标签:search 回顾 排序模型 阶段 地方 == cos 分享 样本
DSSM(Deep Structured Semantic Models)又称双塔模型,因其结构简单,在推荐系统中应用广泛;下面仅以召回、粗排两个阶段的应用举例,
具体描述下DSSM在工业界实践的一些所见所闻,力求自身和大家都能有所收获。
paper:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
example:DSSM召回模型
原始的DSSM是在搜索CTR预估任务,大概分为:1)embedding层 2)MLP层 3)cosine相似度logit 4)softmax层;其中Q代表搜索词(用户),D1,2,...,n为检索文档(物料) 。
如果将最左侧看作一个塔,并称为用户塔;那右侧就可以称为物料塔(或者物料塔1,2,...,n);双塔,多塔架构由此得来。
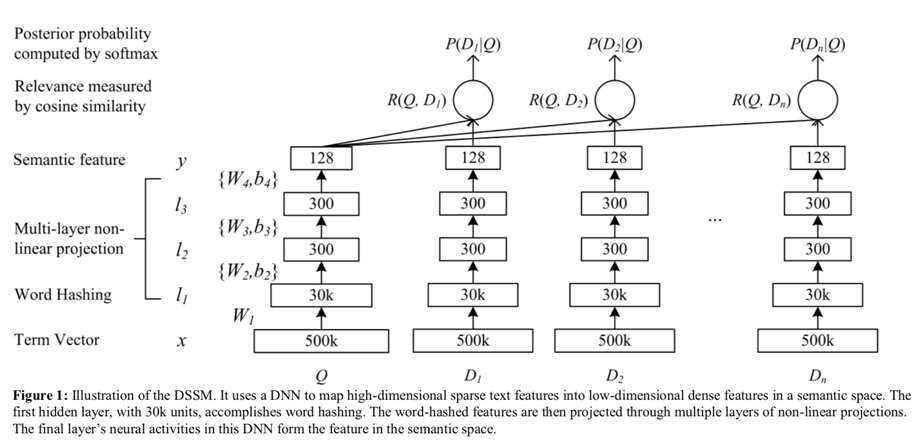
1.1 tanh激活函数与ReLU激活函数
注意DSSM是用的tanh激活函数
自然能想到,将用户最近点击,消费,转化等的数据采集后作为正样本;采样些全局最热但未点击(Youtube负采样套路)作为负样本构造样本训练DSSM模型进行推荐召回。
DSSM在预测的时候就可以借助Faiss进行异步物料向量更新,加载模型后可以根据实时用户行为进行ANN检索(求Topk相似向量)。
