标签:数据 page 指正 存在 进程 针对 转译 信息 读写
本文目的不在于详解分页机制的内容,而在于从头捋清到底为什么非要采用分页机制做内存管理,因此有些繁琐,对分页机制的细节,将在其他文章讨论,欢迎交流和指正。
一、背景和缘起
1、内存管理要完成哪些任务?
内存是整个计算机系统的”交通枢纽“,是指令和数据的集散地,具体地说,除了操作系统外,指令是进程的指令,数据是进程的数据,也就是说,内存管理所要解决的最基本问题就是“进程往哪放”以及“多少空间用来放进程”,这是“内存分配(Memory Allocation)”任务。
其次,由于多任务的刚需,不同进程需要相对独立性,属于某个进程的空间不能被其他进程非法访问,以及有些只读内容不能被非法修改,这是“内存保护(Memory Protection)”任务。
以上,是内存管理所必须完成的两个基本任务。
2、内存管理还要达到哪些要求?
内存(Memory)有如下性质:
所有对内存管理策略的要求,正是针对以上这几点性质所提出:
以上两点要求,是内存管理所要尽量满足的性能要求。
“两个必须完成的基本任务+三项尽量满足的性能要求”是设计内存管理方法的关键。
以下,谈解决上述问题的两种基本策略——连续分配(Contigious Allocation)和不连续分配(Noncontigious Allocation),在解决两个基本问题的基础上,探讨对三项性能要求的满足情况。
3、操作系统放在哪?
所有指令和数据都必须加载到内存中对CPU才有意义,操作系统也不例外,因此物理内存首先要分出大块来装载操作系统,一般做法是直接把一段低地址空间割给操作系统,剩下高地址空间用来放进程,在这一点,连续分配和不连续分配都是一样的。
至于这段低地址空间中的操作系统内部是怎样分配空间的,我们暂时不管,把它当成黑箱就可,我们只关心如何管理提供给用户进程的这部分内存空间,后面所谈到的连续分配和不连续分配说的也都是如何把用户进程放到内存中的。
二、连续分配以及连续分配的问题
连续分配中的“连续”,指的是进程被装载时,被放到一片连续的内存空间中。思路直观而简单:找一块够大的空地,直接把进程囫囵扔进去就是了。
1、内存分配
连续分配的过程是这样的:
一开始,没有进程,整片内存为空闲,相当于一个巨大的孔(hole)。

有进程来时,这个大孔分出一块装进程,剩余部分作为小孔,再有进程来,小孔再分,剩下更小的孔,依此类推,如下图所示( $P_i$指进程):

到目前为止,一切完美,内存得到充分利用。
然而,当已经加载出来的进程结束时,它会释放它的空间,由此产生一个新孔,这个孔极有可能和其他孔是不相连的,一来二去,内存的格局会变成下面这种情况:

这相当于,原本一块完整的大片空闲内存,被切碎成了许多小孔,最坏的情况是,每两个进程之间都有一块很小的孔。这时问题就来了:如果接下来的进程比较大,没有一个小孔装得下怎么办?
例如,接下来要装载的进程需要100KB空间,内存中空闲区域总共有8000KB,但全是100个大小为80KB的小孔,总量远远管够,但偏偏就是容不下它。
这就等于,这8000KB的内存全都没用了!
这些空闲但因无法使用而废弃的小孔,叫做外部碎片(External Fragmentation),据统计,即便对这一策略做了优化,因外部碎片导致的内存浪费可以达到整个内存的30%以上,这是何等巨大的浪费!
2、内存保护
连续分配下的内存保护可以通过基址寄存器来实现,每个进程产生的指令地址都由两部分组成:基址+偏移,只要给每个进程的基址设为不同,不同进程之间就会运行在各自的空间,互不干扰。
不过这种内存保护有点简陋,因为它只实现了进程间保护,并没有实现进程内只读内容的保护。
综上,连续分配可以完成两个基本任务,但是在性能上,存在不可容忍的内存浪费。
三、不连续分配——分页
1、由来
想想,连续分配中巨大内存浪费的根源在何处?
根源在两点:
那么要解决这个问题,也理所当然从这两点入手。
从第一点入手,就是不让内存碎片化,办法是压缩(Compaction)。每当有旧进程终止,释放空间时,都把内存中的进程挪一挪,让它们全都挨一起,时刻保证所有空闲空间是一整块。这种做法虽能直接消除外部碎片,但时间代价太高了,挪动进程位置需要大量内存读写操作,而且被挪动的进程指令还需要进行重定位(因为变量、函数的位置都变了),这些代价不可接受。
于是,我们只能从第二点入手,也就是把进程也打成碎片,把进程碎片装进内存碎片里,使内存碎片得到利用而不是被浪费。如此进程所驻留的空间就不再连续,因此这一策略被称为“不连续分配”。
2、分页(Paging)
分页是不连续分配的具体实现方式。
分页的做法是,既然内存碎片化无法解决,那就干脆一开始就把内存分割成固定大小的碎片,称为框(frame),每当有进程要装载时,把进程也切割成和框一样大小的碎片,称为页(page),为每一页分配一个框,放到内存中去。就像你把一整只猪切成肉段,放到冰箱隔间里一样。
3、页表(Page Table)
分页机制把进程打散了,不同页散布在内存框中,问题来了,你怎么知道某一页内容存在哪个框里?这就需要维护一种数据结构,来保存页—框的映射信息,它就是页表:
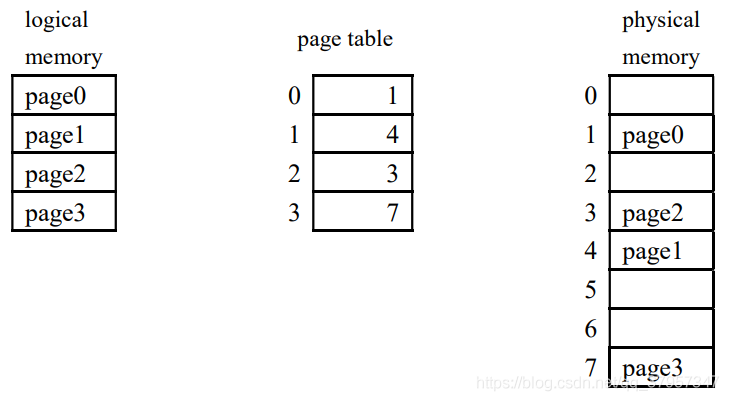
每当进程的某一条指令要访问进程内某地址时,其产生的地址都会被分割成“页号+页内偏移的形式”,如下图所示:
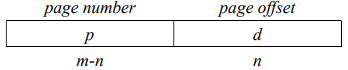
然后CPU再根据页号查找页表,找到物理内存中该页对应的框号,用来替换页号,重新拼接成真正的物理地址,再让CPU去访问该地址。
分页解决了外部碎片问题,因为内存和进程都被打成碎片,只要进程有页需要装载,那就可以为之分配任意一个空闲的框,不会有框白白浪费。但是,由于框成了内存分配的最小单位,就容易出现进程的最后一页内容不满一页却占用了一整个框的情况。
例如一个进程有17KB大,一个框和页的大小是8KB,那么这个进程将分为3页占3个框,而最后一页有效内容只有1KB,其余的7KB就浪费了,这种浪费称为内部碎片(Internal Fragmentation)。
分页彻底解决了外部碎片问题,但引入了内部碎片问题,但内部碎片引起的内存浪费远远小于外部碎片。
3、多级页表和哈希页表
每个进程都有一个页表,页表也需要占用内存空间。
32位的计算机,地址线为32位,最大可访问内存空间为64KB,如果一个框尺寸为4KB,一个页表项大小为4B,则每个进程可能会需要4MB的空间为其存放页表,代价堪称高昂。
解决办法是把页表也打碎、分页,先用“页表的页表”去查找页表,再用找到的页表去查找物理地址,如果有必要,还可以设置更多级的页表。
对于64位的系统,如果采用多级页表,层数将十分可观,为了访问一个字节的地址,需要查找这么多次页表,岂非十分低效?因此对于64位系统还有一种替代方案是哈希页表,即哈希法来组织页表,从而提高查表速度。哈希页表和多级页表此处不是重点姑且略过。
前面提到过,内存相对与CPU来说是一种低速设备。而分页机制要求访问每个字节,都需要至少一次查表操作,多级页表还需要更多次,页表也位于内存之中,每次查表都要多访问一次内存,也就是说,访问每一个字节所要花的时间提高了一倍甚至好几倍!
分页有诸多好处(这将在后面的文章中说明),这一机制不应舍弃,为了弥补这一短板,只好从硬件上做改进——在CPU内集成一块高速缓存,即转译后备缓冲区(Translation Lookaside Buffer,TLB),把最近用到的页表项缓存在TLB,查表时先查TLB,若没找到再去内存中查找,从而减少对内存的访问,缓解这一问题。
4、内存保护
进程每次访问地址之前,都要查页表,这就给内存保护提供了方便:我们可以用页表项中剩余的位来标记与内存保护相关的信息。譬如,用一个位来表示该页是只读的还是可读写的,还可以用一个位来表示该页是属于当前进程的还是其他进程的。每次访问物理地址之前,都根据这些位来检查即将进行的访问是否合法,一旦发现不合法(例如对只读地址进行写操作),就阻止此次访问,并抛出异常。
综上,基于分页机制的不连续分配完成了内存分配和内存保护两个基本任务,并在性能上解决了连续分配策略的内存过度浪费问题,通过硬件TLB的辅助缓解了其自身的多次访问内存的问题。
此外,分页机制还有更多优势,比如支持内存共享、支持虚拟内存等,这些内容在其他文章中详细阐述,此处暂略。
以上,是为什么非要采用分页这么繁琐的机制来进行内存管理的来龙去脉和权衡考量。
目前,主流操作系统的内存管理都基于分页机制的不连续分配。
以上内容总结自《Operating System Concepts》。
码字不易,倘若觉得有益,请点个赞再走呗~
标签:数据 page 指正 存在 进程 针对 转译 信息 读写
原文地址:https://www.cnblogs.com/xilaii/p/14510540.html