标签:second dir fsimage inf 目录 界面 hadoop 集群 oop tps
hadoop集群安装
| 服务器IP | node01 | node02 | node03 |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
目前hadoop已经更新到3.x版本,这次我们使用的是3.1.4版本
使用国内清华大学的镜像库地址
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.4/
将下载的压缩包保存在/bigdata/install
cd /bigdata/install
tar -zxf hadoop-3.1.4.tar.gz -C /bigdata/install/
在第一台机器执行以下命令
cd /bigdata/install/hadoop-3.1.4/
bin/hadoop checknative
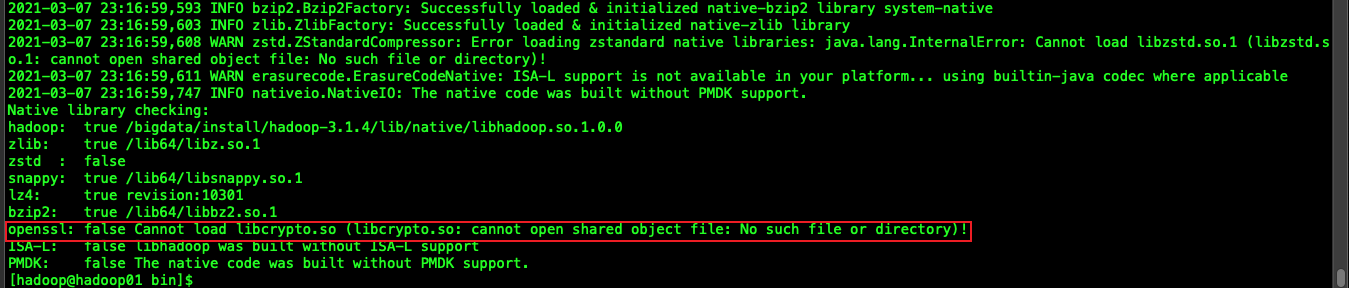
如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
sudo yum -y install openssl-devel
一共要修改5个文件hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
第一台机器执行以下命令
cd /bigdata/install/hadoop-3.1.4/etc/hadoop
vi hadoop-env.sh
查找到JAVA_HOME的配置信息,修改为下边信息
export JAVA_HOME=/bigdata/install/jdk1.8.0_141
第一台机器执行以下命令
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/install/hadoop-3.1.4/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整;默认值4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟;默认值0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
第一台机器执行以下命令
vi hdfs-site.xml
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- namenode保存fsimage的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/datanodeDatas</value>
