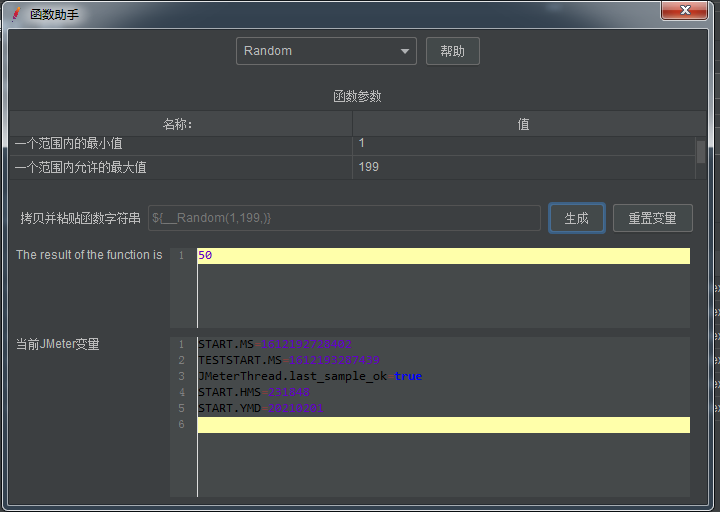
将函数变量赋值到对应的字符串旁边:
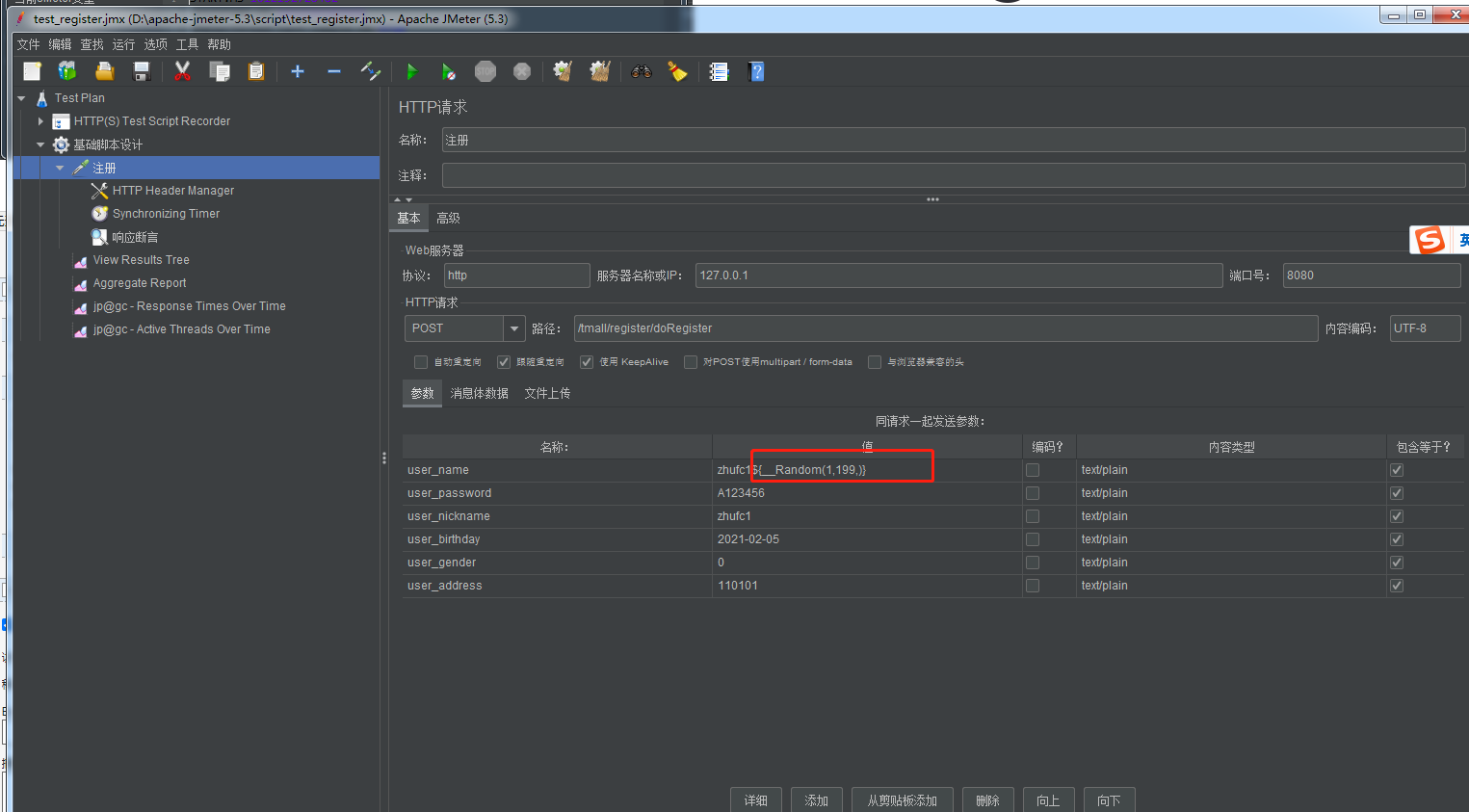
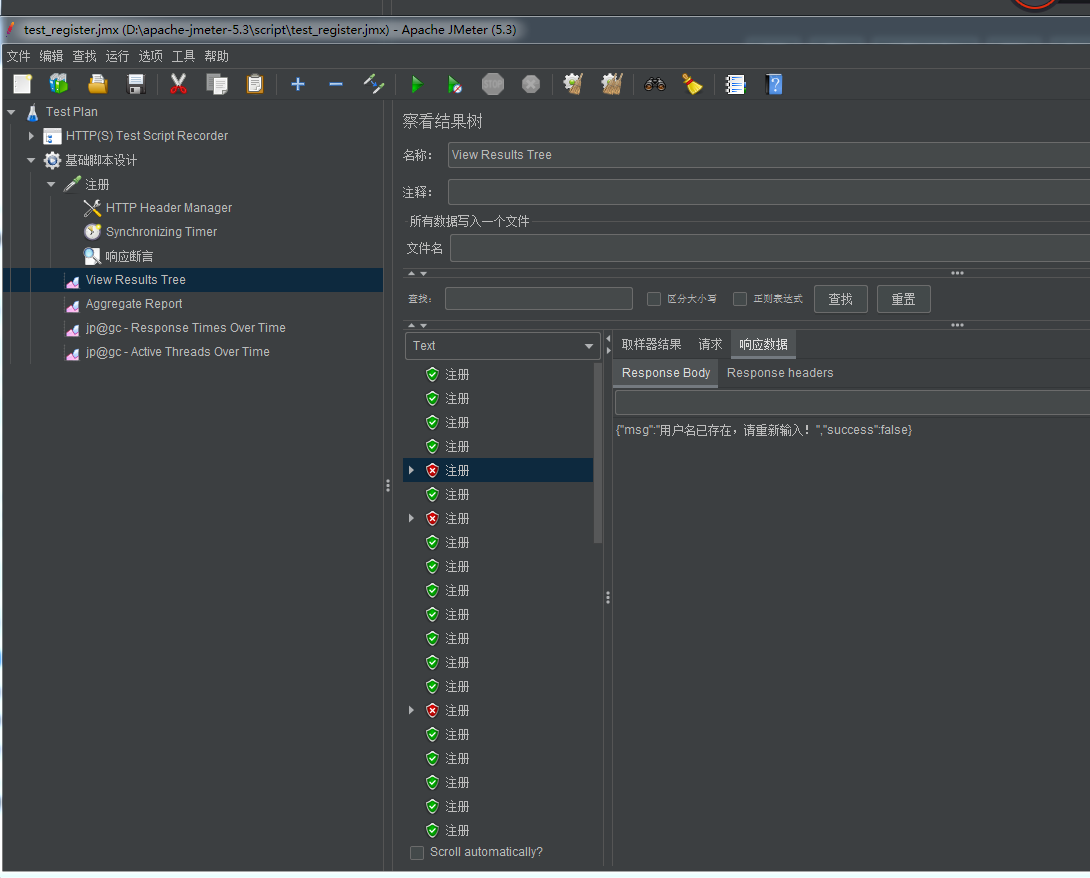
随机数从1-199,有随机重复的概率,所有会有部分请求是错误的,随机的范围越小,重复的概率越大。重复9999999的话重复的概率会小点:
