标签:started dia 环境变量 collect image data- type 用户 依赖
多机多卡训练基本原理
在工业实践中,许多较复杂的任务需要使用更强大的模型。强大模型加上海量的训练数据,经常导致模型训练耗时严重。比如在计算机视觉分类任务中,训练一个在ImageNet数据集上精度表现良好的模型,大概需要一周的时间,需要不断尝试各种优化的思路和方案。如果每次训练均要耗时1周,这会大大降低模型迭代的速度。在机器资源充沛的情况下,可以采用分布式训练,大部分模型的训练时间可压缩到小时级别。
飞桨paddle有便利的数据并行训练方式,仅改动几行代码即可实现多GPU训练,如何将一个单机程序通过简单的改造,变成多机多卡程序。
单机训练改多机多卡训练
将单机单卡训练模式转换为多机多卡训练模式是非常简单便捷的。在不修改原来的单机单卡程序的基础上,只需在该代码的指定位置上添加相应的函数,即可以实现多机多卡的转换。
首先来看一个简单的单机单卡程序。
单机单卡代码示例
# 下面是一个简单的单机单卡程序
import numpy as np
import paddle.fluid as fluid
import os
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act=‘tanh‘)
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act=‘tanh‘)
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act=‘softmax‘)
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype(‘float32‘),
"y": np.random.randint(2, size=(128, 1)).astype(‘int64‘)}
input_x = fluid.layers.data(name="x", shape=[32], dtype=‘float32‘)
input_y = fluid.layers.data(name="y", shape=[1], dtype=‘int64‘)
# 定义损失
cost = mlp(input_x, input_y)
# 定义优化器
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
optimizer.minimize(cost)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
# 进行训练
for i in range(step):
cost_val = exe.run(feed=gen_data(),
fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 模型保存
model_path = "./"
if os.path.exists(model_path):
fluid.io.save_persistables(exe, model_path)
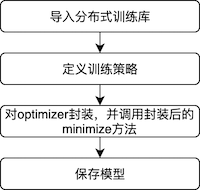
单机单卡改多机多卡操作流程
将单机单卡训练模式改成多机多卡训练模式的操作流程如下:
1、导入分布式训练库。
2、定义训练策略和集群环境定义。
3、对optimizer封装,并调用封装后的minimize方法。
4、保存模型。主要用于保存分布式训练的模型。
单机单卡改多机多卡操作步骤
将单机单卡程序改成多机多卡的具体处理步骤如下所述。
1、导入分布式训练库
这里主要引入分布式Fleet API。 Fleet的设计在易于使用和算法可扩展性之间进行了权衡,并且非常高效。首先,用户可以在十行代码中,从本地机器桨式代码转换为分布式代码。其次,可以通过Fleet API设置分布式策略,从而轻松定义不同的算法。
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
2、定义训练策略和集群环境定义
这里需要定义分布式训练的相应策略,用于控制选取何种分布式方式以及相应的参数。详细的训练策略设定详见多机性能调优。集群环境这里推荐使用PaddleCloudRoleMaker并使用paddle.distributed.launch启动程序;这样,PaddleCloudRoleMaker可自动获取训练集群相关信息。情见如何运行多机多卡程序。
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
3、对optimizer封装,并调用封装后的minimize方法
这里主要将单机单卡的minimize方法转换为多机多卡的minimize方法。调用第二步封装后的optimizer的minimize方法。这里将optimizer转换为distributed_optimizer,其主要是对单机的optimizer增加了_transpile()的实现,对main_program进行转换(比如插入一些分布式的op等),主要是基于NCCL通信协议,实现梯度同步。
optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
optimizer.minimize(cost, fluid.default_startup_program())
4、保存模型
使用fleet.save_persistables 或fleet.inference_model保存模型。
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)
