标签:-o time repr tput nta 包括 none eth state
scikit-learn中SVM的算法库分为两类,一类是分类的算法库,包括SVC, NuSVC,和LinearSVC 3个类。另一类是回归算法库,包括SVR, NuSVR,和LinearSVR 3个类。相关的类都包裹在sklearn.svm模块之中。
对于SVC, NuSVC,和LinearSVC 3个分类的类,SVC和 NuSVC差不多,区别仅仅在于对损失的度量方式不同,而LinearSVC从名字就可以看出,他是线性分类,也就是不支持各种低维到高维的核函数,仅仅支持线性核函数,对线性不可分的数据不能使用。
同样的,对于SVR, NuSVR,和LinearSVR 3个回归的类, SVR和NuSVR差不多,区别也仅仅在于对损失的度量方式不同。LinearSVR是线性回归,只能使用线性核函数。
优劣势:LinearSVC/LinearSVR 劣势是需要知道数据是可以线性可分的;优点是速度也快,不需要调整各种核函数即核函数的参数
SVC/SVR 劣势是需要调整各种核函数即核函数的参数;优点是不需要知道数据的分布
NuSVC,相对SVC/SVR,有参数可以调整训练集训练的错误率
Cfloat, default=1.0
Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. The penalty is a squared l2 penalty.
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’
Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable. If none is given, ‘rbf’ will be used. If a callable is given it is used to pre-compute the kernel matrix from data matrices; that matrix should be an array of shape (n_samples, n_samples).
核函数
0 – 线性:u‘v
1 – 多项式:(gamma*u‘*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u‘*v + coef0)
degreeint, default=3
Degree of the polynomial kernel function (‘poly’). Ignored by all other kernels.
多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma {‘scale’, ‘auto’} or float, default=’scale’
Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’.
if gamma=‘scale‘ (default) is passed then it uses 1 / (n_features * X.var()) as value of gamma,
if ‘auto’, uses 1 / n_features.
Changed in version 0.22: The default value of gamma changed from ‘auto’ to ‘scale’.
‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0 float, default=0.0
Independent term in kernel function. It is only significant in ‘poly’ and ‘sigmoid’.
核函数的常数项。对于‘poly’和 ‘sigmoid’有用
shrinking bool, default=True
Whether to use the shrinking heuristic. See the User Guide.
是否采用shrinking heuristic方法,默认为true
probability bool, default=False
Whether to enable probability estimates. This must be enabled prior to calling fit, will slow down that method as it internally uses 5-fold cross-validation, and predict_proba may be inconsistent with predict. Read more in the User Guide.
是否采用概率估计?.默认为False
tol float, default=1e-3
Tolerance for stopping criterion.
停止训练的误差值大小,默认为1e-3
cache_size float, default=200
Specify the size of the kernel cache (in MB).
核函数cache缓存大小,默认为200
class_weight dict or ‘balanced’, default=None
Set the parameter C of class i to class_weight[i]*C for SVC. If not given, all classes are supposed to have weight one. The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose bool, default=False
Enable verbose output. Note that this setting takes advantage of a per-process runtime setting in libsvm that, if enabled, may not work properly in a multithreaded context.
允许冗余输出?
max_iter int, default=-1
Hard limit on iterations within solver, or -1 for no limit.
最大迭代次数。-1为无限制。
decision_function_shape {‘ovo’, ‘ovr’}, default=’ovr’
Whether to return a one-vs-rest (‘ovr’) decision function of shape (n_samples, n_classes) as all other classifiers, or the original one-vs-one (‘ovo’) decision function of libsvm which has shape (n_samples, n_classes * (n_classes - 1) / 2). However, one-vs-one (‘ovo’) is always used as multi-class strategy. The parameter is ignored for binary classification.
Changed in version 0.19: decision_function_shape is ‘ovr’ by default.
New in version 0.17: decision_function_shape=’ovr’ is recommended.
