标签:框架 增量 zip 网络通信 文件的 eager loader 最优 正是
参数服务器训练基本理论
参数服务器训练是分布式训练领域普遍采用的编程架构,主要解决以下两类问题:
如图所示,参数服务器主要包含Server和Worker两个部分,其中Server负责参数的存储和更新,而Worker负责训练。简单来说,参数服务器训练的基本思路:当训练数据过多,一个Worker训练太慢时,可以引入多个Worker同时训练,这时Worker之间需要同步模型参数。直观想法是,引入一个Server,Server充当Worker间参数交换的媒介。当模型参数过大,以至于单机存储空间不足时,或Worker过多导致一个Server是瓶颈时,就需要引入多个Server。
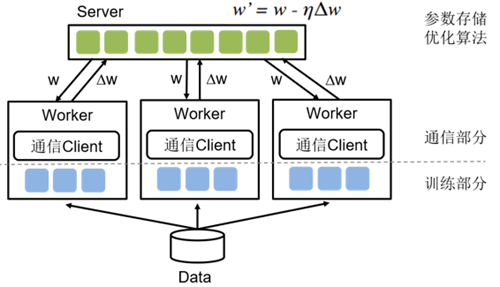
参数服务器训练的具体流程如下:
飞桨paddle的参数服务器框架,也是基于这种经典的参数服务器模式进行设计和开发的,在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(GEO-SGD)。目前飞桨paddle支持3种模式,分别是同步训练模式、异步训练模式、GEO异步训练模式,三者之间的差异如下图所示。
当前经过大量的实验验证,最佳的方案是每台机器上启动Server和Worker两个进程,而一个Worker进程中,可以包含多个用于训练的线程。
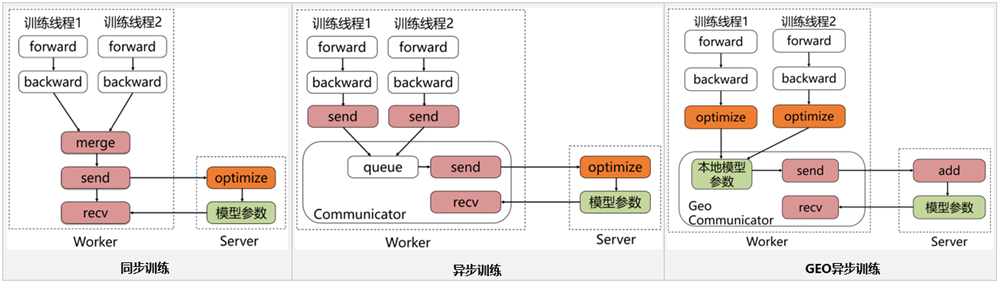
同步训练
Worker在训练一个batch的数据后,会合并所有线程的梯度发给Server, Server在收到所有节点的梯度后,会统一进行梯度合并及参数更新。同步训练的优势在于Loss可以比较稳定的下降,缺点是整个训练速度较慢,这是典型的木桶原理,速度的快慢取决于最慢的那个线程的训练计算时间,在训练较为复杂的模型时,即模型训练过程中神经网络训练耗时,远大于节点间通信耗时的场景下,推荐使用同步训练模式。
异步训练
在训练一个batch的数据后,Worker的每个线程会发送梯度给Server。而Server不会等待接收所有节点的梯度,而是直接基于已收到的梯度进行参数更新。异步训练去除了训练过程中的等待机制,训练速度得到了极大的提升,但是缺点也很明显,那就是Loss下降不稳定,容易发生抖动。建议在个性化推荐(召回、排序)、语义匹配等数据量大的场景使用。 尤其是推荐领域的点击率预估场景,该场景可能会出现千亿甚至万亿规模的稀疏特征,而稀疏参数也可以达到万亿数量级,且需要小时级或分钟级流式增量训练。如果使用异步训练模式,可以很好的满足该场景的online-learning需求。
GEO异步训练
GEO(Geometric Stochastic Gradient Descent)异步训练是飞桨paddle自研的异步训练模式,其最大的特点是将参数的更新从Server转移到Worker上。每个Worker在本地训练过程中,使用SGD优化算法更新本地模型参数,在训练若干个batch的数据后,Worker将发送参数更新信息给Server。Server在接收后会通过加和方式更新保存的参数信息。所以显而易见,在GEO异步训练模式下,Worker不用再等待Server发来新的参数即可执行训练,在训练效果和训练速度上有了极大的提升。但是此模式比较适合可以在单机内能完整保存的模型,在搜索、NLP等类型的业务上应用广泛,推荐在词向量、语义匹配等场景中使用。
运行策略的详细描述可以参考文档PaddlePaddle 参数服务器分布式训练策略定义
基于分类模型的训练示例
本文档以二分类模型举例,介绍单机训练和参数服务器训练(异步模式)两种模式的详细代码,方便用户快速了解两种模式的具体差异。
本文涉及的所有源码,可通过此链接获取:https://github.com/seiriosPlus/Fleet/tree/distribtued_training/examples/distributed_ctr 建议亲手操作,毕竟只有亲手敲过的代码才真正是自己的。
单机训练示例
环境准备
训练前,请确保:
数据处理
数据集采用Display Advertising Challenge所用的Criteo数据集。该数据集包括两部分:训练集和测试集。训练集包含一段时间内Criteo的部分流量,测试集则对应训练数据后一天的广告点击流量。
数据预处理共包括两步:
模型设计
