标签:children 安装 style *** info 相关 内存 电影 src
BeautifulSoup4库:
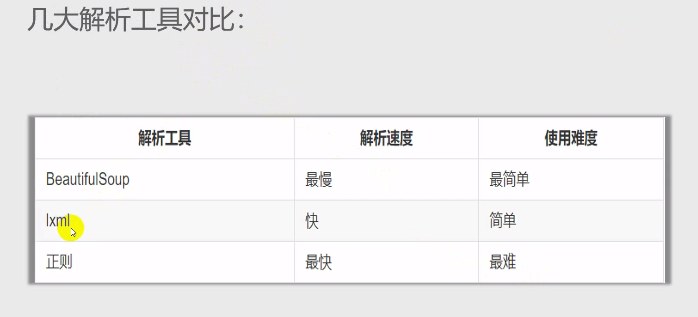
和lxml一样,Beautiful Soup也是一个HTML/XML的解析器,主要的功能也是如何解析和提取HTML/XML数据。
lxml只会局部遍历,而Beautiful Soup是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml
bs4库不是python自带的标准库,需要安装
pip install bs4
注意:bs3目前已经停止开发,推荐现在的项目使用bs4
DOM树:
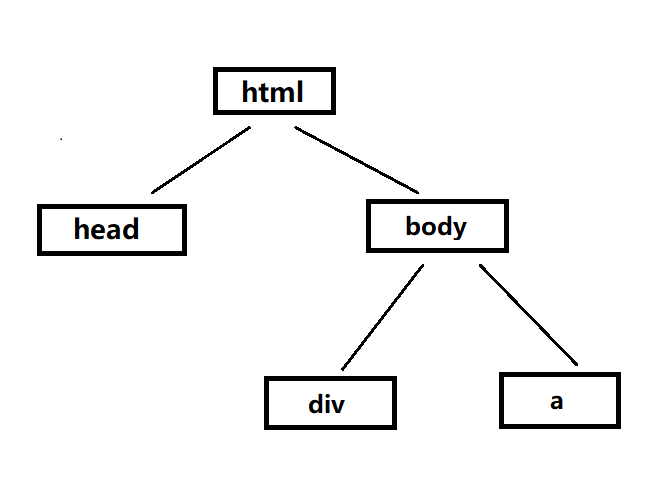
四种常见的对象讲解:
1.Tag:
Tag通俗点讲就是HTML中的一个个标签。我们可以利用soup加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,它查找的是在所有内容中第一个符合要求的标签
2.NavigableString:
如果拿到标签后,还想获取标签中的内容。那么可以通过tag.string获取标签中的文字
3.BeautifulSoup:
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当作Tag对象,它支持遍历文档树和搜索文档树中描述的大部分的方法
4.Comment:
Tag,NavigableString,BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象,容易让人担心的内容是文档的注释部分。
Comment对象是一个特殊类型的NavigableString对象
通过bs4,获取符合要求的标签(每一个类型都是bs4.element.Tag)
# 获取符合要求的标签(每一个类型都是bs4.element.Tag) from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") print(soup) # 通过Tag打印title标签 print("title标签:{0}\t类型:{1}".format(soup.title,type(soup.title))) # 通过Tag打印p标签(当有多个p标签时,只会打印符合要求的第一个p标签) print("p标签:{0}\t类型:{1}".format(soup.p,type(soup.p)),end="\n\n") print("p标签属性名:{}".format(soup.p.name)) print("p标签所有属性:{}".format(soup.p.attrs)) print("第一种打印p属性的class值:{}".format(soup.p["class"])) print("第二种打印p属性的class值2:{}".format(soup.p.get("class"))) # 修改p标签class属性的值 soup.p["class"] = "newclass" print("修改后的p标签所有属性:",soup.p.attrs) print("修改后的p标签:",soup.p)
在得到标签后,获取标签中的内容(每一个类型都是bs4.element.NavigableString)
# 在得到标签后,获取标签中的内容(每一个类型都是bs4.element.NavigableString) from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") # 通过Tag,获取title标签 title = soup.title print("获取到的title标签:{0}\t类型:{1}".format(title,type(title))) # 通过tag.string获取标题标签中的内容(bs4.element.NavigableString类型是继承str类型) content = title.string print("title标签中的内容:{0}\t类型:{1}".format(content,type(content))) # 通常情况下,采用这种形式来写,比较简洁 print("title标签中的内容:{0}\t类型:{1}".format(soup.title.string,type(soup.title.string)))
获取到注释的内容(同上,与获取标签中的内容方法类似)
# 获取到注释的内容 from bs4 import BeautifulSoup # html最后一段加上注释 html = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> <b><!--Hey,buddy.Want to buy a used parser?--></b> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") print(soup) # 打印注释内容(bs4.element.Comment类型) print("\nb标签注释部分:{0}\t类型:{1}".format(soup.b.string,type(soup.b.string)))
===============================================================================================
需要注意,从这里我们开始学习遍历文档树和搜索文档树的相关内容
1.遍历文档树:
1>.contents和children:
contents:返回所有子节点的列表
children:返回所有子节点的迭代器
返回某个标签下的直接子元素,其中也包括字符串。他们俩的区别是:contents返回来的是一个列表,children返回的是一个迭代器。