Changed in version 0.17: Deprecated decision_function_shape=’ovo’ and None.
break_ties bool, default=False
If true, decision_function_shape=‘ovr‘, and number of classes > 2, predict will break ties according to the confidence values of decision_function; otherwise the first class among the tied classes is returned. Please note that breaking ties comes at a relatively high computational cost compared to a simple predict.
New in version 0.22.
random_state int, RandomState instance or None, default=None
Controls the pseudo random number generation for shuffling the data for probability estimates. Ignored when probability is False. Pass an int for reproducible output across multiple function calls. See Glossary.
总结:
针对不同的核函数:
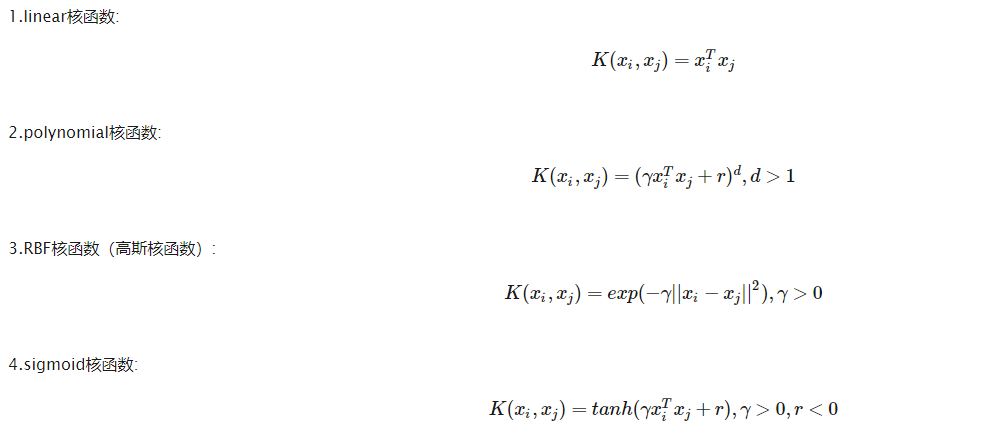
1)对于线性核函数,没有专门需要设置的参数
2)对于多项式核函数,有三个参数。-d用来设置多项式核函数的最高次项次数,也就是公式中的d,默认值是3。-g用来设置核函数中的gamma参数设置,也就是公式中的gamma,默认值是1/k(特征数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
3)对于RBF核函数,有一个参数。-g用来设置核函数中的gamma参数设置,也就是公式中gamma,默认值是1/k(k是特征数)。
4)对于sigmoid核函数,有两个参数。-g用来设置核函数中的gamma参数设置,也就是公式中gamma,默认值是1/k(k是特征数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
除以上核函数参数,需要设置的参数为C、random_state、max_iter、class_weight(数据不均衡时设置)
具体来说说rbf核函数中C和gamma :
SVM模型有两个非常重要的参数C与gamma。其中 C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。
这里面大家需要注意的就是gamma的物理意义,大家提到很多的RBF的幅宽,它会影响每个支持向量对应的高斯的作用范围,从而影响泛化性能。我的理解:如果gamma设的太大,方差会很小,方差很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让方差无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
此外,可以明确的两个结论是:
结论1:样本数目少于特征维度并不一定会导致过拟合,这可以参考余凯老师的这句评论:
“这不是原因啊,呵呵。用RBF kernel, 系统的dimension实际上不超过样本数,与特征维数没有一个trivial的关系。”
结论2:RBF核应该可以得到与线性核相近的效果(按照理论,RBF核可以模拟线性核),可能好于线性核,也可能差于,但是,不应该相差太多。
当然,很多问题中,比如维度过高,或者样本海量的情况下,大家更倾向于用线性核,因为效果相当,但是在速度和模型大小方面,线性核会有更好的表现
标签:-o time repr tput nta 包括 none eth state
原文地址:https://www.cnblogs.com/pyclq/p/14442365.html