标签:+= shuf python compile build 文件 image sys sse
在nlp领域,预训练模型bert可谓是红得发紫。
但现在能搜到的大多数都是pytorch写的框架,而且大多都是单输出模型。
所以,本文以 有相互关系的多层标签分类 为背景,用keras设计了多输出、参数共享的模型。
def batch_iter(data_path, cat_to_id, tokenizer, batch_size=64, shuffle=True):
"""生成批次数据"""
keras_bert_iter = get_keras_bert_iterator(data_path, cat_to_id, tokenizer)
while True:
data_list = []
for _ in range(batch_size):
data = next(keras_bert_iter)
data_list.append(data)
if shuffle:
random.shuffle(data_list)
indices_list = []
segments_list = []
label_index_list = []
for data in data_list:
indices, segments, label_index = data
indices_list.append(indices)
segments_list.append(segments)
label_index_list.append(label_index)
yield [np.array(indices_list), np.array(segments_list)], np.array(label_index_list)
def get_model(label_list):
K.clear_session()
bert_model = load_trained_model_from_checkpoint(bert_paths.config, bert_paths.checkpoint, seq_len=text_max_length) #加载预训练模型
for l in bert_model.layers:
l.trainable = True
input_indices = Input(shape=(None,))
input_segments = Input(shape=(None,))
bert_output = bert_model([input_indices, input_segments])
bert_cls = Lambda(lambda x: x[:, 0])(bert_output) # 取出[CLS]对应的向量用来做分类
output = Dense(len(label_list), activation=‘softmax‘)(bert_cls)
model = Model([input_indices, input_segments], output)
model.compile(loss=‘sparse_categorical_crossentropy‘,
optimizer=Adam(1e-5), #用足够小的学习率
metrics=[‘accuracy‘])
print(model.summary())
return model
early_stopping = EarlyStopping(monitor=‘val_acc‘, patience=3) #早停法,防止过拟合
plateau = ReduceLROnPlateau(monitor="val_acc", verbose=1, mode=‘max‘, factor=0.5, patience=2) #当评价指标不在提升时,减少学习率
checkpoint = ModelCheckpoint(‘trained_model/keras_bert_THUCNews.hdf5‘, monitor=‘val_acc‘,verbose=2, save_best_only=True, mode=‘max‘, save_weights_only=True) #保存最好的模型
def get_step(sample_count, batch_size):
step = sample_count // batch_size
if sample_count % batch_size != 0:
step += 1
return step
batch_size = 4
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, batch_size)
dev_dataset_iterator = batch_iter(r"data/keras_bert_dev.txt", cat_to_id, tokenizer, batch_size)
model = get_model(categories)
#模型训练
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau, checkpoint],
verbose=1
)
def batch_iter(data_path, cat_to_id, tokenizer, second_label_list, batch_size=64, shuffle=True):
"""生成批次数据"""
keras_bert_iter = get_keras_bert_iterator(data_path, cat_to_id, tokenizer, second_label_list)
while True:
data_list = []
for _ in range(batch_size):
data = next(keras_bert_iter)
data_list.append(data)
if shuffle:
random.shuffle(data_list)
indices_list = []
segments_list = []
label_index_list = []
second_label_list = []
for data in data_list:
indices, segments, label_index, second_label = data
indices_list.append(indices)
segments_list.append(segments)
label_index_list.append(label_index)