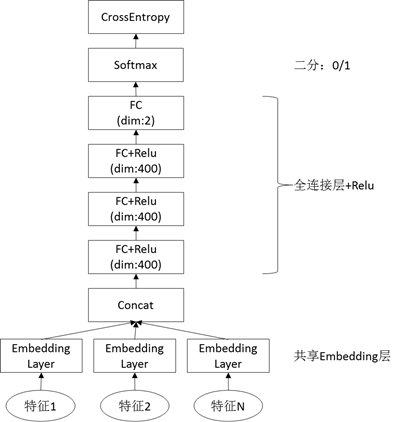
模型属于二分类模型,网络结构如下图所示。输入是N类稀疏特征,比如词的id。通过查取embedding表(字典大小xM维的向量表),变换成N个M维向量。将所有NxM维向量连接在一起融合为一个向量。网络由多个输入数据层(paddle.static.data)、多个共享参数的嵌入层(paddle.nn.functional.embedding),若干个全连接层(paddle.static.fc),以及相应的分类任务的Loss计算和auc计算。经过多层全连接层+激活函数(relu)后,进行0/1分类。
# 数据输入声明
# Criteo数据集分连续数据与离散(稀疏)数据,整体而言,数据输入层包括三个,分别是:`dense_input`用于输入连续数据,维度由超参数`dense_feature_dim`指定,数据类型是归一化后的浮点型数据。`sparse_input_ids`用于记录离散数据,在Criteo数据集中,共有26个slot,所以创建了名为`C1~C26`的26个稀疏参数输入,并设置`lod_level=1`,代表其为变长数据,数据类型为整数;最后是每条样本的`label`,代表了是否被点击,数据类型是整数,0代表负样例,1代表正样例。
# 在飞桨paddle中数据输入的声明使用`paddle.static.data()`,会创建指定类型的占位符,数据IO会依据此定义进行数据的输入
def input_data(self, params):
dense_input = paddle.static.data(name="dense_input",
shape=[params.dense_feature_dim],
dtype="float32")
sparse_input_ids = [
paddle.static.data(name="C" + str(i),
shape=[1],
lod_level=1,
dtype="int64") for i in range(1, 27)
]
label = paddle.static.data(name="label", shape=[1], dtype="int64")
inputs = [dense_input] + sparse_input_ids + [label]
return inputs
def net(self, inputs, params):
# Embedding层
# Embedding层的组网方式:`Embedding`层的输入是`sparse_input`,shape由超参的`sparse_feature_dim`和`embedding_size`定义
# 指定`is_sprase=True`后,计算图会将该参数视为稀疏参数,反向更新以及分布式通信时,都以稀疏的方式进行,会极大的提升运行效率,同时保证效果一致。
def embedding_layer(input):
return paddle.nn.functional.embedding(
input=input,
is_sparse=params.is_sparse,
size=[params.sparse_feature_dim, params.embedding_size]),
)
sparse_embed_seq = list(map(embedding_layer, inputs[1:-1]))
# 各个稀疏的输入通过Embedding层后,将其合并起来,置于一个list内,以方便进行concat的操作
concated = paddle.concat(sparse_embed_seq + inputs[0:1], axis=1)
# 将离散数据通过embedding查表得到的值,与连续数据的输入进行`concat`操作,合为一个整体输入,作为全链接层的原始输入。共设计了3层FC,每层FC的输出维度都为400,每层FC都后接一个`relu`激活函数,每层FC的初始化方式为符合正态分布的随机初始化,标准差与上一层的输出维度的平方根成反比。
fc1 = paddle.static.fc(
input=concated,
size=400,
act="relu"
)
fc2 = paddle.static.fc(
input=fc1,
size=400,
act="relu"
)
fc3 = paddle.static.fc(
input=fc2,
size=400,
