标签:http io ar os sp for strong 数据 on
损失函数,一般由两项组成,一项是loss term,另外一项是regularization term。
J=L+R
先说损失项loss,再说regularization项。
1. 分对得分1,分错得分0.gold standard
2. hinge loss(for softmargin svm),J=1/2||w||^2 + sum(max(0,1-yf(w,x)))
3. log los, cross entropy loss function in logistic regression model.J=lamda||w||^2+sum(log(1+e(-yf(wx))))
4. squared loss, in linear regression. loss=(y-f(w,x))^2
5. exponential loss in boosting. J=lambda*R+exp(-yf(w,x))
caffe的损失函数,目前已经囊括了所有可以用的了吧,损失函数由最后一层分类器决定,同时有时会加入regularization,在BP过程中,使得误差传递得以良好运行。
contrastive_loss,对应contrastive_loss_layer,我看了看代码,这个应该是输入是一对用来做验证的数据,比如两张人脸图,可能是同一个人的(正样本),也可能是不同个人(负样本)。在caffe的examples中,siamese这个例子中,用的损失函数是该类型的。该损失函数具体数学表达形式:
euclidean_loss,对应euclidean_loss_layer,该损失函数就是l=(y-f(wx))^2
hinge_loss,对应hinge_loss_layer,该损失函数就是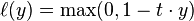 。主要用在SVM分类器中,
。主要用在SVM分类器中,
infogain_loss,对应infogain_loss_layer,损失函数表达式:
multinomial_logistic_loss,对应multinomial_logistic_loss_layer,损失函数表达式:
sigmoid_cross_entropy,对应sigmoid_cross_entropy_loss_layer,损失函数表达式:
softmax_loss,对应softmax_loss_layer,损失函数表达式:
references:
http://www.ics.uci.edu/~dramanan/teaching/ics273a_winter08/lectures/lecture14.pdf
https://github.com/BVLC/caffe
标签:http io ar os sp for strong 数据 on
原文地址:http://www.cnblogs.com/jianyingzhou/p/4094095.html