second_label_list.append(second_label)
yield [np.array(indices_list), np.array(segments_list)], [np.array(label_index_list), np.array(second_label_list)]
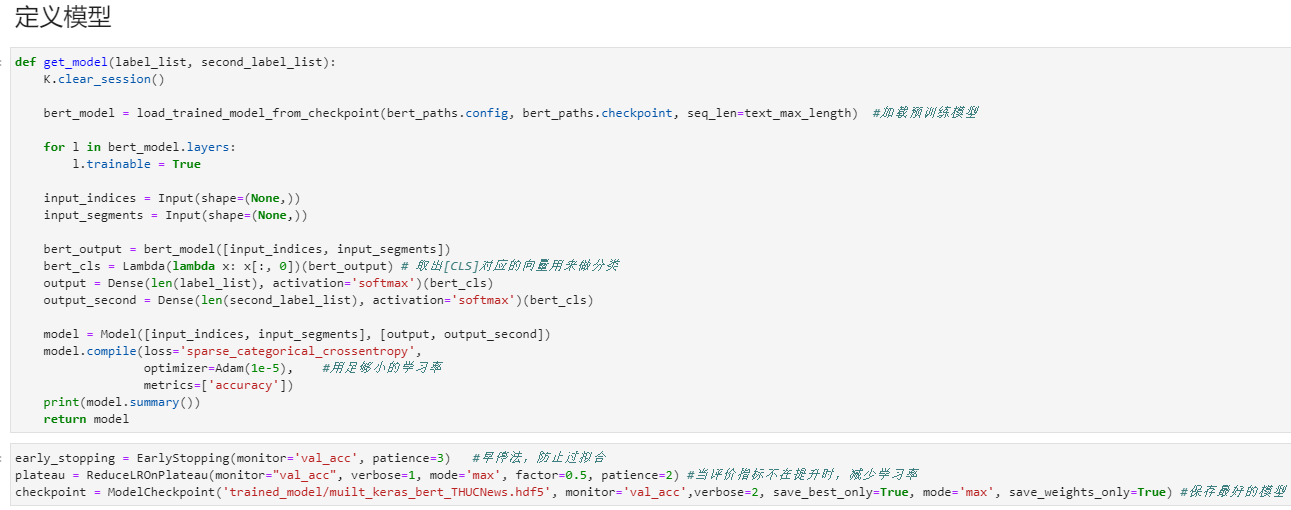
def get_model(label_list, second_label_list):
K.clear_session()
bert_model = load_trained_model_from_checkpoint(bert_paths.config, bert_paths.checkpoint, seq_len=text_max_length) #加载预训练模型
for l in bert_model.layers:
l.trainable = True
input_indices = Input(shape=(None,))
input_segments = Input(shape=(None,))
bert_output = bert_model([input_indices, input_segments])
bert_cls = Lambda(lambda x: x[:, 0])(bert_output) # 取出[CLS]对应的向量用来做分类
output = Dense(len(label_list), activation=‘softmax‘)(bert_cls)
output_second = Dense(len(second_label_list), activation=‘softmax‘)(bert_cls)
model = Model([input_indices, input_segments], [output, output_second])
model.compile(loss=‘sparse_categorical_crossentropy‘,
optimizer=Adam(1e-5), #用足够小的学习率
metrics=[‘accuracy‘])
print(model.summary())
return model
batch_size = 4
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, second_label_list, batch_size)
dev_dataset_iterator = batch_iter(r"data/keras_bert_dev.txt", cat_to_id, tokenizer, second_label_list, batch_size)
model = get_model(categories, second_label_list)
#模型训练
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau, checkpoint],
verbose=1
)
import os
import sys
import re
from collections import Counter
import random
from tqdm import tqdm
import numpy as np
import tensorflow.keras as keras
from keras_bert import load_vocabulary, load_trained_model_from_checkpoint, Tokenizer, get_checkpoint_paths
from keras_bert.layers import MaskedGlobalMaxPool1D
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
from keras.metrics import top_k_categorical_accuracy
from keras.layers import *
from keras.callbacks import *
from keras.models import Model
import keras.backend as K
from keras.optimizers import Adam
from keras.utils import to_categorical
data_path = "000_text_classifier_tensorflow_textcnn/THUCNews/"
text_max_length = 512
bert_paths = get_checkpoint_paths(r"chinese_L-12_H-768_A-12")
def _read_file(filename):
"""读取一个文件并转换为一行"""
with open(filename, ‘r‘, encoding=‘utf-8‘) as f:
s = f.read().strip().replace(‘\n‘, ‘。‘).replace(‘\t‘, ‘‘).replace(‘\u3000‘, ‘‘)
return re.sub(r‘。+‘, ‘。‘, s)
def get_data_iterator(data_path):
for category in os.listdir(data_path):
category_path = os.path.join(data_path, category)
for file_name in os.listdir(category_path):
yield _read_file(os.path.join(category_path, file_name)), category
it = get_data_iterator(data_path)
next(it)
