标签:语法 缺点 自己的 io操作 pipe 崩溃 部分 针对 存储
Redis 是速度非常快的 非关系型(NoSQL) 内存 键值 数据库。
Redis 支持很多特性:例如数据持久化,使用复制来扩展读性能,使用分片来扩展写性能,Redis Cluster 实现了分布式的支持。
内存管理机制:在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘。
Redis 可以存储键和五种不同类型的值之间的映射。
键的类型只能为字符串。
值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数、浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
ZSET的底层采用跳跃表实现。跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。
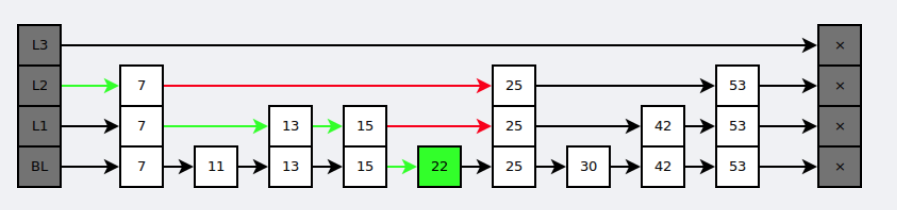
与红黑树等平衡树相比,跳跃表具有以下优点:
Redis 可以为每个键设置过期时间,当键过期时,会自动删除该键。
对于散列表这种容器,只能为整个键设置过期时间(整个散列表),而不能为键里面的单个元素设置过期时间。
可以设置内存最大使用量(默认值为0,表示无限制),当内存使用量超出时,会执行数据淘汰策略。
设置内存最大使用量主要目的有以下两种情况:
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中 挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中 挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中 任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中 挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中 任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据 |
Redis 4.0 引入了 volatile-lfu 和 allkeys-lfu 淘汰策略,LFU 策略通过统计访问频率,将访问频率最少的键值对淘汰。
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
作为内存型数据库,Redis虽然速度非常快,但面临一个问题:电脑如果需要重启或者意外宕机,保存在内存中的数据就会丢失。
所以,为了在电脑重启后,能够恢复原来的数据,Redis就需要提供持久化的机制,将存储在内存中的数据,在磁盘中进行备份。这样在重启后,Redis就可以根据磁盘中持久化的备份,将数据重新读取到内存中,避免数据丢失。
RDB是Redis DataBase的缩写。
Redis将当前内存中存储的数据写入到磁盘上的一个文件中,将其作为当前的一个快照。当Redis重启时,将这个快照文件中存储的内容加载进内存,即可恢复Redis之前的状态。
功能的两个核心函数是rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)。
RDB文件默认都开启了压缩(LZF算法),虽然耗时,但是体积大大减小。
注意:Redis默认使用RDB的持久化方式。
优点
缺点
AOF是Append-Only File的缩写,只追加文件。
将Redis执行的所有写指令,追加到AOF文件的末尾。当Redis重启后,读取AOF文件,重新执行其中的写操作,以此达到恢复数据的目的。
<1> 同步选项
使用AOF持久化需要设置同步选项。这是因为AOF 机制并不会立刻将写操作同步到磁盘上,而是先存储到缓冲区,然后根据同步选项决定何时同步到磁盘。
有以下三种同步选项:
<2> AOF重写(Rewrite)
不断将写指令追加到AOF的末尾,会导致AOF文件越来越大。Redis实现了AOF重写的优化机制,来解决这个问题。
当Redis检查到AOF已经很大时,就会触发重写机制,优化其中的冗余内容,将它优化为能够得到相同结果的最小的指令集合。如,先创建再删除的两条指令,不会保留;多次自增会直接保留最后的值,等等。
<3> 与RDB的比较
优点:
缺点
注意:如果RDB和AOF的持久化方式都配置了,Redis会优先加载AOF。
Redis不支持主主复制。
主从复制是Redis用来对存储相同数据的多台服务器(集群)进行同步的机制。主从复制依赖于Redis的快照持久化。
在主从复制机制中,Redis将服务器分为主服务器和从服务器。一个从服务器只能有一个主服务器。