2.计数器添加步骤:
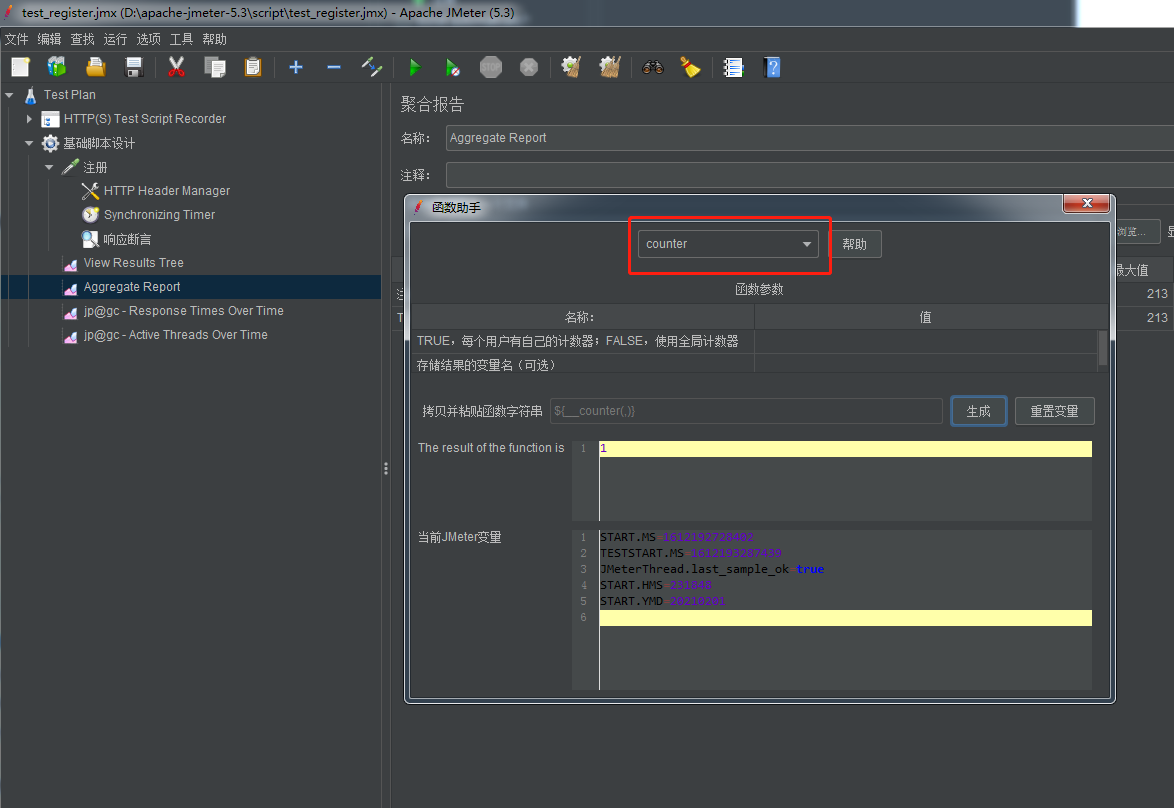
并放到字符串旁边:
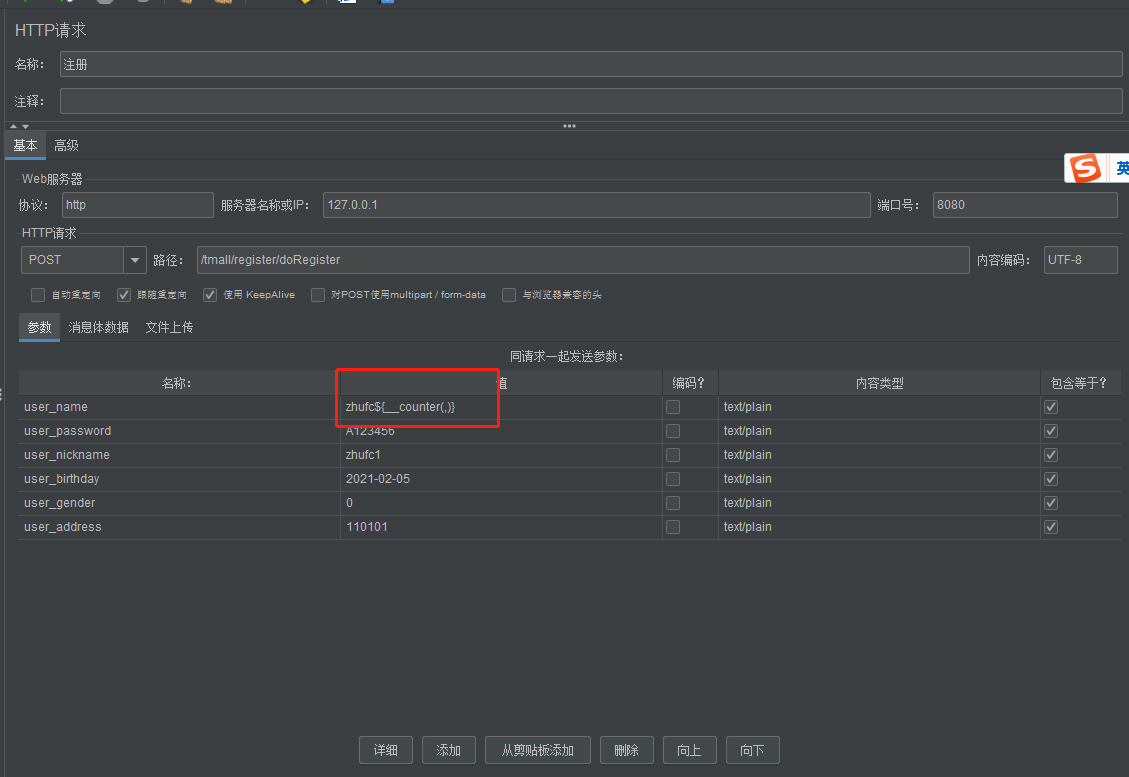
在保存csv文件的时候可以保存为utf-8的格式
txt 文件转csv
txt 编码改成utf-8