</property>
<!-- namenode保存editslog的目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- secondarynamenode保存待合并的fsimage -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name</value>
</property>
<!-- secondarynamenode保存待合并的editslog -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
第一台机器执行以下命令
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
第一台机器执行以下命令
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 如果vmem、pmem资源不够,会报错,此处将资源监察置为false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
第一台机器执行以下命令
vi workers
把里面内容全部删除后替换为
hadoop01
hadoop02
hadoop03
第一台机器执行以下命令
hadoop01机器上面创建以下目录
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/tempDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
hadoop01执行以下命令进行拷贝
cd /bigdata/install
scp -r hadoop-3.1.4/ hadoop02:$PWD
scp -r hadoop-3.1.4/ hadoop03:$PWD
三台机器都要进行配置hadoop的环境变量,三台机器执行以下命令
sudo vi /etc/profile
export HADOOP_HOME=/bigdata/install/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成之后生效
source /etc/profile
hdfs namenode -format
hadoop namenode –format
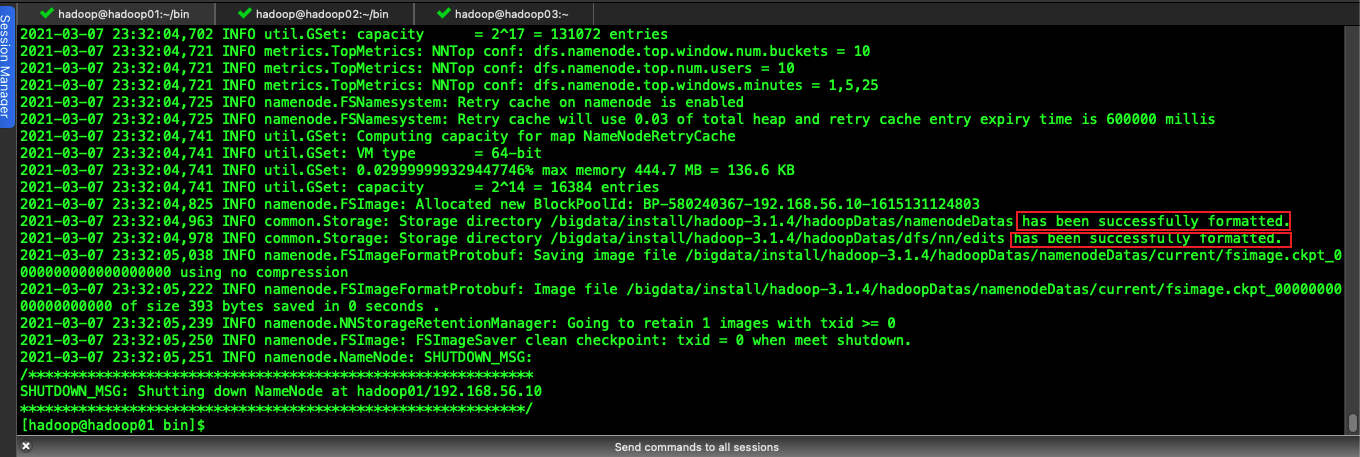
start-dfs.sh
start-yarn.sh
# 已过时mr-jobhistory-daemon.sh start historyserver
mapred --daemon start historyserver
stop-dfs.sh
stop-yarn.sh
# 已过时 mr-jobhistory-daemon.sh stop historyserver
mapred --daemon stop historyserver
# 在主节点上使用以下命令启动 HDFS NameNode:
# 已过时 hadoop-daemon.sh start namenode
hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode:
# 已过时 hadoop-daemon.sh start secondarynamenode
hdfs --daemon start secondarynamenode
# 在每个从节点上使用以下命令启动 HDFS DataNode:
# 已过时 hadoop-daemon.sh start datanode
hdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager:
# 已过时 yarn-daemon.sh start resourcemanager
yarn --daemon start resourcemanager
# 在每个从节点上使用以下命令启动 YARN nodemanager:
# 已过时 yarn-daemon.sh start nodemanager
yarn --daemon start nodemanager
以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。
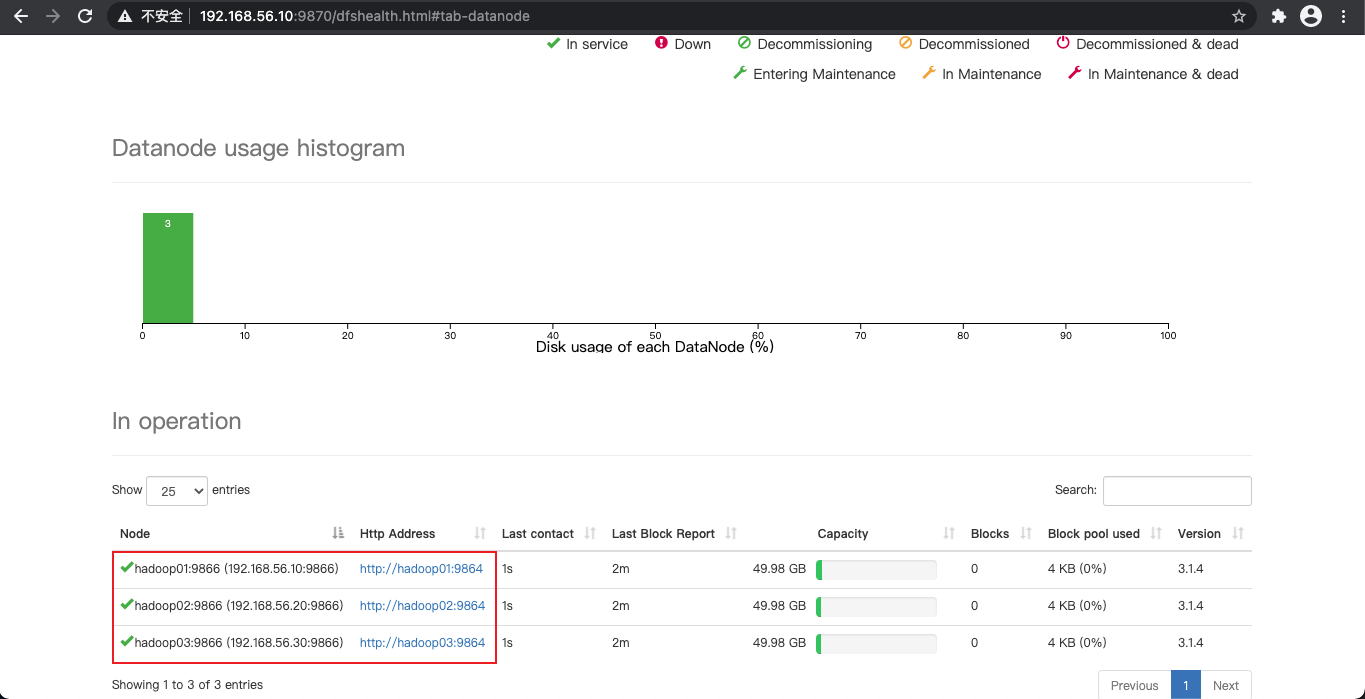
hdfs集群访问地址
http://192.168.56.10:9870
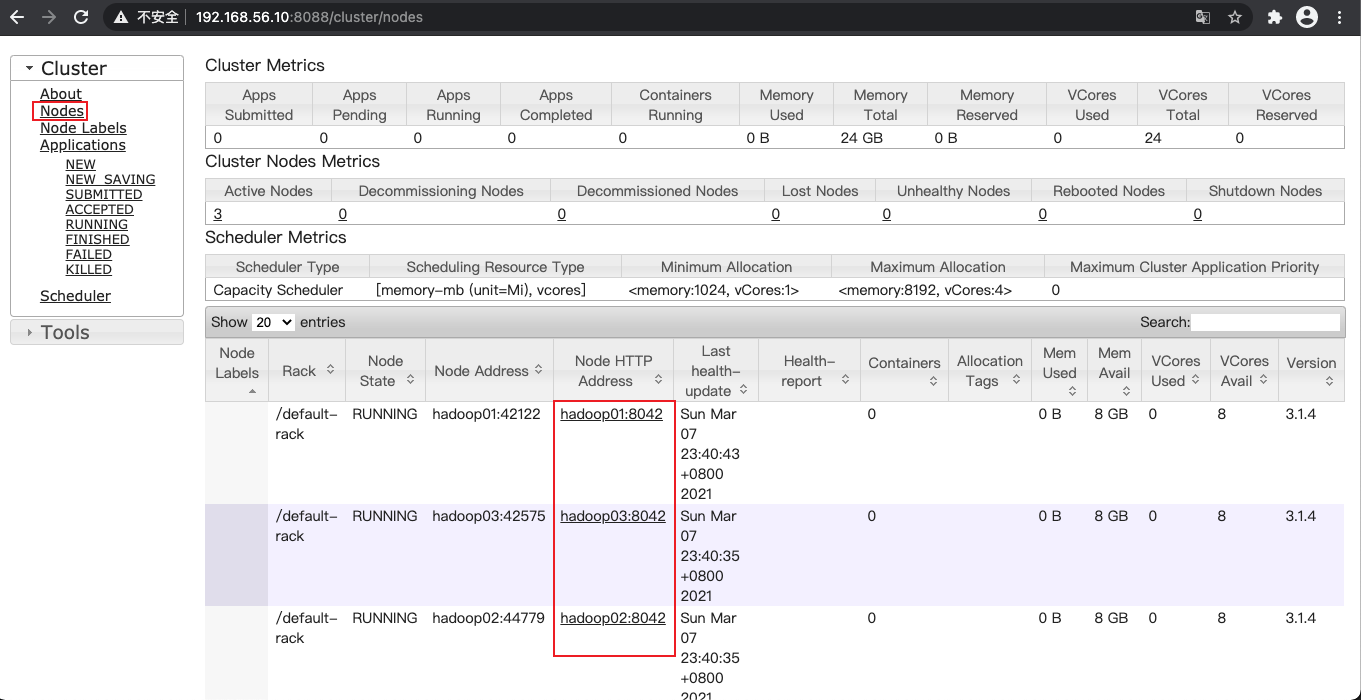
yarn集群访问地址
http://192.168.56.10:8088
jobhistory访问地址:
http://192.168.56.10:19888
标签:second dir fsimage inf 目录 界面 hadoop 集群 oop tps
原文地址:https://www.cnblogs.com/tenic/p/14497459.html