通过使用 slaveof 主服务器ip 主服务器port 命令,或者在配置文件中添加该配置项语句,来让一个服务器成为另一个服务器的从服务器。
完整的主从复制分为同步(发送快照) 、 命令传播(发送写操作) 两个部分。
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。
可以通过主从链解决这个问题:创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
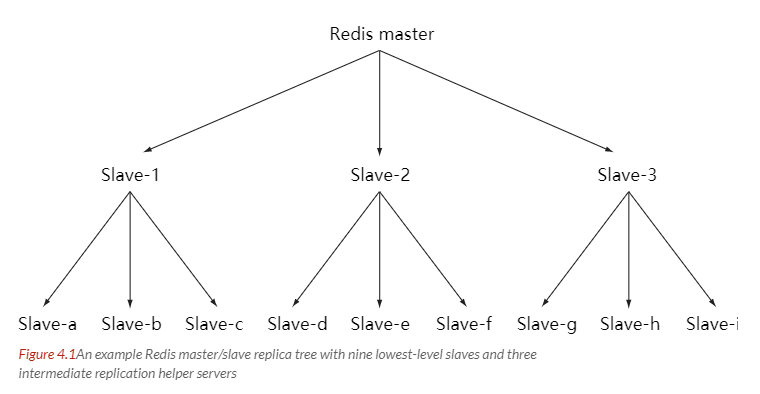
上面介绍的同步机制是一种完整重同步,开销大且耗时。
在命令传播阶段,若主从服务器网络断开,重连后主从服务器上的数据就不一致了。在这种情况下,Redis2.8之后提供了一种部分重同步的优化机制,避免了完整重同步。
主服务器在命令传播时,维护一个复制积压缓冲区,这是一个固定长度、先进先出的队列,默认为1 MB。在从服务器重连后,发送自己的复制偏移量,若主服务器判断该偏移量之后的所有字节都在缓冲区中,则可以进行部分重同步,即把该偏移量之后的所有字节发送给从服务器。否则,就需要进行一次完全重同步。
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
注意:此时,关闭了持久化的主服务器开启自动重启进程选项是危险的,因为快速重启可能还没有触发哨兵机制,重启后仍为主服务器,但数据已丢失,并把空的数据集同步给了所有从服务器。
Redis 事务的本质是一组命令的集合。服务器在执行事务期间,会按照顺序串行化执行队列中的命令,且不会改去执行其它客户端的命令请求。
<1> 事务相关命令
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
<2> 注意:与关系型数据库中的事务不同,Redis 的事务不保证原子性,也不支持回滚。
多数事务失败是由语法错误或者数据结构类型错误导致的。语法错误在命令入队前就进行检测,因此一旦有语法错误,则事务的所有命令都不执行。而类型错误是在执行时才进行检测,当遇到此类错误时,前面已经执行过的命令结果会保留,不会回退。Redis为提升性能而采用这种简单的事务,这是不同于关系型数据库的。
<3> 监视key
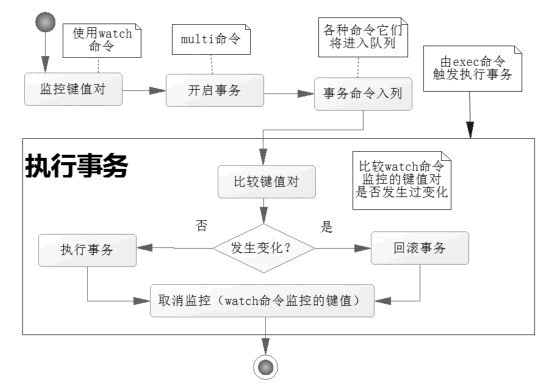
Redis的watch命令保证了,在监视的key被修改后,后面的第一个事务不会执行。
具体来说,需要在MULTI之前使用WATCH来监控某些键值对,然后使用MULTI命令来开启事务,执行对数据结构操作的各种命令,此时这些命令入队列。
当使用EXEC执行事务时,首先会比对WATCH所监控的键值对,如果没发生改变,它会执行事务队列中的命令,提交事务;如果发生变化,将不会执行事务中的任何命令。
无论结果如何,Redis都会取消执行事务前的WATCH命令。
实际中Redis的读写速度十分快,而系统的瓶颈往往是在网络通信中的延时。
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为Pipelined(流水线),它可以减少客户端与服务器之间的网络通信次数从而提升性能。
虽然Redis的事务也提供了队列,可以批量执行任务,但使用事务命令有系统开销,因为它会检测对应的锁和序列化命令。
Redis的流水线是一种通信协议,没有办法通过客户端执行,但是可以通过Java API(如Jedis)或使用Spring操作它。
// 开启流水线
Pipeline pipeline = jedis.pipelined();
// 只同步不返回结果
pipeline.sync();
// 同步且返回结果(List的形式)
List<Object> result = pipeline.syncAndReturnAll();
SessionCallback callback = (SessionCallback)(RedisOperations ops)->{
for(int i = 0; i < 100000; i++) {
int j = i + 1;
ops.boundValueOps("key" + j).set("value" + j);
ops.boundValueOps("key" + j).get();
}
return null;
};
redisTemplate.executePipelined(callback);
List result = rt.executePipelined(callback);
标签:语法 缺点 自己的 io操作 pipe 崩溃 部分 针对 存储
原文地址:https://www.cnblogs.com/BWSHOOTER/p/14500453.html