act="relu"
)
predict =paddle.static.fc(
input=fc3,
size=2,
act="softmax"
)
# Loss及Auc计算
# 预测的结果通过一个输出shape为2的FC层给出,该FC层的激活函数softmax,会给出每条样本分属于正负样本的概率。
# 每条样本的损失由交叉熵给出,交叉熵的输入维度为[batch_size,2],数据类型为float,label的输入维度为[batch_size,1],数据类型为int。该batch的损失`avg_cost`是各条样本的损失之和
# 同时还会计算预测的auc,auc的结果由`paddle.static..auc()`给出,该层的返回值有三个,分别是全局auc: `auc_var`,当前batch的auc: `batch_auc_var`,以及auc_states: `auc_states`,auc_states包含了`batch_stat_pos, batch_stat_neg, stat_pos, stat_neg`信息。
cost = paddle.nn.functional.cross_entropy(input=predict, label=inputs[-1])
avg_cost = paddle.sum(cost)
auc_var, batch_auc_var, _ = paddle.static.auc(input=predict,
label=inputs[-1])
return avg_cost, auc_var, batch_auc_var
模型训练
def train(params):
# 引入模型的组网
ctr_model = CTR()
inputs = ctr_model.input_data(params)
avg_cost, auc_var, batch_auc_var = ctr_model.net(inputs,params)
# 选择反向更新优化策略
optimizer = paddle.optimizer.Adam(params.learning_rate)
optimizer.minimize(avg_cost)
# 创建训练的执行器
exe = paddle.static.Executor(paddle.CPUPlace())
exe.run(paddle.static.default_startup_program())
# 引入数据读取
dataset = get_dataset(inputs,params)
# 开始训练
for epoch in range(params.epochs):
# 启动pyreader的异步训练线程
# PyRreader是飞桨paddle提供的简洁易用的数据读取API接口,支持同步数据读取及异步数据读取,用户自行定义数据处理的逻辑后,以迭代器的方式传递给PyReader,完成训练的数据读取部分
reader.start()
batch_id = 0
try:
while True:
# 获取网络中,所需的输出,如loss、auc等
loss_val, auc_val, batch_auc_val = exe.run(
program=compiled_prog,
fetch_list=[
avg_cost.name, auc_var.name, batch_auc_var.name
])
loss_val = np.mean(loss_val)
auc_val = np.mean(auc_val)
batch_auc_val = np.mean(batch_auc_val)
# 每隔10个Batch打印一次输出
if batch_id % 10 == 0 and batch_id != 0:
logger.info(
"TRAIN --> pass: {} batch: {} loss: {} auc: {}, batch_auc: {}"
.format(epoch, batch_id,
loss_val / params.batch_size, auc_val,
batch_auc_val))
batch_id += 1
except paddle.core.EOFException::
# 一次训练完成后,要调用reset来将Reader恢复为初始状态,为下一轮训练准备
reader.reset()
logger.info("Train Success!")
