标签:阶段 导致 pairs 实现 block 这一 测试 包含 ext
the Computing Research Repository (CoRR)
论文地址:https://arxiv.org/abs/1909.11898
代码地址:https://github.com/hongwang600/DocRed
Abstract
在本文中,我们进一步应用预先训练的语言模型(BERT)来为这项任务提供一个更强大的基线。我们还发现,分阶段解决此任务可以进一步提高性能。第一步是预测两个实体是否有关系,第二步是预测具体的关系。
1 Introduction
预先训练的语言模型,如BERT(Devlin et al.,2019),可以进一步提高性能,因为它已经捕获了重要的语言特征,并可能捕获一些常识知识。在本文中,我们使用BERT对文档进行编码。采用双线性层来预测实体对之间的关系。我们使用DocRED数据集中带注释的数据对整个模型进行了微调,从而使F1得分提高了约2%。我们还发现,通过两步流程对文档级关系抽取进行建模可以进一步提高性能。第一步是预测一对实体是否有关系。第二步是预测给定实体对的特定关系。请注意,我们在第二步中使用的模型是使用具有DocRED注释的关系的对进行训练的
2 Model
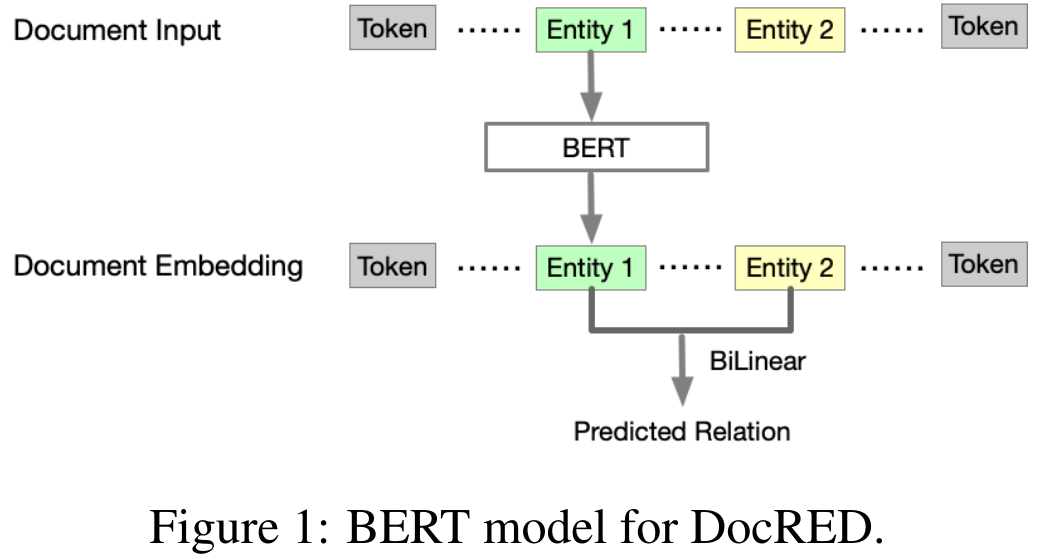
Let $[x_1, x_2,·..., x_n]$ denote the document input, and $[e_1, e_2,..., e_m]$ denote the m entities in the document. We use BERT to encode the document as follows:
$[h_1,h_2,...,h_n]=BERT([x_1,x_2,...x_n])$
from which we can get the embeddings $[h_{e_1}, h_{e_2},· · ·, h_{e_m}]$. Then for each pair of entities $(e_i, e_j)$, we use BiLinear layer to predict its relation:
$r_{i,j}=BILINEAR(h_{e_i},h_{e_j})$
We use BERT-base in our experiments.