下图为视频 | 深度学习在美图个性化推荐的应用实践 中DSSM召回线下训练,线上serving的整体架构图。
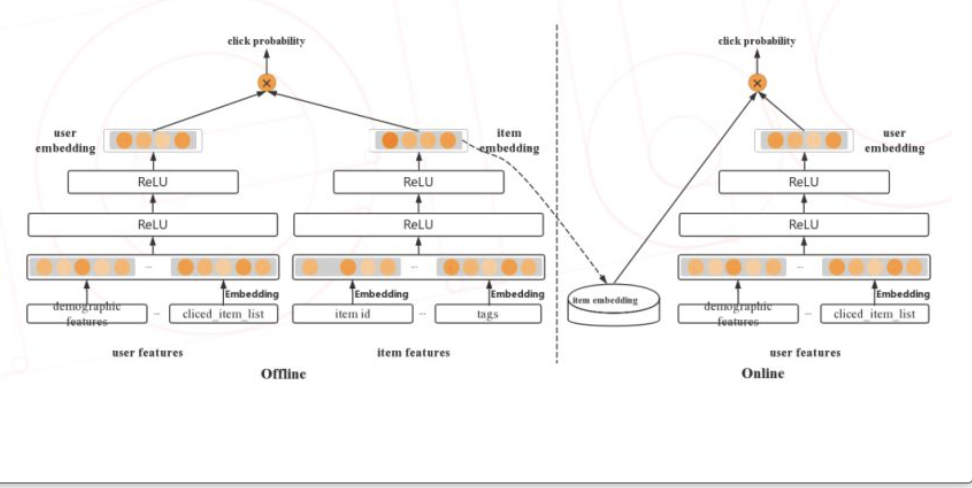
当然DSSM只是一种架构,上面模型结构只是其中一个示例;实际user feature,item feature可以有多种多样建模方式,负样本采样、以及sigmoid还是softmax loss等等都是可以探索的地方。
如果说DSSM召回是用户物料表征的精耕细作,那DSSM粗排就是学习精排序的算力优化。
下面是全民K歌推荐分享 中粗排的引入:大概总结就是将多路召回结果在进入精排前引入粗排阶段,在性能约束的情况下学习精排的排序结果,初筛出精排能处理的结果集。 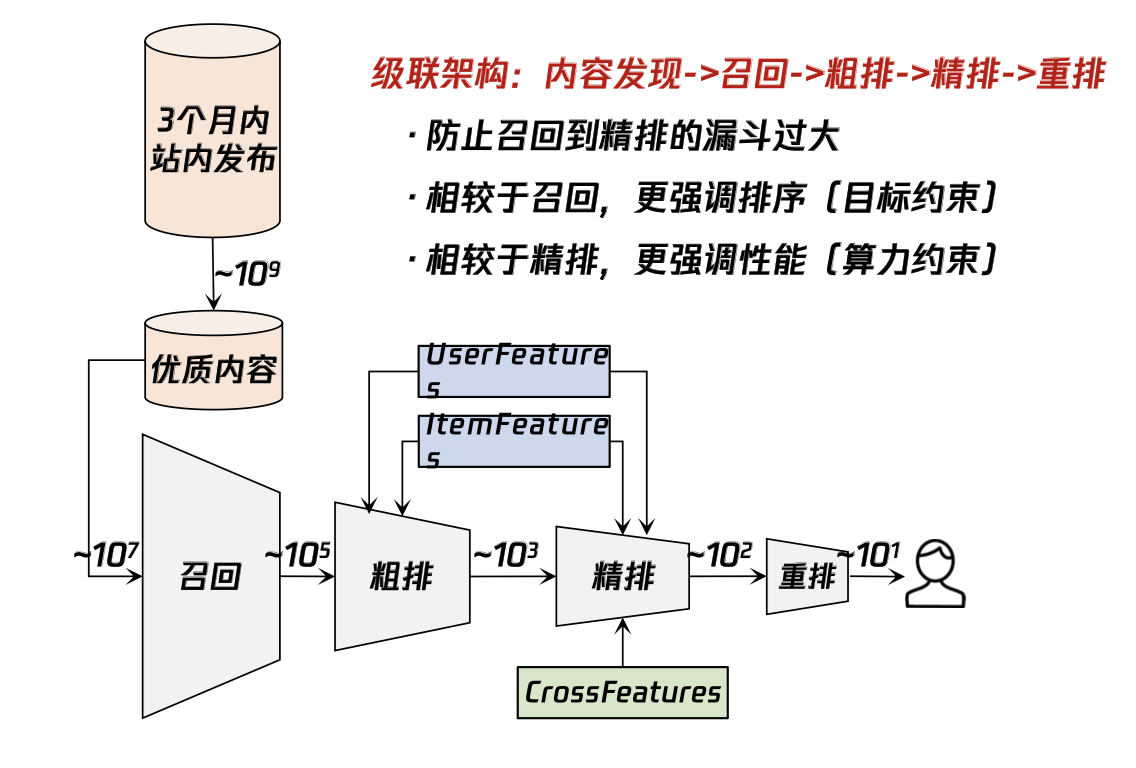
下面是全民K歌推荐分享 的两个演进:
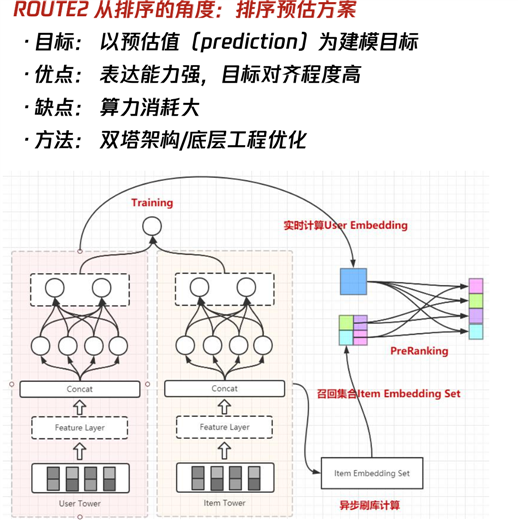
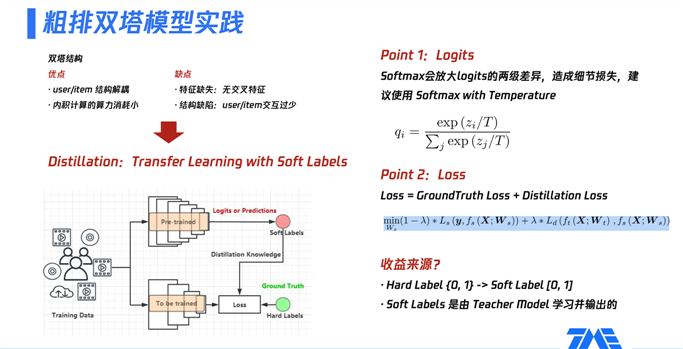
承上启下,上面DSSM的两个优化点都借助于模型蒸馏,其一softmax中加入temperature(即参数T),可以起到平滑/尖锐softmax输出的作用;
T越大,结果越平滑,得到的概率分布更“平滑”;相应的T越小,得到的概率分布更“尖锐”,这就是T的作用。更详细的计算可以参考: SoftMax温度系数temperature parameter;