参数服务器训练示例
对于参数服务器训练来说,训练前也需要完成环境准备、数据处理、模型设计工作。其中,数据处理和模型设计与单机训练完全相同,可以直接拿来使用。
环境准备
执行模型训练前,需要确保运行环境满足以下要求:
数据处理
参数服务器训练的数据处理与单机训练完全相同,这里不再重复赘述。
模型设计
参数服务器训练的模型设计与单机训练完全相同,这里不再重复赘述。
模型训练
飞桨paddle的参数服务器中存在Worker和PServer两种角色,下面会结合2X2的实际情况讲述启动流程。 飞桨paddle的参数服务器的训练分为3个阶段, 一是将PServer全部启动, PServer会根据用户定义的监听端口启动监听服务,等待Worker连接;二是启动全部Worker节点,Worker节点会根据配置的Pserver的端口号跟每一个PServer进行连接检查,确保能够顺利连接后,进行参数的初始化和同步;三是启动训练流程,通过跟多个PServer的通信完成整个训练流程。 假设有两台机器,想要在每台机器上分别启动一个server进程以及一个worker进程,完成2x2(2个参数服务器,2个训练节点)的参数服务器模式分布式训练,按照如下步骤操作。
启动server
机器A,IP地址是10.89.176.11,通信端口是36000,配置如下环境变量后,运行训练的入口程序:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=PSERVER
export POD_IP=10.89.176.11 # node A:10.89.176.11
export PADDLE_PORT=36000
export PADDLE_TRAINERS_NUM=2
python -u train.py --is_cloud=1
应能在日志中看到如下输出:
server.cpp:1040] Check out http://10.89.176.11:36000 in web browser.
查看系统进程
8624 | ttys000 | 0:02.31 | python -u train.py --is_cloud=1
查看系统进程及端口占用:
python3.7 | 8624 | paddle | 8u | IPv6 | 0xe149b87d093872e5 | 0t0 | TCP | localhost:36000 (LISTEN)
也可以看到的server进程8624的确在36000端口开始了监听,等待worker的通信。
机器B,IP地址是10.89.176.12,通信端口是36000,配置如下环境变量后,运行训练的入口程序:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=PSERVER
export POD_IP=10.89.176.12 # node B: 10.89.176.12
export PADDLE_PORT=36000
export PADDLE_TRAINERS_NUM=2
python -u train.py --is_cloud=1
也可以看到相似的日志输出与进程状况。(进行验证时,请务必确保IP与端口的正确性)
启动worker
接下来分别在机器A与B上开启训练进程。配置如下环境变量并开启训练进程:
机器A:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=TRAINER
export PADDLE_TRAINERS_NUM=2
export PADDLE_TRAINER_ID=0 # node A:trainer_id = 0
python -u train.py --is_cloud=1
机器B:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=TRAINER
export PADDLE_TRAINERS_NUM=2
export PADDLE_TRAINER_ID=1 # node B: trainer_id = 1
python -u train.py --is_cloud=1
运行该命令时,若Pserver还未就绪,可在日志输出中看到如下信息:
server not ready, wait 3 sec to retry…
not ready endpoints:[‘10.89.176.11:36000’, ‘10.89.176.12:36000’]
Worker进程将持续等待,直到Pserver开始监听,或等待超时。
当Pserver都准备就绪后,可以在日志输出看到如下信息:
I0317 11:38:48.099179 16719 communicator.cc:271] Communicator start
I0317 11:38:49.838711 16719 rpc_client.h:107] init rpc client with trainer_id 0
至此,分布式训练启动完毕,开始训练。
参数服务器训练数据切分
飞桨paddle的参数服务器训练目前主要是数据并行模式。通过增加训练节点来提高训练数据的并行度的,需要对数据进行划分,即将全部的训练数据均匀的分成Worker个数份,每一个Worker需要分配全部训练数据中的一份,每个Worker节点训练自己的一份数据,参数由PServer端完成聚合和更新。要确保每个节点都能拿到数据,希望每个节点的数据同时满足:各个节点数据无重复和各个节点数据数量均匀。
Fleet提供了split_files()的接口,输入值是一个稳定的目录List,随后该函数会根据节点自身的编号拿到相应的数据文件列表,训练数据在同一个目录下,使用该接口,给各个进程(扮演不同的训练节点)分配不同的数据文件。
file_list = [
str(args.train_files_path) + "/%s" % x
for x in os.listdir(args.train_files_path)
]
# 请确保每一个训练节点都持有不同的训练文件
# 当用本地多进程模拟分布式时,每个进程需要拿到不同的文件
# 使用 fleet.split_files 可以便捷的以文件为单位分配训练样本
files= fleet.split_files(file_list)