# contents和children from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> <b><!--Hey,buddy.Want to buy a used parser?--></b> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") # 选取head节点 head_tag = soup.head # contents,返回所有子节点的列表 print("contents:",head_tag.contents) # children,返回所有子节点的迭代器 print("children:",head_tag.children) # 打印迭代器里面的内容 for child in head_tag.children: print(child)
2>.strings和stripped_strings
strings:如果tag中包含多个字符串,可以使用.strings来循环获取
stripped_strings:输出的字符串中可能包含了很多空格或空行,使用.stripped_strings可以去除多余空白内容
强调重点:分析string和strings、stripped_strings属性:
1.string:获取了某个标签下的非标签字符串。返回来的是个字符串。如果这个标签下有多行字符串,那么就不能获取到了
2.strings:获取某个标签下的子孙非标签字符串,返回来的是一个生成器。
3.stripped_strings:获取某个标签下的子孙非标签字符串,会去掉空白字符。返回来的是一个生成器。
# strings和stripped_strings from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> <b><!--Hey,buddy.Want to buy a used parser?--></b> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") # strings,获取soup里面所有的文字内容/字符串 for string in soup.strings: print(string) # stripped_strings,也是获取soup里面所有的文字内容/字符串,但是可以去除多余空格或空行 for string2 in soup.stripped_strings: print(string2)
2.搜索文档树:
1>.find和find_all方法:
搜索文档树,一般用得比较多的就是两个方法,一个是find,一个是find_all。
find方法是找到第一个满足条件的标签后就立即返回,只返回一个元素。
find_all方法是把所有满足条件的标签都选到,然后返回回去
使用find和find_all的过滤条件
关键字参数:将属性的名字作为关键字参数的名字,以及属性的值作为关键字参数的值进行过滤
attrs参数:将属性条件放到一个字典中,传给attrs参数。
# bs4获取符合条件的标签(find和find_all) from bs4 import BeautifulSoup html = """ <table class="tablelist" cellpadding="0" cellspacing="0"> <tbody> <tr class="h"> <td class="l" width="374">职位名称</td> <td>职位类别</td> <td>人数</td> <td>地点</td> <td>发布时间</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td> <td>技术类</td> <td>4</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a id="test" class="test" target=‘_blank‘ href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> </tbody> </table> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") # 1.获取所有tr标签 print("获取第一个tr标签:\n{}".format(soup.find("tr"))) print("获取所有tr标签:") tr_list = soup.find_all("tr") for tr in tr_list: print(tr) print("------------------------------------") # 2.获取第二个tr标签(limit参数,是获取前两个tr标签) tr_list = soup.find_all("tr",limit=2) print("获取第二个tr标签:\n{}".format(tr_list[1])) # 3.获取所有class等于even的tr标签 print("获取所有class等于even的tr标签:") # tr_list = soup.find_all("tr",class_="even") tr_list = soup.find_all("tr",attrs={"class":"even"}) for tr in tr_list: print(tr) print("*************************************") # 4.将所有id等于test,class也等于test的a标签提取出来 print("将所有id等于test,class也等于test的a标签提取出来:") a_list = soup.find_all("a",attrs={"id":"test","class":"test"}) for a in a_list: print(a) # 5.获取所有a标签的href属性 print("获取所有a标签的href属性:") # a_list = soup.find_all("a") # a_list = [a["href"] for a in a_list] # print(a_list) a_list = soup.find_all("a") a_list = [a.attrs["href"] for a in a_list] print(a_list) # 6.