标签:spark 支持 idt 组件 性能 hbase 产品 同事 art
数据应用,是真正体现数仓价值的部分,包括且又不局限于 数据可视化、BI、OLAP、即席查询,实时大屏,用户画像,推荐系统,数据分析,数据挖掘,人脸识别,风控反欺诈,ABtest等等
OLAP(On-Line Analytical Processing):在线分析处理,主要用于支持企业决策管理分析。
OLAP分类
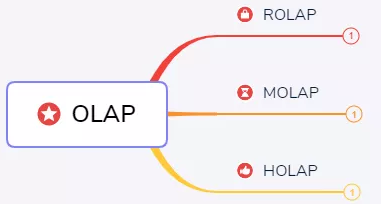
OLAP按存储器的数据存储格式分为:
1、ROLAP(Relational OLAP)
2、MOLAP(Multi-dimensional OLAP)
3、HOLAP(Hybrid OLAP)
可按企业业务场景和数据粒度进行取舍,没有最好,只有最适合。
OLAP数据库技术
在大数据数仓架构中,最早的架构离线以Hive为主,实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,后起之秀Pulsar想要做出超越难度很大,Hbase、Redis和MySQL都在特定场景下有一席之地。唯独在OLAP领域,百家争鸣,各有所长。
OLAP引擎/工具/数据库,技术选型可有很多选择,传统公司大多以Congos、Oracle、MicroStrategy等OLAP产品,互联网公司则普遍强势拥抱开源,如:
在数据架构时,可以说目前没有一个引擎能在数据量,灵活程度和性能上(吞吐和并发)做到完美,用户需要根据自己的业务场景进行选型。
开源技术选型,MOLAP可选Kylin、Druid,ROLAP可选Presto、impala等
1、Presto
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,基于内存的低延迟高并发并行计算(MPP),适用于交互式分析查询。Preso特点:
2、Druid
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析。
数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
Apache Druid 特点:
不适用的场景:
3、Clickhouse
Clickhouse是一个用于在线分析处理(OLAP)的列式数据库管理系统(DBMS)。
是由俄罗斯的Yandex公司为了Yandex Metrica网络分析服务而开发。它支持分析实时更新的数据,Clickhouse以高性能著称。

不适用的场景:

我以前是非常摒弃ROLAP的,因为实在是太慢了。ROLAP都是现算的,以前的套路基本都是生成一个巨复杂的sql扔到数据库里跑,那样能不慢么?但是这个ClickHouse却不一样,它最显著的特性就是快!这不科学啊!
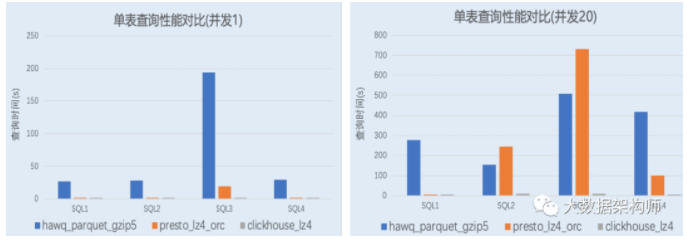
虽然各种测评都会选择偏向自己的指标,但是这也太悬殊了吧?ClickHouse的创始人yandex公司的同事出来解释过,有点让我失望,并不是一个非常牛的算法或者方案,而是从硬件开始向上一点一点的优化。是不是特别惊讶?
所以ClickHouse另外一个特性就是独立,不需要任何组件的依赖,貌似现在都有往这方面发展的趋势,比如Doris也是不需要依赖的。我们知道Kylin是需要依赖Hbase的。这就会引起各种各样的组件版本问题。想想就头大!
ClickHouse在运行的时候,会用掉服务器的所有资源,不仅仅是内存哦!甚至你查一个简单但是数据,都会吃掉50%以上的CPU!!!
另外,CK还有以下特性:
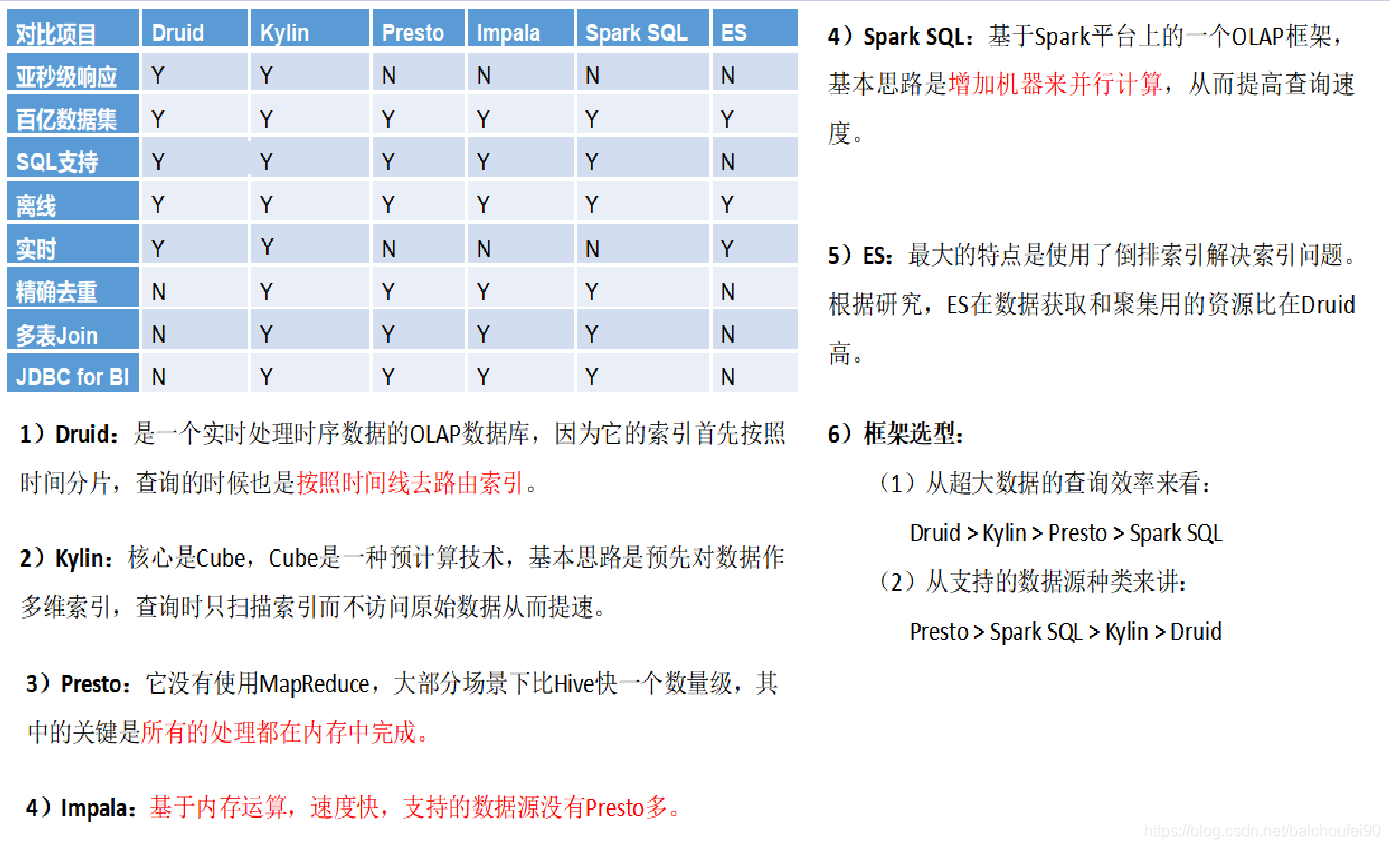
对比:

对比图:
Flag:
参考
标签:spark 支持 idt 组件 性能 hbase 产品 同事 art
原文地址:https://www.cnblogs.com/tgzhu/p/14527652.html