基于得到的files,每个节点开始独立进行数据读取和训练。如果数据在HDFS上,可以根据files列表将数据下载会本地进行读取。如果数据在本地,则可直接根据files列表进行读取。
详细训练代码示例
异步模式分布式训练代码的详细说明如下所示。
# 根据环境变量确定当前机器/进程在分布式训练中的角色分配Worker/PSERVER
# 然后使用 fleet api的 init()方法初始化这个节点
role = role_maker.PaddleCloudRoleMaker()
fleet.init(role)
# 设置分布式运行模式为异步(async),同时将参数进行切分,以分配到不同的节点
strategy = StrategyFactory.create_async_strategy()
ctr_model = CTR()
inputs = ctr_model.input_data(params)
avg_cost, auc_var, batch_auc_var = ctr_model.net(inputs, params)
optimizer = paddle.optimizer.Adam(params.learning_rate)
# 配置分布式的optimizer,传入指定的strategy,构建program
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(avg_cost)
# 根据节点角色,分别运行不同的逻辑
if fleet.is_server():
# 初始化及运行参数服务器节点
fleet.init_server()
fleet.run_server()
elif fleet.is_worker():
# 初始化工作节点
fleet.init_worker()
exe = paddle.static.Executor(paddle.CPUPlace())
# 初始化含有分布式流程的fleet.startup_program
exe.run(fleet.startup_program)
for epoch in range(params.epochs):
# 启动dataloader的异步训练线程
# DataLoader是飞桨paddle提供的简洁易用的数据读取API接口,支持同步数据读取及异步数据读取,用户自行定义数据处理的逻辑后,以迭代器的方式传递给DataLoader,完成训练的数据读取部分
reader.start()
batch_id = 0
try:
while True:
# 获取网络中,所需的输出,如loss、auc等
loss_val, auc_val, batch_auc_val = exe.run(
program=compiled_prog,
fetch_list=[
avg_cost.name, auc_var.name, batch_auc_var.name
])
loss_val = np.mean(loss_val)
auc_val = np.mean(auc_val)
batch_auc_val = np.mean(batch_auc_val)
# 每隔10个Batch打印一次输出
if batch_id % 10 == 0 and batch_id != 0:
logger.info(
"TRAIN --> pass: {} batch: {} loss: {} auc: {}, batch_auc: {}"
.format(epoch, batch_id,
loss_val / params.batch_size, auc_val,
batch_auc_val))
batch_id += 1
except paddle.core.EOFException:
# 一次训练完成后,要调用reset来将Reader恢复为初始状态,为下一轮训练准备
reader.reset()
# 默认使用0号节点保存模型
if fleet.is_first_worker():
model_path = (str(params.model_path) + "/" + "epoch_" +
str(epoch))
fleet.save_persistables(executor=exe, dirname=model_path)
fleet.stop_worker()
使用pyreader进行多轮训练时,有一些固有的使用方法,如示例代码所示,使用try & except捕获异常的方式得到reader读取完数据的信号,使用reset重置reader,以进行下一轮训练的数据读取。 执行exe.run()时,传入的是CompiledProgram,同时可以通过加入fetch_list来直接获取想要监控的变量。
运行:本地模拟分布式
运行方式有两种方式。
方法一 运行local_cluster.sh脚本
运行local_cluster.sh脚本,设置启动命令为sync:
sh local_cluster.sh sync
使用该脚本开启分布式模拟训练,默认启用2x2的训练模式。Worker与Pserver的运行日志,存放于./log/文件夹,保存的模型位于./model/。
方法二 运行飞桨paddle内置的一个启动器launch_ps
在单机模拟多机训练的启动命令,飞桨paddle内置的一个启动器launch_ps,用户可以指定Worker和server的数量进行参数服务器任务的启动。
python -m paddle.distributed.launch_ps --worker_num 2 --server_num 2 train.py
使用该脚本开启分布式模拟训练,也将启用2个Worker x 2个server的训练模式。Worker与Pserver的运行日志,存放于./logs/文件夹,保存的模型位于./model/。
开启本地模拟分布式训练后的日志输出
使用快速验证数据集,本地模拟同步模式的分布式训练的理想输出为:
pserver.0.log
INFO:file list: [‘train_data/part-1‘]
get_pserver_program() is deprecated, call get_pserver_programs() to get pserver main and startup in a single call.