获取所有的职位信息(纯文本) print("获取所有的职位信息:") position_all = [] # 职位标题信息 tr_title = soup.find("tr") # td_title = tr_title.find_all("td") # td_title = [td.string for td in td_title] td_title = list(tr_title.stripped_strings) # 职位信息不包括第一个标题tr标签 tr_list = soup.find_all("tr")[1::] for tr in tr_list: # td_list = tr.find_all("td") # td_list = [td.string for td in td_list] td_list = list(tr ) position_data = dict(zip(td_title,td_list)) position_all.append(position_data) print(position_all)
2>.select方法:
有时候选择css选择器的方式可以更加的方便。使用css选择器的语法,应该使用select方法。以下列出几种常用的css选择器方法:
(1)通过标签名查找:print(soup.select("a"))
(2)通过类名查找:print(soup.select(".sister"))
(3)通过id查找:print(soup.select("#link1"))
(4)组合查找:print("p#link1")
(5)通过属性查找:print("soup.select(‘http://example.com.elsie‘)")
(6)获取内容:print(soup.select("title")[0].get_text())
# bs4获取符合条件的标签(select) from bs4 import BeautifulSoup html = """ <table class="tablelist" cellpadding="0" cellspacing="0"> <tbody> <tr class="h"> <td class="l" width="374">职位名称</td> <td>职位类别</td> <td>人数</td> <td>地点</td> <td>发布时间</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td> <td>技术类</td> <td>4</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="even"> <td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr class="odd"> <td class="l square"><a id="test" class="test" target=‘_blank‘ href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> </tbody> </table> """ # 创建一个BeautifulSoup对象,指定解析器为lxml(lxml HTML解析器的优势:速度快,文档容错能力强) soup = BeautifulSoup(html,"lxml") # 1.获取所有tr标签 print("获取所有tr标签:") tr_list = soup.select("tr") for tr in tr_list: print(tr) print("------------------------------------") # 2.获取第二个tr标签(limit参数,是获取前两个tr标签) tr_list = soup.select("tr")[1] print("获取第二个tr标签:\n{}".format(tr_list)) # 3.获取所有class等于even的tr标签 print("获取所有class等于even的tr标签:") tr_list = soup.select("tr[class=‘even‘]") for tr in tr_list: print(tr) print("*************************************") # 4.将所有id等于test,class也等于test的a标签提取出来 print("将所有id等于test,class也等于test的a标签提取出来:") # a_list = soup.select("a#test.test")[0] a_list = soup.select("a[class=‘test‘][id=‘test‘]")[0] print(a_list) # 5.获取所有a标签的href属性 print("获取所有a标签的href属性:") a_list = soup.select("a") a_href = [a["href"] for a in a_list] print(a_href) # 6.获取所有的职位信息(纯文本) print("获取所有的职位信息:") trs = soup.select("tr") for tr in trs: info = list(tr.stripped_strings) print(info)
爬虫实战:豆瓣TOP250榜单(利用requests)