单机单卡改多机多卡代码示例
将单机单卡训练改成多机多卡训练的代码train_with_fleet.py示例如下。
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
# 区别1: 导入分布式训练库
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act=‘tanh‘)
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act=‘tanh‘)
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act=‘softmax‘)
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype(‘float32‘),
"y": np.random.randint(2, size=(128, 1)).astype(‘int64‘)}
input_x = fluid.layers.data(name="x", shape=[32], dtype=‘float32‘)
input_y = fluid.layers.data(name="y", shape=[1], dtype=‘int64‘)
# 定义损失
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
# 区别2: 定义训练策略和集群环境定义
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
# 区别3: 对optimizer封装,并调用封装后的minimize方法
optimizer = fleet.distributed_optimizer(optimizer, strategy=DistributedStrategy())
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 区别4: 模型保存
model_path = "./"
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)
运行多机多卡程序与单卡程序略有不同,需要通过特定的脚本在每一张卡上启动分布式程序,详情可看下一节内容。以单机八卡环境为例,采用默认的参数配置即可成功运行。方式如下:
config="--selected_gpus=0,1,2,3,4,5,6,7 --log_dir mylog"
python -m paddle.distributed.launch ${config} train.py
运行结果会在mylog文件夹中得到8个log日志,分别对应8张卡的运行结果。

以workerlog.0日志为例,会打印出该卡的运行结果。
如何运行多机多卡程序
多机多卡程序的运行一般依赖于相应的集群,不同集群环境,相应的运行方法有所不同。下面主要针对用户自定义集群和PaddleCloud集群来说明程序的运行方式。
说明
更多API使用实例以及更复杂的模型,可以参考 https://github.com/PaddlePaddle/Fleet
方式一:使用用户自定义集群
注意:
对于其它集群,用户需要知道集群中所有节点的IP地址。
需要使用paddle.distributed.launch模块启动训练任务,可以通过如下命令查看paddle.distributed.launch模块的使用方法。
python -m paddle.distributed.launch --help
用户只需要配置以下参数:
--cluster_node_ips: 集群中所有节点的IP地址列表,以‘,‘分隔,例如:192.168.1.2,192.168.1.3。
--node_ip: 当前节点的IP地址。
--started_port:起始端口号,假设起始端口号为51340,并且节点上使用的GPU卡数为4,那么GPU卡上对应训练进程的端口号分别为51340、51341和51342。务必确保端口号可用。
--selected_gpus:使用的GPU卡。
假设用户使用的训练集群包含两个节点(机器),IP地址分别为192.168.1.2和192.168.1.3,并且每个节点上使用的GPU卡数为4,那么在两个节点的终端上分别运行如下任务。
192.168.1.2节点
python -m paddle.distributed.launch \
--cluster_node_ips=192.168.1.2,192.168.1.3 \
--node_ip=192.168.1.2 \
--started_port=6170 \
--selected_gpus=0,1,2,3 \
train_with_fleet.py
192.168.1.3节点
python -m paddle.distributed.launch \
--cluster_node_ips=192.168.1.2,192.168.1.3 \
--node_ip=192.168.1.3 \
--started_port=6170 \
--selected_gpus=0,1,2,3 \
train_with_fleet.py
注意:
对于想在单机多卡运行程序的用户,可以直接采用默认参数运行多卡程序。命令是:
config="--selected_gpus=0,1,2,3,4,5,6,7 --log_dir mylog"
python -m paddle.distributed.launch ${config} train.py
方式二:使用PaddleCloud集群