I1128 11:34:50.242866 459 grpc_server.cc:477] Server listening on 127.0.0.1:36011 successful, selected port: 36011
trainer.0.log
INFO:file list: [‘train_data/part-1‘]
server not ready, wait 3 sec to retry...
not ready endpoints:[‘127.0.0.1:36012‘]
I1128 11:34:53.424834 32649 rpc_client.h:107] init rpc client with trainer_id 0
I1128 11:34:53.526729 32649 parallel_executor.cc:423] The Program will be executed on CPU using ParallelExecutor, 2 cards are used, so 2 programs are executed in parallel.
I1128 11:34:53.537334 32649 parallel_executor.cc:287] Inplace strategy is enabled, when build_strategy.enable_inplace = True
I1128 11:34:53.541473 32649 parallel_executor.cc:370] Garbage collection strategy is enabled, when FLAGS_eager_delete_tensor_gb = 0
INFO:TRAIN --> pass: 0 batch: 10 loss: 0.588123535156 auc: 0.497622251208, batch_auc: 0.496669348982
INFO:TRAIN --> pass: 0 batch: 20 loss: 0.601480102539 auc: 0.501770208439, batch_auc: 0.520060819177
INFO:TRAIN --> pass: 0 batch: 30 loss: 0.581234985352 auc: 0.513533941098, batch_auc: 0.552742309157
INFO:TRAIN --> pass: 0 batch: 40 loss: 0.551335083008 auc: 0.523242733864, batch_auc: 0.586762885637
INFO:TRAIN --> pass: 0 batch: 50 loss: 0.532891052246 auc: 0.538684471661, batch_auc: 0.617389479234
INFO:TRAIN --> pass: 0 batch: 60 loss: 0.564157531738 auc: 0.552346798675, batch_auc: 0.628245358534
INFO:TRAIN --> pass: 0 batch: 70 loss: 0.547578674316 auc: 0.565243961316, batch_auc: 0.651260427476
INFO:TRAIN --> pass: 0 batch: 80 loss: 0.554214599609 auc: 0.57554000345, batch_auc: 0.648544028986
INFO:TRAIN --> pass: 0 batch: 90 loss: 0.549561889648 auc: 0.585579565556, batch_auc: 0.660180398731
INFO:epoch 0 finished, use time=40
INFO:Distribute Train Success!
