标签:重要 完成后 并保存 nal 技术 框架搭建 alt 神经网络结构 href
为解决前馈神经网络中出现的问题,黄广斌教授等提出了极限学习机(ELM) 算法。ELM 算法是在 SLFNs 算法基础上发展的,当 ELM 算法的激活函数无限可微,ELM 的隐藏层输出矩阵 H 可以不受迭代训练的影响,保持不变。选取合适的输入权重????和隐含层的阈值????,ELM 算法可以达到零误差逼近实际输出值的效果。极限学习机的数学原理是最小二乘法,在此不进行探讨,感兴趣的自行查询资料。
总结极限学习机的特点:
1.三层网络结构,只需初始化隐含层的权重和偏置,输出层的权重计算可得;
2.输出层矩阵 beta= 隐藏层输出矩阵的广义逆H+ * 训练集标签的转置矩阵Y’ ;
3.训练速度快,不需要通过迭代来不断调整神经网络的参数;
4.隐藏层激活函数的选择,隐藏层激活函数对 ELM 的模型的泛化性能具有重要的影响,选择合适的激活函数对 ELM 算法非常重要;
5.ELM 隐藏层节点数以及激活函数的参数会对 ELM 算法产生一定的影响;
6.ELM 的建立比较依赖训练数据,因为 ELM 网络模型训练完成后不再调整参数,所以训练数据集对 ELM 的参数影响较大。减少训练数据集的随机性以及数据中的噪声,有助于提高 ELM 模型的性能。
如果需要ELM的其他代码可以到黄教授的官网去找,指路 https://www3.ntu.edu.sg/home/egbhuang/elm_codes.html
二、重点代码讲解
1.关于数据处理,请参照我上一篇随笔,步骤是一样的;
2.如何求beta矩阵
H = np.linalg.pinv(hiddenout.data.numpy().reshape(len(y_train),5)) #求广义逆 T = y_train.data.numpy().reshape(len(y_train)) #矩阵转置 beta = np.dot(H,T) #矩阵相乘
np.linalg.pinv()是numpy模块中的求矩阵广义逆的方法;
numpy().reshape()是对矩阵的维度进行编辑以符合矩阵相乘的要求;
np.dot()使两个矩阵相乘。
因为我们是用pytorch框架搭建的神经网络,所以需要对NN中的参数进行自定义初始化。遍历参数的方式有3种,module.parameters()是网络中的参数、module.named_parameters()包含参数名和参数值、
module.state_dict()主要用于保存参数值到文件中。这三种方式都可以遍历并修改其中的值,例如:
for param in module.parameters():
print(param)
param.data.fill_(update_param)
print(param)
对于一些参数较少的网络这个方式可以,但是对于参数很多的网络既不方便还可能出错,所以我用的是另一种方式。
module.state_dict()[‘name‘].copy_(update_value)
因为state_dict()是以字典的方式存储的,所以可以通过键值索引来修改其中的value,然后保存到文件中,再用load()函数调用即可。
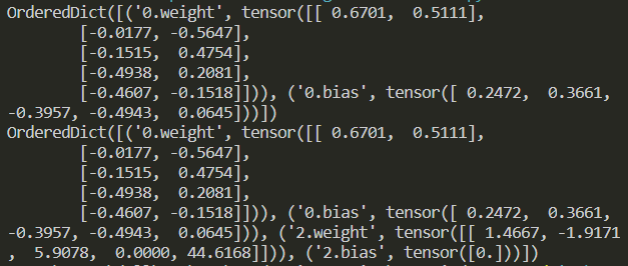
图为参数字典的输出结果
搭建极限学习机网络
# 神经网络结构
net = torch.nn.Sequential(
torch.nn.Linear(2, 5),
torch.nn.ReLU(),
torch.nn.Linear(5, 1),
torch.nn.Softplus()
)
计算β矩阵并保存参数
def save():
ihlayer = torch.nn.Sequential(
torch.nn.Linear(2, 5),
torch.nn.ReLU()
)
hiddenout = ihlayer(xtrain).squeeze(-1)
H = np.linalg.pinv(hiddenout.data.numpy().reshape(len(y_train),5)) #求广义逆
T = y_train.data.numpy().reshape(len(y_train)) #矩阵转置
beta = np.dot(H,T) #矩阵相乘
beta = torch.tensor(beta).float()
#print(ihlayer.state_dict())
net.state_dict()[‘0.weight‘].copy_(ihlayer.state_dict()[‘0.weight‘])
net.state_dict()[‘0.bias‘].copy_(ihlayer.state_dict()[‘0.bias‘])
net.state_dict()[‘2.weight‘].copy_(beta)
net.state_dict()[‘2.bias‘].copy_(torch.tensor(0))
#print(net.state_dict())
# 保存神经网络
torch.save(net.state_dict(), ‘elmnet_params.pkl‘) # 只保存神经网络的模型参数
调用参数并进行预测
# 只载入神经网络的模型参数,神经网络的结构需要与保存的神经网络相同的结构 def reload_params(): net.load_state_dict(torch.load(‘elmnet_params.pkl‘)) prediction = net(xtest) prediction = prediction.squeeze(-1) #plt.subplot(133) plt.title(‘net‘) plt.scatter(ytest.data.numpy(), prediction.data.numpy()) plt.plot(ytest.data.numpy(), ytest.data.numpy(),‘r--‘) plt.show()
预测结果如图:
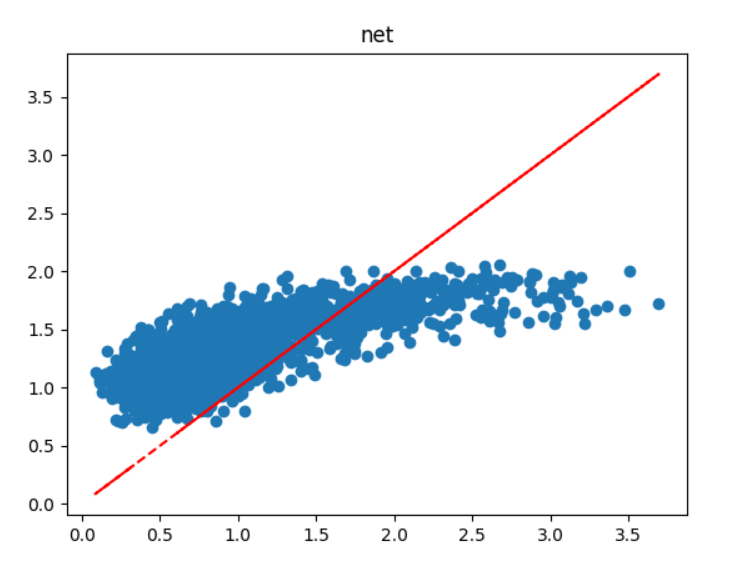
预测结果欠佳,看来还是要需要优化。
机器学习阶段小结(三)—用PyTorch搭建极限学习机(ELM)
标签:重要 完成后 并保存 nal 技术 框架搭建 alt 神经网络结构 href
原文地址:https://www.cnblogs.com/lemon-567/p/14483166.html