(‘竞彩解析:日本美国争冠死磕 两巴相逢必有生死。周日受注赛事,女足世界杯决赛、美洲杯两场1/4决赛毫无疑问是全世界球迷和彩民关注的焦点。本届女足世界杯的最大黑马日本队能否一黑到底,创造亚洲奇迹?女子足坛霸主美国队能否再次“灭黑”成功,成就三冠伟业?巴西、巴拉圭冤家路窄,谁又能笑到最后?诸多谜底,在周一凌晨就会揭晓。日本美国争冠死磕。本届女足世界杯,是颠覆与反颠覆之争。夺冠大热门东道主德国队1/4决赛被日本队加时赛一球而“黑”,另一个夺冠大热门瑞典队则在半决赛被日本队3:1彻底打垮。而美国队则捍卫着女足豪强的尊严,在1/4决赛,她们与巴西女足苦战至点球大战,最终以5:3淘汰这支迅速崛起的黑马球队,而在半决赛,她们更是3:1大胜欧洲黑马法国队。美日两队此次世界杯进程惊人相似,小组赛前两轮全胜,最后一轮输球,1/4决赛同样与对手90分钟内战成平局,半决赛竟同样3:1大胜对手。此次决战,无论是日本还是美国队夺冠,均将创造女足世界杯新的历史。两巴相逢必有生死。本届美洲杯,让人大跌眼镜的事情太多。巴西、巴拉圭冤家路窄似乎更具传奇色彩。两队小组赛同分在B组,原本两个出线大热门,却双双在前两轮小组赛战平,两队直接交锋就是2:2平局,结果双双面临出局危险。最后一轮,巴西队在下半场终于发威,4:2大胜厄瓜多尔后来居上以小组第一出线,而巴拉圭最后一战还是3:3战平委内瑞拉获得小组第三,侥幸凭借净胜球优势挤掉A组第三名的哥斯达黎加,获得一个八强席位。在小组赛,巴西队是在最后时刻才逼平了巴拉圭,他们的好运气会在淘汰赛再显神威吗?巴拉圭此前3轮小组赛似乎都缺乏运气,此番又会否被幸运之神补偿一下呢?。另一场美洲杯1/4决赛,智利队在C组小组赛2胜1平以小组头名晋级八强;而委内瑞拉在B组是最不被看好的球队,但竟然在与巴西、巴拉圭同组的情况下,前两轮就奠定了小组出线权,他们小组3战1胜2平保持不败战绩,而入球数跟智利一样都是4球,只是失球数比智利多了1个。但既然他们面对强大的巴西都能保持球门不失,此番再创佳绩也不足为怪。‘,
‘彩票‘)
def read_category(data_path):
"""读取分类目录,固定"""
categories = os.listdir(data_path)
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
categories, cat_to_id = read_category(data_path)
cat_to_id
{‘彩票‘: 0,
‘家居‘: 1,
‘游戏‘: 2,
‘股票‘: 3,
‘科技‘: 4,
‘社会‘: 5,
‘财经‘: 6,
‘时尚‘: 7,
‘星座‘: 8,
‘体育‘: 9,
‘房产‘: 10,
‘娱乐‘: 11,
‘时政‘: 12,
‘教育‘: 13}
categories
[‘彩票‘,
‘家居‘,
‘游戏‘,
‘股票‘,
‘科技‘,
‘社会‘,
‘财经‘,
‘时尚‘,
‘星座‘,
‘体育‘,
‘房产‘,
‘娱乐‘,
‘时政‘,
‘教育‘]
def build_dataset(data_path, train_path, dev_path, test_path):
data_iter = get_data_iterator(data_path)
with open(train_path, ‘w‘, encoding=‘utf-8‘) as train_file, open(dev_path, ‘w‘, encoding=‘utf-8‘) as dev_file, open(test_path, ‘w‘, encoding=‘utf-8‘) as test_file:
for text, label in tqdm(data_iter):
radio = random.random()
if radio < 0.8:
train_file.write(text + "\t" + label + "\n")
elif radio < 0.9:
dev_file.write(text + "\t" + label + "\n")
else:
test_file.write(text + "\t" + label + "\n")
# build_dataset(data_path, r"data/keras_bert_train.txt", r"data/keras_bert_dev.txt", r"data/keras_bert_test.txt")
def get_sample_num(data_path):
count = 0
with open(data_path, ‘r‘, encoding=‘utf-8‘) as data_file:
for line in tqdm(data_file):
count += 1
return count
train_sample_count = get_sample_num(r"data/keras_bert_train.txt")
668858it [00:09, 67648.27it/s]
dev_sample_count = get_sample_num(r"data/keras_bert_dev.txt")
83721it [00:01, 61733.96it/s]
test_sample_count = get_sample_num(r"data/keras_bert_test.txt")
83496it [00:01, 72322.53it/s]
train_sample_count, dev_sample_count, test_sample_count
(668858, 83721, 83496)
def get_text_iterator(data_path):
with open(data_path, ‘r‘, encoding=‘utf-8‘) as data_file:
for line in data_file:
data_split = line.strip().split(‘\t‘)
if len(data_split) != 2:
print(line)
continue
yield data_split[0], data_split[1]
it = get_text_iterator(r"data/keras_bert_train.txt")
next(it)