模型预测
完成前面的单机训练和参数服务器训练完成后,需要在测试集上测试离线预测的结果,验证模型的泛化能力。本节内容对应示例代码中的infer.py。
单机训练和参数服务器训练均采用此操作进行模型预测。
构建预测网络及加载模型参数
预测网络与训练网络一致,无需更改,使用相同的方式构建inputs、loss、auc。加载参数使用paddle.io.load_vars()接口,从保存好的模型文件夹中加载同名参数。
# paddle中对于program的独立作用域限定, 在此作用域下配置的所有组网相关的操作均作用于test_program, startup_program上
with paddle.static.program_guard(test_program, startup_program):
# paddle中对于参数命名的独立作用域限定, 在此作用域下配置的组网,会重新开始编号,不会和其他网络冲突
with paddle.static.unique_name.guard():
inputs = ctr_model.input_data(params)
loss, auc_var, batch_auc_var = ctr_model.net(inputs, params)
exe = paddle.static.Executor(place)
feeder =paddle.io.DataLoader(feed_list=inputs, place=place)
paddle.static.load_vers(
executor=exe,
dirname=model_path,
main_program=paddle.static.default_main_program())
在进行上述流程时,有一些需要关注的细节:
飞桨paddle创建的临时变量,编号会自动顺延,如果没有指定变量名,可以观察到这一现象,比如:fc_1.w_0->fc_2.w_0,想要共享相同的参数,必需要保证编号可以对应。
获取测试数据
测试数据的读取使用同步模式中使用过的pyreader方法。
运行测试
为了快速验证,仅取用测试数据集的一个part文件,进行测试。在代码目录下,键入以下命令,进行预测:
python -u infer.py &> test.log &
测试结果的日志位于test.log,仅训练一个epoch后,在part-220上的的理想测试结果为:
2019-11-26 08:56:19,985 - INFO - Test model model/epoch_0
open file success
2019-11-26 08:56:20,323 - INFO - TEST --> batch: 0 loss: [0.5577456] auc: [0.61541704]
2019-11-26 08:56:37,839 - INFO - TEST --> batch: 100 loss: [0.5395161] auc: [0.6346397]
2019-11-26 08:56:55,189 - INFO - {‘loss‘: 0.5571399, ‘auc‘: array([0.6349838])}
2019-11-26 08:56:55,189 - INFO - Inference complete
因为快速验证的训练数据与测试数据极少,同时只训练了一轮,所以远远没有达到收敛,且初始化带有随机性,在您的环境下出现测试结果与示例输出不一致是正常情况。
参数服务器训练的性能调优
优化的目的是在给定数据集上,以最快速度训练得到最优的效果。参数服务器训练的性能调优分为速度提升和效果提升。
速度提升
参数服务器训练涉及的训练如下图所示。
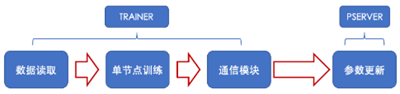
可以看出:训练时间 = 数据读取时间 + 节点训练(网络前向后向执行时间) + 通信时间 + 节点之间等待时间 + 更新参数时间。
因此可以从数据读取、单节点训练、通信模块、Server端参数更新这4个方面进行参数服务器的优化。
Dataset数据读取
目前支持PyReader和Dataset两种,后者速度更快。PyReader采用的模式是多个读数据线程写到一个队列中,多个训练线程从这个一个队列中读取数据,形成了多生产者多消费者的模式,导致队列成为瓶颈。Dataset采用多个读数据线程写到多个队列中,多个训练线程之间完全异步的模式, 消除队列瓶颈,在数据读取速度上更胜一筹。
在模型比较简单、数量比较大时,可以使用参数服务器的全异步训练模式和高性能的IO数据读取模式来高速的训练。Dataset是为多线程及全异步模式量身打造的数据读取方式,每个数据读取线程会与一个训练线程耦合,形成了多生产者-多消费者的模式,极大的加速了模型训练。详细的Dataset的设计文档可以参考:Dataset
如何在的训练中引入Dataset读取方式呢?