2.2 Two-step Training Process
在DocRED数据集中,大多数实体对都没有关系,导致标签不平衡,即大多数实体对都属于N/a关系。为了缓解这个问题,我们使用了两步训练过程。
在第一步中,我们只识别给定实体对之间是否存在关系,即将问题简化为一个二元分类问题。如上所述,我们在这个步骤中使用BERT,其中所有带注释的数据都用于训练模型。子抽样用于平衡每批中的关系和N/A对Sub-sampling is applied to balance relational and N/A pairs in each batch。
在第二步中,我们学习一个模型来识别给定实体对之间的特定关系。模型结构与第一步中的BERT模型相同。区别在于训练数据和标签:我们只使用这些关系事实(即具有关系的实体对)来训练模型,这样模型就可以学会区分这些不同的关系。根据经验,我们发现第二步是相对容易的,因为我们实现了大约90%的准确率。问题的瓶颈在于第一步,即区分是否存在关系。
经过两步训练后,测试过程很简单。对于给定的一对实体,首先应用第一步的模型来预测它们之间是否存在关系。如果它预测了一个关系,那么第二步的模型将用于预测一个特定的关系。
3 Experiments
Dataset:DocRED
3.2 Implementation Details
We use BERT-base in our experiments. The learning rate is set to $10^{?5}$. The embedding size of BERT model is 768. A transformation layer is used to project the BERT embedding into a low-dimensional space of size 128. In the low-dimension space, a BiLinear layer is applied to predict the relation for a given entity pair.
在第一步中,我们将所有关系实例的关系标签设置为1,而所有N/A关系的标签设置为0。我们在一批中以3:1的比例随机抽取N/A关系。在第二步中,我们只使用关系实例来训练一个新的模型,并且在这一步中保留特定的关系标签。
3.3 Results
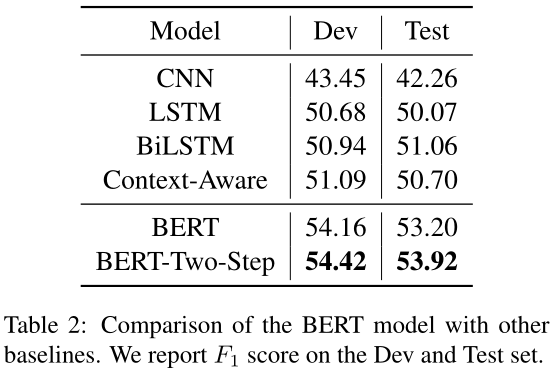
主要结果见表2。我们可以看到,通过使用BERT编码器,我们得到了2%的改进,这表明它可能包含有用的信息,如常识知识,以解决这项任务。通过两步训练过程,进一步提高了绩效。在我们的实验中,我们发现第二步的准确率在90%以上,这意味着瓶颈在于第一步,例如预测给定实体对是否存在关系。
3.4 Complex interaction modeling
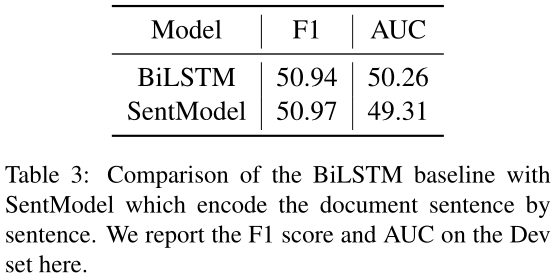
为了测试当前模型是否能够捕获实体之间的复杂交互,我们使用了一个SentModel,它对文档逐句进行编码。然后我们将每个实体定位在一个特定的句子中,并通过平均实体名称的单词嵌入来计算其嵌入。这样,句子之间就没有交互了,因为我们把整个文档一句一句地编码。我们在表3中给出了结果。令人惊讶的是,SentModel可以实现与将整个文档编码为序列的BiLSTM模型非常相似的性能。因此,当前的模型无法捕捉实体之间的复杂交互,只能使用每个实体周围的局部信息来预测关系。
4 Conclusion & Discussion
本文研究了BERT在文档级RE中的应用。我们发现,BERT能显著提高学习成绩,我们认为这可能得益于在训练前学习到的常识知识。我们还发现,使用两步训练过程可以进一步提高性能。这个数据集的困难在于区分一对实体之间是否存在关系,而识别一个特定的关系似乎不那么困难。另一个发现是现有的模型无法对实体之间的复杂交互进行建模,我们认为这是解决文档级重用问题的关键。
【论文阅读】Fine-tune Bert for DocRED with Two-step Process[CoRR2019]
标签:阶段 导致 pairs 实现 block 这一 测试 包含 ext
原文地址:https://www.cnblogs.com/Harukaze/p/14394979.html