(‘竞彩解析:日本美国争冠死磕 两巴相逢必有生死。周日受注赛事,女足世界杯决赛、美洲杯两场1/4决赛毫无疑问是全世界球迷和彩民关注的焦点。本届女足世界杯的最大黑马日本队能否一黑到底,创造亚洲奇迹?女子足坛霸主美国队能否再次“灭黑”成功,成就三冠伟业?巴西、巴拉圭冤家路窄,谁又能笑到最后?诸多谜底,在周一凌晨就会揭晓。日本美国争冠死磕。本届女足世界杯,是颠覆与反颠覆之争。夺冠大热门东道主德国队1/4决赛被日本队加时赛一球而“黑”,另一个夺冠大热门瑞典队则在半决赛被日本队3:1彻底打垮。而美国队则捍卫着女足豪强的尊严,在1/4决赛,她们与巴西女足苦战至点球大战,最终以5:3淘汰这支迅速崛起的黑马球队,而在半决赛,她们更是3:1大胜欧洲黑马法国队。美日两队此次世界杯进程惊人相似,小组赛前两轮全胜,最后一轮输球,1/4决赛同样与对手90分钟内战成平局,半决赛竟同样3:1大胜对手。此次决战,无论是日本还是美国队夺冠,均将创造女足世界杯新的历史。两巴相逢必有生死。本届美洲杯,让人大跌眼镜的事情太多。巴西、巴拉圭冤家路窄似乎更具传奇色彩。两队小组赛同分在B组,原本两个出线大热门,却双双在前两轮小组赛战平,两队直接交锋就是2:2平局,结果双双面临出局危险。最后一轮,巴西队在下半场终于发威,4:2大胜厄瓜多尔后来居上以小组第一出线,而巴拉圭最后一战还是3:3战平委内瑞拉获得小组第三,侥幸凭借净胜球优势挤掉A组第三名的哥斯达黎加,获得一个八强席位。在小组赛,巴西队是在最后时刻才逼平了巴拉圭,他们的好运气会在淘汰赛再显神威吗?巴拉圭此前3轮小组赛似乎都缺乏运气,此番又会否被幸运之神补偿一下呢?。另一场美洲杯1/4决赛,智利队在C组小组赛2胜1平以小组头名晋级八强;而委内瑞拉在B组是最不被看好的球队,但竟然在与巴西、巴拉圭同组的情况下,前两轮就奠定了小组出线权,他们小组3战1胜2平保持不败战绩,而入球数跟智利一样都是4球,只是失球数比智利多了1个。但既然他们面对强大的巴西都能保持球门不失,此番再创佳绩也不足为怪。‘,
‘彩票‘)
token_dict = load_vocabulary(bert_paths.vocab)
tokenizer = Tokenizer(token_dict)
def get_keras_bert_iterator(data_path, cat_to_id, tokenizer):
while True:
data_iter = get_text_iterator(data_path)
for text, category in data_iter:
indices, segments = tokenizer.encode(first=text, max_len=text_max_length)
yield indices, segments, cat_to_id[category]
it = get_keras_bert_iterator(r"data/keras_bert_train.txt", cat_to_id, tokenizer)
# next(it)
def batch_iter(data_path, cat_to_id, tokenizer, batch_size=64, shuffle=True):
"""生成批次数据"""
keras_bert_iter = get_keras_bert_iterator(data_path, cat_to_id, tokenizer)
while True:
data_list = []
for _ in range(batch_size):
data = next(keras_bert_iter)
data_list.append(data)
if shuffle:
random.shuffle(data_list)
indices_list = []
segments_list = []
label_index_list = []
for data in data_list:
indices, segments, label_index = data
indices_list.append(indices)
segments_list.append(segments)
label_index_list.append(label_index)
yield [np.array(indices_list), np.array(segments_list)], np.array(label_index_list)
it = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, batch_size=1)
# next(it)
it = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, batch_size=2)
next(it)
([array([[ 101, 4993, 2506, ..., 131, 123, 102],
[ 101, 2506, 3696, ..., 1139, 125, 102]]),
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])],
array([0, 0]))
def get_model(label_list):
K.clear_session()
bert_model = load_trained_model_from_checkpoint(bert_paths.config, bert_paths.checkpoint, seq_len=text_max_length) #加载预训练模型
for l in bert_model.layers:
l.trainable = True
input_indices = Input(shape=(None,))
input_segments = Input(shape=(None,))
bert_output = bert_model([input_indices, input_segments])
bert_cls = Lambda(lambda x: x[:, 0])(bert_output) # 取出[CLS]对应的向量用来做分类
output = Dense(len(label_list), activation=‘softmax‘)(bert_cls)
model = Model([input_indices, input_segments], output)
model.compile(loss=‘sparse_categorical_crossentropy‘,
optimizer=Adam(1e-5), #用足够小的学习率
metrics=[‘accuracy‘])
print(model.summary())
return model
early_stopping = EarlyStopping(monitor=‘val_acc‘, patience=3) #早停法,防止过拟合
plateau = ReduceLROnPlateau(monitor="val_acc", verbose=1, mode=‘max‘, factor=0.5, patience=2) #当评价指标不在提升时,减少学习率