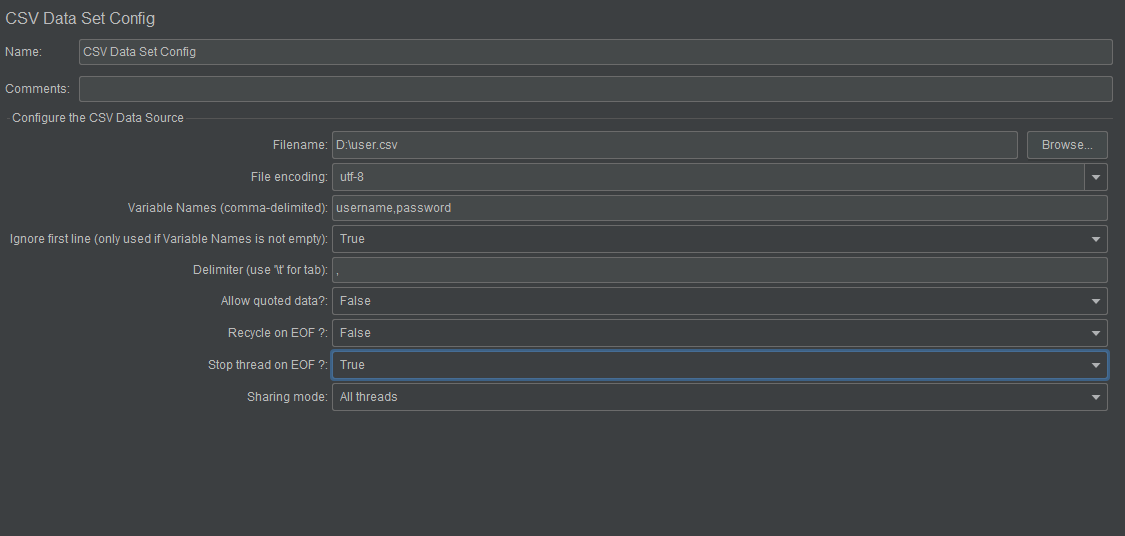
Filename:csv文件的名称
2)File encoding:csv文件编码
3)Variable Names(comma-delimited):
4)Delimiter(use “\t” for tab):csv文件中的分隔符(用”\t”代替tab键)
5)Allow quoted data?:是否允许数据内容加引号