# 豆瓣TOP250实战 import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent import time # 请求头的headers user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome } # # 请求头的proxies,设置ip代理 # proxies={ # "http":"222.186.180.84:19064" # } # 获取详情页面url(bs4) def get_detail_urls(html): soup = BeautifulSoup(html,‘lxml‘) li_list = soup.find_all("ol",attrs={"class":"grid_view"})[0].find_all("li") detail_urls = [x.find_all("a")[0]["href"] for x in li_list] return detail_urls # 解析详情页面内容(电影名、导演、编剧、演员、豆瓣评分) def parse_detail_url(detail_url,f): # 解析每一个详情页面内容(timeout:为防止服务器不能及时响应,加入timeout限制请求时间) # response_detail = requests.get(detail_url,headers=headers,proxies=proxies,timeout=(3,7)) response_detail = requests.get(detail_url,headers=headers,timeout=(3,7)) html_detail = response_detail.content.decode("utf-8") soup_detail = BeautifulSoup(html_detail,"lxml") # 1.获取电影名 name = list(soup_detail.find_all("div",attrs={"id":"content"})[0].find_all("h1")[0].stripped_strings) # join,将序列中的元素以指定的字符连接生成一个新的字符串 name = "-".join(name) print("电影名:",name) # 2.获取导演 director = list(soup_detail.find_all("div",attrs={"id":"info"})[0].find_all("span")[0].find_all("span",attrs={"class":"attrs"})[0].stripped_strings)[0] print("导演:",director) # 3.获取编剧 screenwriter = list(soup_detail.find_all("div",attrs={"id":"info"})[0].find_all("span")[3].find_all("span",attrs={"class":"attrs"})[0].stripped_strings) screenwriter = "".join(screenwriter) print("编剧:",screenwriter) # 4.获取演员 actor = list(soup_detail.find_all("div",attrs={"id":"info"})[0].find_all("span",attrs={"class":"actor"})[0].find_all("span",attrs={"class":"attrs"})[0].stripped_strings) actor = "".join(actor) print("主演:",actor) # 5.获取评分 score = list(soup_detail.find_all("div",attrs={"class":"rating_self clearfix"})[0].find_all("strong",attrs={"class":"ll rating_num"})[0].stripped_strings)[0] print("豆瓣评分:",score) # 6.写入文件f(电影名、导演、编剧、演员、豆瓣评分) f.write("{0},{1},{2},{3},{4}\n".format(name,director,screenwriter,actor,score)) def main(): page = int(input("请输入要爬取豆瓣Top的第几页:"))-1 # 第一个url,豆瓣TOP250 (timeout:为防止服务器不能及时响应,加入timeout限制请求时间) url = "https://movie.douban.com/top250?start={}".format(page*25) # 保存文件到"F:/爬虫/第三章-xpath库/Top250.csv" (newline=""消除多余空行,添加ignore忽略报错) with open(r"F:/爬虫/第三章-xpath库/Top250.csv","a",encoding="gbk",newline="",errors="ignore") as f: f.write("电影名,导演,编剧,演员,豆瓣评分\n") # resp = requests.get(url,headers=headers,proxies=proxies,timeout=(3,7)) resp = requests.get(url,headers=headers,timeout=(3,7)) html = resp.content.decode("utf-8") # 调用,获取详情页面url(bs4) detail_urls = get_detail_urls(html) for detail_url in detail_urls: # time.sleep()推迟调用线程的运行 time.sleep(1) # 调用,解析详情页面内容(电影名、导演、编剧、演员、豆瓣评分) parse_detail_url(detail_url,f) if __name__ == "__main__": main()
标签:children 安装 style *** info 相关 内存 电影 src
原文地址:https://www.cnblogs.com/REN-Murphy/p/14485503.html