无需变更数据格式,只需在的训练代码中加入以下内容,便可达到媲美二进制读取的高效率,以下是一个比较完整的流程。
一、定义Dataset
以下是dataset_generator.py的全部代码,具体流程如下:
import paddle.distributed.fleet.data_generator as dg
cont_min_ = [0, -3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
cont_max_ = [20, 600, 100, 50, 64000, 500, 100, 50, 500, 10, 10, 10, 50]
cont_diff_ = [20, 603, 100, 50, 64000, 500, 100, 50, 500, 10, 10, 10, 50]
hash_dim_ = 1000001
continuous_range_ = range(1, 14)
categorical_range_ = range(14, 40)
class CriteoDataset(dg.MultiSlotDataGenerator):
def generate_sample(self, line):
def reader():
features = line.rstrip(‘\n‘).split(‘\t‘)
dense_feature = []
sparse_feature = []
for idx in continuous_range_:
if features[idx] == "":
dense_feature.append(0.0)
else:
dense_feature.append(
(float(features[idx]) - cont_min_[idx - 1]) /
cont_diff_[idx - 1])
for idx in categorical_range_:
sparse_feature.append(
[hash(str(idx) + features[idx]) % hash_dim_])
label = [int(features[0])]
process_line = dense_feature, sparse_feature, label
feature_name = ["dense_feature"]
for idx in categorical_range_:
feature_name.append("C" + str(idx - 13))
feature_name.append("label")
yield zip(feature_name, [dense_feature] + sparse_feature + [label])
return reader
d = CriteoDataset()
d.run_from_stdin()
二、引入Dataset
def get_dataset(inputs, params)
dataset = paddle.distributed.fleet.dataset.DatasetBase()
dataset._set_use_var(inputs)
dataset._set_pipe_command("python dataset_generator.py")
dataset._set_batch_size(params.batch_size)
dataset._set_thread(int(params.cpu_num))
file_list = [
str(params.train_files_path) + "/%s" % x
for x in os.listdir(params.train_files_path)
]
dataset.set_filelist(file_list)
logger.info("file list: {}".format(file_list))
return dataset
三、 Dataset Reader 快速调试
可以脱离组网架构,单独验证Dataset的输出是否符合预期。使用命令 cat 数据文件 | python dataset读取python文件进行dataset代码的调试:
cat train_data/part-0 | python dataset_generator.py
输出的数据格式如下: dense_input:size ; dense_input:value ; sparse_input:size ; sparse_input:value ; ... ; sparse_input:size ; sparse_input:value ; label:size ; label:value
理想的输出为(截取了一个片段):
...
13 0.05 0.00663349917081 0.05 0.0 0.02159375 0.008 0.15 0.04 0.362 0.1 0.2 0.0 0.04 1 715353 1 817085 1 851010 1 833725 1 286835 1 948614 1 881652 1 507110 1 27346 1 646986 1 643076 1 200960 1 18464 1 202774 1 532679 1 729573 1 342789 1 562805 1 880474 1 984402 1 666449 1 26235 1 700326 1 452909 1 884722 1 787527 1 0
...
使用Dataset的一些注意事项
节点训练
加快训练速度,采用多线程的方式进行单节点的训练,如配置更大的线程数来加速训练等。
通信模块
分布式训练策略GEO异步训练的配置,引入StrategyFactory后,只需调用create_geo_strategy即可。
```python
optimizer = paddle.optimizer.SGD(params.learning_rate)
# geo异步模式可以指定通信间隔的MiniBatch数,间隔Batch数越大,理论上速度越快,但是对效果可能有影响,需要在此进行权衡
strategy = paddle.distributed.fleet.DistributedStrategy()
strategy.a_sync = True
strategy.a_sync_configs = {"k_steps": 100}
# 配置分布式的optimizer,传入指定的strategy,构建program
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(avg_cost)
```
参数更新
# 稀疏参数(embedding等)会采用稀疏更新
optimizer = paddle.optimizer.AdamOptimizer(learning_rate=0.002, lazy_mode=True)
效果提升
可以通过调整训练数据分布、训练模式、优化算法及超参等手段来提升模型效果。试想,在同步训练下,由于Pserver端更新参数时采用的是全局梯度,当“多机下节点数乘以batchsize等于单机下batchsize”时,多机效果可以和单机打平, 所以分布式下的效果优化,可以归结为向单机靠齐。
标签:框架 增量 zip 网络通信 文件的 eager loader 最优 正是
原文地址:https://www.cnblogs.com/wujianming-110117/p/14398491.html