其二引入Teacher-Student架构进行蒸馏,下面是增加了优势特征(Privileged Features)蒸馏的架构图:
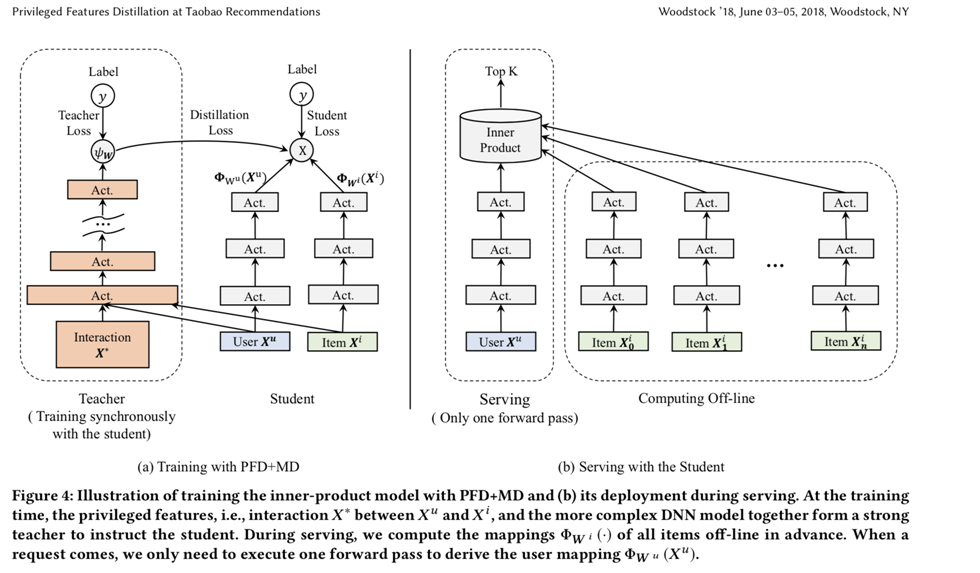
教师网络训练的同时,异步更新学生网络,减少训练时长;线上serving时,仅部署student网络进行前向推断。这样就可以同时训练复杂模型,和提供轻量的线上预估模型。
粗排中的优势特征:
有一些交叉特征是对粗排效果影响明显的,比如用户(u_i)在过去24个小时内在待预估商品类目(cate_j)下的点击次数。但是复杂的交叉特征会增加线上的推理延时,所以不能作为常规特征来训练。于是交叉特征就成为了粗排阶段的优势特征。
关于Point2中的公式说明:
X表示普通特征,X*表示优势特征,y表示标签,L表示损失函数;下标s表示student,d表示distillation,t表示teacher。
上面的介绍仅是从dssm角度总结了召回,排序的一些工作;实际dssm导出的用户向量,物料向量还可衍生出很多著名的召回(读者可以想想上一篇ucf变种); 同时整个排序架构特征更新、样本拼接,模型更新等都由于篇幅有限没有详细说明,那下一篇文章想和大家一起总结回顾下近年来排序模型及架构的主要演进。
标签:search 回顾 排序模型 阶段 地方 == cos 分享 样本
原文地址:https://www.cnblogs.com/arachis/p/DSSM.html