针对百度内部用户,可以使用PaddleCloud集群运行多机多卡程序。关于如何使用PaddleCloud,请参考PaddleCloud官网:PaddleCloud官网。
注意:
对于PaddleCloud分布式训练,训练方式需要选择“分布式训练”,任务模式需要选择“NCCL2模式”,如下图所示。
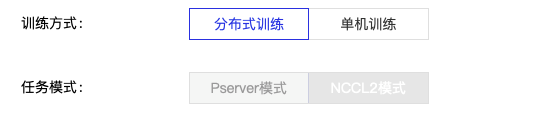
当采用客户端提交任务的方式时,需要通过以下命令行指定运行模式为“NCCL2模式”。
paddlecloud job \
... \
--is-standalone 0 \
--distribute-job-type NCCL2
需要将运行命令配置为如下命令:
start_cmd="python -m paddle.distributed.launch --use_paddlecloud --seletected_gpus=‘0,1,2,3,4,5,6,7‘ train_with_fleet.py --model=ResNet50 --data_dir=./ImageNet"
paddlecloud job \
--start-cmd "${start_cmd}" \
... \
--is-standalone 0 \
--distribute-job-type NCCL2
多机多卡模式下的性能调优
针对单机单卡改造成多机多卡第二步中的训练策略,使用默认的设置一般情况下可能无法达到最优的计算性能。
常见的性能调优设置
介绍一些提高分布式性能的调优设置。
设置环境变量


说明:
设置训练策略
训练参数设置表
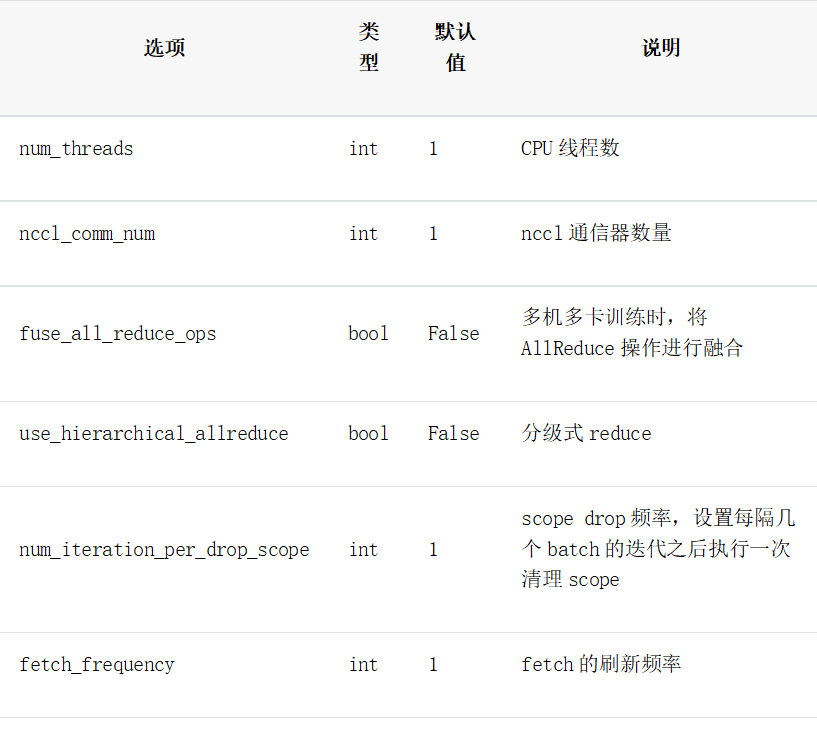
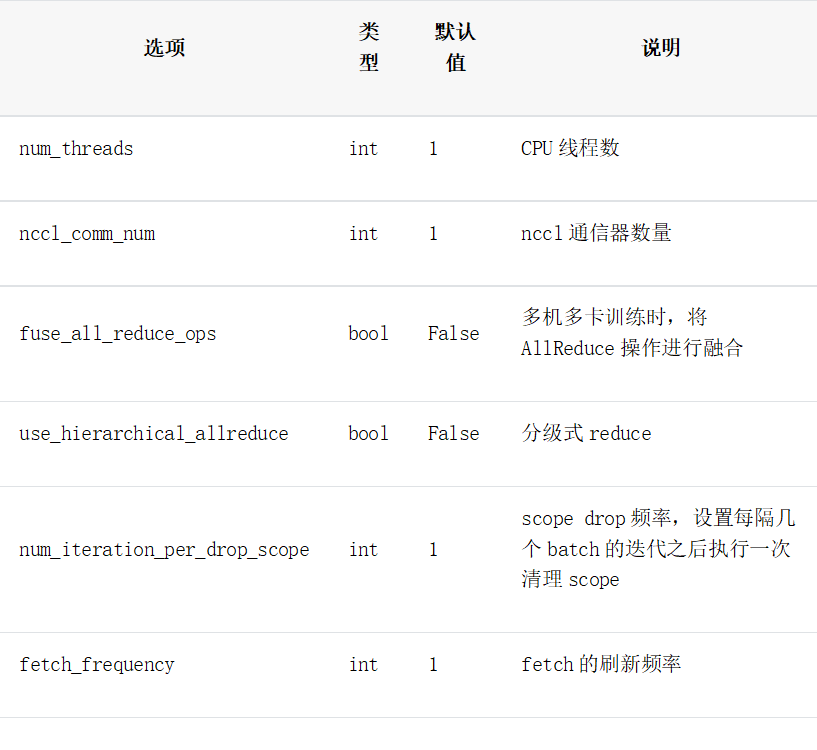
说明:
设置训练方式
GPU多机多卡同步训练过程中存在慢trainer现象,即每步中训练快的trainer的同步通信需要等待训练慢的trainer。 由于每步中慢trainer的rank具有随机性, 因此使用局部异步训练的方式——LocalSGD, 通过多步异步训练(无通信阻塞)实现慢trainer时间均摊, 从而提升同步训练性能,如下图所示:
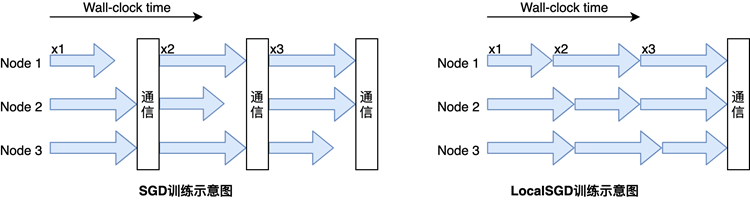
Local SGD训练方式主要有三个参数,分别是:


说明
性能调优代码示例
使用相应的分布式策略之后的多机多卡的代码示例如下。
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 调优策略的部分参数设置
# 建议多机设置为2,单机设置为1
nccl_comm_num = 2
# 建议多机设置为nccl_comm_num+1,单机设置为1
num_threads = 3
# scope drop频率
num_iteration_per_drop_scope = 30
#AllReduce是否融合
fuse_all_reduce_ops = True
# 刷新频率
fetch_frequency = 2
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act=‘tanh‘)
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act=‘tanh‘)
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act=‘softmax‘)
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype(‘float32‘),
"y": np.random.randint(2, size=(128, 1)).astype(‘int64‘)}
input_x = fluid.layers.data(name="x", shape=[32], dtype=‘float32‘)
input_y = fluid.layers.data(name="y", shape=[1], dtype=‘int64‘)
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
dist_strategy = DistributedStrategy()
dist_strategy.nccl_comm_num = nccl_comm_num
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = num_threads
exec_strategy.num_iteration_per_drop_scope = num_iteration_per_drop_scope
dist_strategy.exec_strategy = exec_strategy
dist_strategy.fuse_all_reduce_ops = fuse_all_reduce_ops
optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
# fetch频率
if i % fetch_frequency == 0:
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
else:
cost_val = exe.run(program=train_prog, feed=gen_data())
标签:started dia 环境变量 collect image data- type 用户 依赖
原文地址:https://www.cnblogs.com/wujianming-110117/p/14398486.html