checkpoint = ModelCheckpoint(‘trained_model/keras_bert_THUCNews.hdf5‘, monitor=‘val_acc‘,verbose=2, save_best_only=True, mode=‘max‘, save_weights_only=True) #保存最好的模型
def get_step(sample_count, batch_size):
step = sample_count // batch_size
if sample_count % batch_size != 0:
step += 1
return step
batch_size = 4
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, batch_size)
dev_dataset_iterator = batch_iter(r"data/keras_bert_dev.txt", cat_to_id, tokenizer, batch_size)
model = get_model(categories)
#模型训练
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau, checkpoint],
verbose=1
)
Model: "functional_5"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 512)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 512)] 0
__________________________________________________________________________________________________
functional_3 (Functional) (None, 512, 768) 101677056 input_1[0][0]
input_2[0][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 768) 0 functional_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 14) 10766 lambda[0][0]
==================================================================================================
Total params: 101,687,822
Trainable params: 101,687,822
Non-trainable params: 0
__________________________________________________________________________________________________
None
Epoch 1/10
5/167215 [..............................] - ETA: 775:02:36 - loss: 0.4064 - accuracy: 0.9000
---------------------------------------------------------------------------
second_label_list = [0, 1, 2]
def get_keras_bert_iterator(data_path, cat_to_id, tokenizer, second_label_list):
while True:
data_iter = get_text_iterator(data_path)
for text, category in data_iter:
indices, segments = tokenizer.encode(first=text, max_len=text_max_length)
yield indices, segments, cat_to_id[category], random.choice(second_label_list)
it = get_keras_bert_iterator(r"data/keras_bert_train.txt", cat_to_id, tokenizer, second_label_list)
# next(it)
def batch_iter(data_path, cat_to_id, tokenizer, second_label_list, batch_size=64, shuffle=True):
"""生成批次数据"""
keras_bert_iter = get_keras_bert_iterator(data_path, cat_to_id, tokenizer, second_label_list)
while True:
data_list = []
for _ in range(batch_size):
data = next(keras_bert_iter)
data_list.append(data)
if shuffle:
random.shuffle(data_list)
indices_list = []
segments_list = []
label_index_list = []
second_label_list = []
for data in data_list:
indices, segments, label_index, second_label = data
indices_list.append(indices)
segments_list.append(segments)
label_index_list.append(label_index)
second_label_list.append(second_label)
yield [np.array(indices_list), np.array(segments_list)], [np.array(label_index_list), np.array(second_label_list)]
it = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, second_label_list, batch_size=2)
next(it)
([array([[ 101, 4993, 2506, ..., 131, 123, 102],