6)Recycle on EOF?:
7)Stop thread on EOF?:
8)Sharing mode:共享模式
设置并发集合点去进行测试
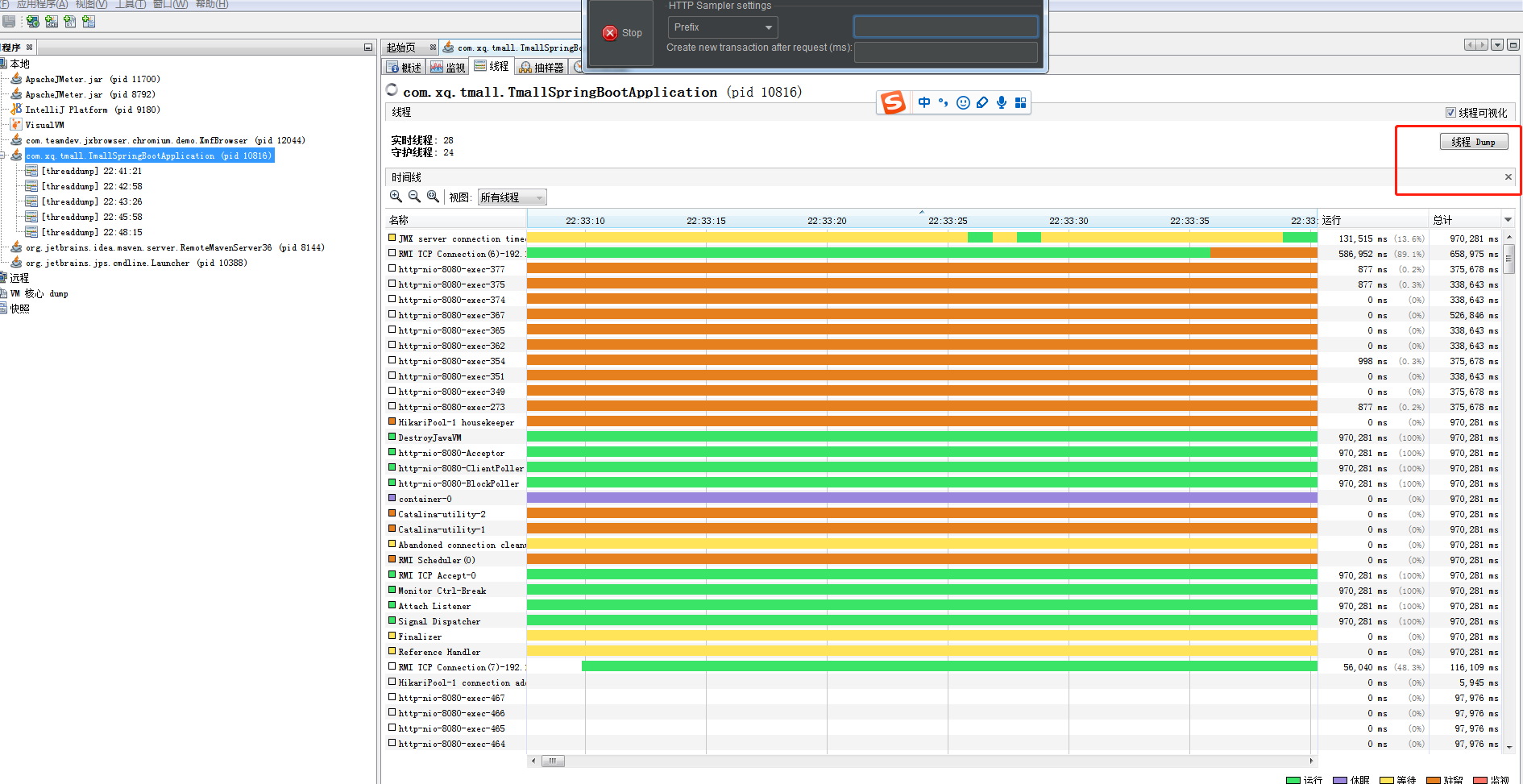
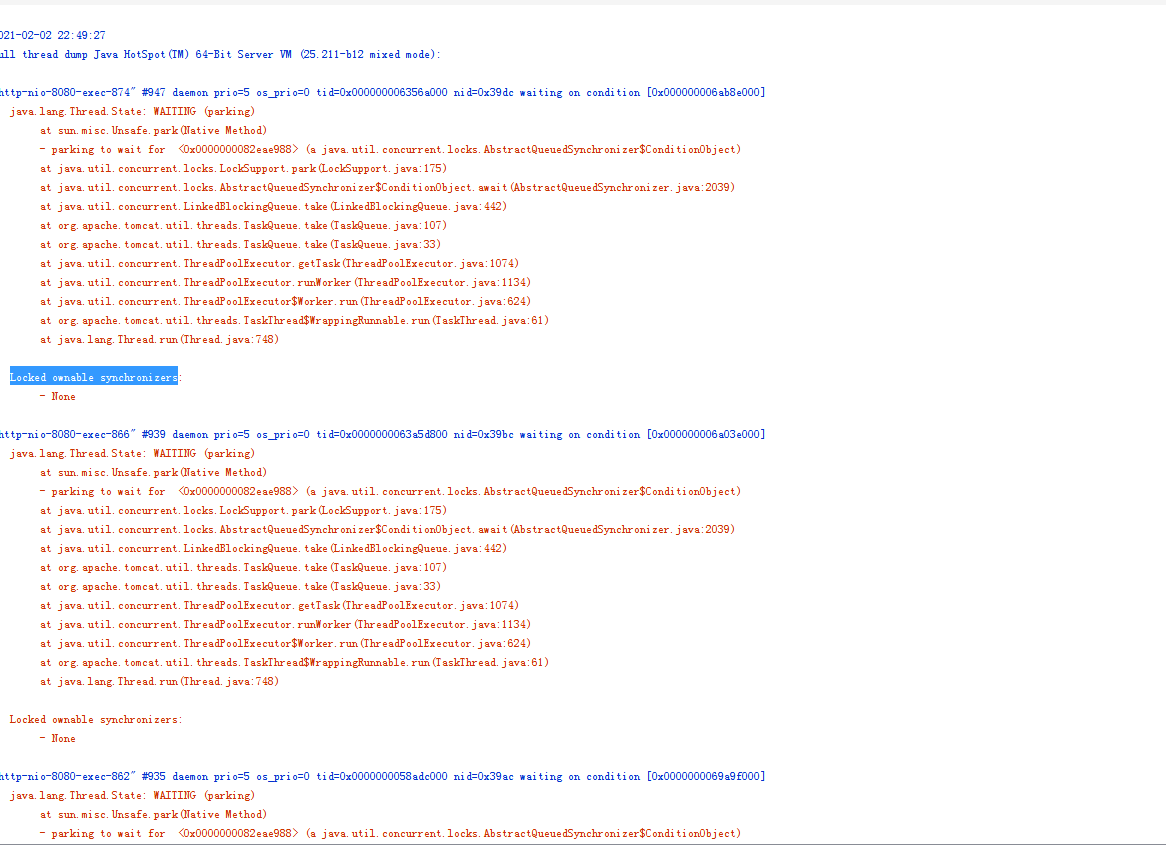
9 ) 在测试并发登录的时候监测到对应的tomcat 服务堆栈信息。如下图:
设置一个基准负载测试登录场景如下图:
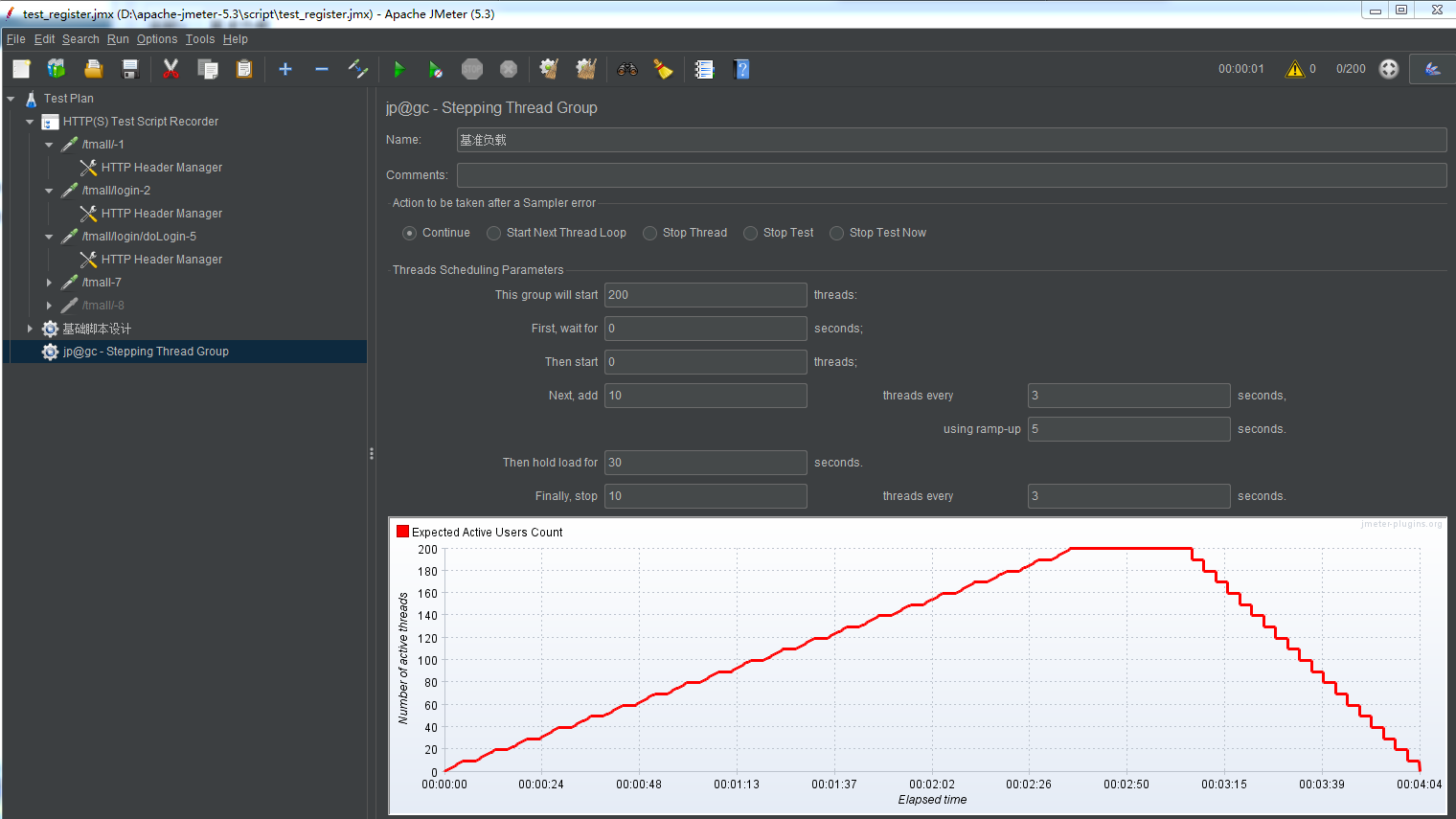
1.一共起200个线程
2.每3秒钟加载10个线程
3.持续30秒
4.每3秒钟释放10个线程。
在负载测试之后需要先看下对应的监控中的cpu使用率等监控信息:
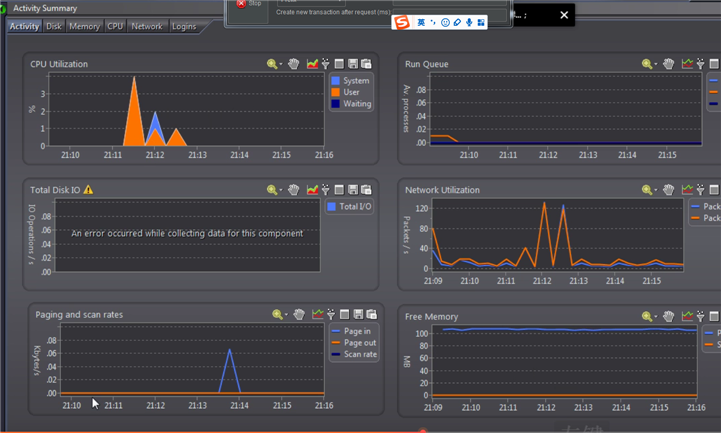
在做负载测试之前需要先看资源消耗情况。等待负载测试做完了做对比。比如,此时的CPU 是4%,在负载测试做完了之后,查看下CPU假如是40%,那cpu 消耗从3%到40%
在负载测试中选择对应的数据进行监听:
压测的时候提示No buffer space available (maximum connections reached?)

------------恢复内容结束------------
------------恢复内容结束------------
------------恢复内容结束------------
------------恢复内容结束------------
标签:mic top use 需要 性能测试 多少 als gbk group
原文地址:https://www.cnblogs.com/somflower/p/14370219.html