标签:span 框架 hbase 存储管理 系统 map oop nbsp google
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
答:
Hadoop对应于Google三驾马车:HDFS对应于GFS,即分布式文件系统,MapReduce即并行计算框架,HBase对应于BigTable,即分布式NoSQL列数据库,外加Zookeeper对应于Chubby,即分布式锁设施。
HDFS
HDFS(Hadoop分布式文件系统)源自于Google的GFS论文,发表于2003年10月,HDFS是GFS的实现版。HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一次性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适用带有数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在不同的物理机器上。
HDFS默认的最基本的存储单位是64MB的数据块,和普通文件系统一样,HDFS中的文件被分成64MB一块的数据块存储。它的开发是基于流数据模式访问和处理超大文件的需求。
MapReduce
Mapduce(分布式计算框架)源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google Reduce 克隆版。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
HBase
Hbase(分布式列存数据库)源自Google的BigTable论文,发表于2006年11月,HBase是Google Table的实现。HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型,即增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模
YARN
YARN(分布式资源管理器)是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。YARN是下一代Hadoop计算平台,是一个通用的运行时框架,用户可以编写自己的极端框架,在该运行环境中运行。
Spark
Spark(内存DAG计算模型)是一个Apche项目,被标榜为“快如闪电的集群计算”,它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用计算框架,Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark平台可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成一套完整生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统同时支持批处理、交互式查询和流数据处理。
3. 用图文描述你所理解的Spark运行架构,运行流程。
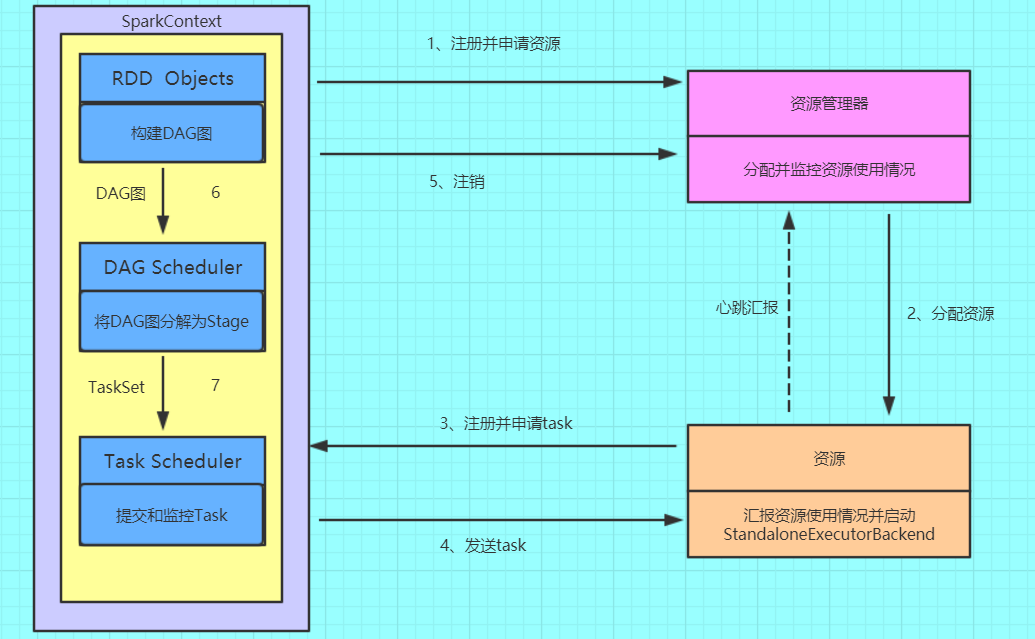
4. 软件平台准备:Linux-Hadoop。
http://dblab.xmu.edu.cn/blog/285/
http://dblab.xmu.edu.cn/blog/337-2/
http://dblab.xmu.edu.cn/blog/1624-2/
http://dblab.xmu.edu.cn/blog/1608-2/
http://dblab.xmu.edu.cn/blog/1606-2/
http://dblab.xmu.edu.cn/blog/1607-2/
http://dblab.xmu.edu.cn/blog/install-hadoop/
标签:span 框架 hbase 存储管理 系统 map oop nbsp google
原文地址:https://www.cnblogs.com/DDCWJ/p/14524337.html