[ 101, 2506, 3696, ..., 1139, 125, 102]]),
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])],
[array([0, 0]), array([0, 0])])
def get_model(label_list, second_label_list):
K.clear_session()
bert_model = load_trained_model_from_checkpoint(bert_paths.config, bert_paths.checkpoint, seq_len=text_max_length) #加载预训练模型
for l in bert_model.layers:
l.trainable = True
input_indices = Input(shape=(None,))
input_segments = Input(shape=(None,))
bert_output = bert_model([input_indices, input_segments])
bert_cls = Lambda(lambda x: x[:, 0])(bert_output) # 取出[CLS]对应的向量用来做分类
output = Dense(len(label_list), activation=‘softmax‘)(bert_cls)
output_second = Dense(len(second_label_list), activation=‘softmax‘)(bert_cls)
model = Model([input_indices, input_segments], [output, output_second])
model.compile(loss=‘sparse_categorical_crossentropy‘,
optimizer=Adam(1e-5), #用足够小的学习率
metrics=[‘accuracy‘])
print(model.summary())
return model
early_stopping = EarlyStopping(monitor=‘val_acc‘, patience=3) #早停法,防止过拟合
plateau = ReduceLROnPlateau(monitor="val_acc", verbose=1, mode=‘max‘, factor=0.5, patience=2) #当评价指标不在提升时,减少学习率
checkpoint = ModelCheckpoint(‘trained_model/muilt_keras_bert_THUCNews.hdf5‘, monitor=‘val_acc‘,verbose=2, save_best_only=True, mode=‘max‘, save_weights_only=True) #保存最好的模型
batch_size = 4
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = batch_iter(r"data/keras_bert_train.txt", cat_to_id, tokenizer, second_label_list, batch_size)
dev_dataset_iterator = batch_iter(r"data/keras_bert_dev.txt", cat_to_id, tokenizer, second_label_list, batch_size)
model = get_model(categories, second_label_list)
#模型训练
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau, checkpoint],
verbose=1
)
Model: "functional_5"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 512)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 512)] 0
__________________________________________________________________________________________________
functional_3 (Functional) (None, 512, 768) 101677056 input_1[0][0]
input_2[0][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 768) 0 functional_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 14) 10766 lambda[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 3) 2307 lambda[0][0]
==================================================================================================
Total params: 101,690,129
Trainable params: 101,690,129
Non-trainable params: 0
__________________________________________________________________________________________________
None
Epoch 1/10
7/167215 [..............................] - ETA: 1829:52:33 - loss: 3.1260 - dense_loss: 1.4949 - dense_1_loss: 1.6311 - dense_accuracy: 0.6429 - dense_1_accuracy: 0.3571
标签:+= shuf python compile build 文件 image sys sse
原文地址:https://www.cnblogs.com/zhangsheng377/p/14491992.html