标签:标签 细节 zoom 处理 卷积层 方式 strong 形式 cal
其中绿线是我绘制的图像划分网格。
这里的loss是我训练的 0.77 ,由于损失函数是我自己写的,所以可能跟大家的不太一样,这个不重要,重要的是学习思路。
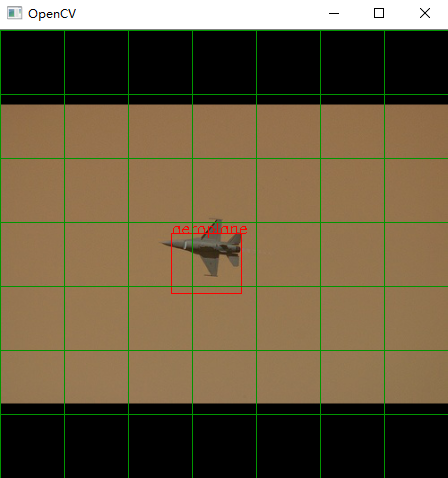

yolov1是一个目标检测的算法,他是一阶段的检测算法。
一阶段(
one-stage):检测物体的同时进行分类。(代表论文:yolov1 - yolov5)二阶段(
two-stage):先检测出物体,再进行分类。(代表论文:rcnn,fast-rcnn)
重点要理解yolov1的数据特征标注方式。
只有理解了数据特征的标注方式才可以理解他为什么可以起作用。
1、理解
VOC数据集的数据形式。2、从
VOC数据集中提取出标注好的数据特征。3、
yolov1的数据组织。4、
yolov1的算法模型。5、
yolov1的准确率评估方式(IOU)。6、
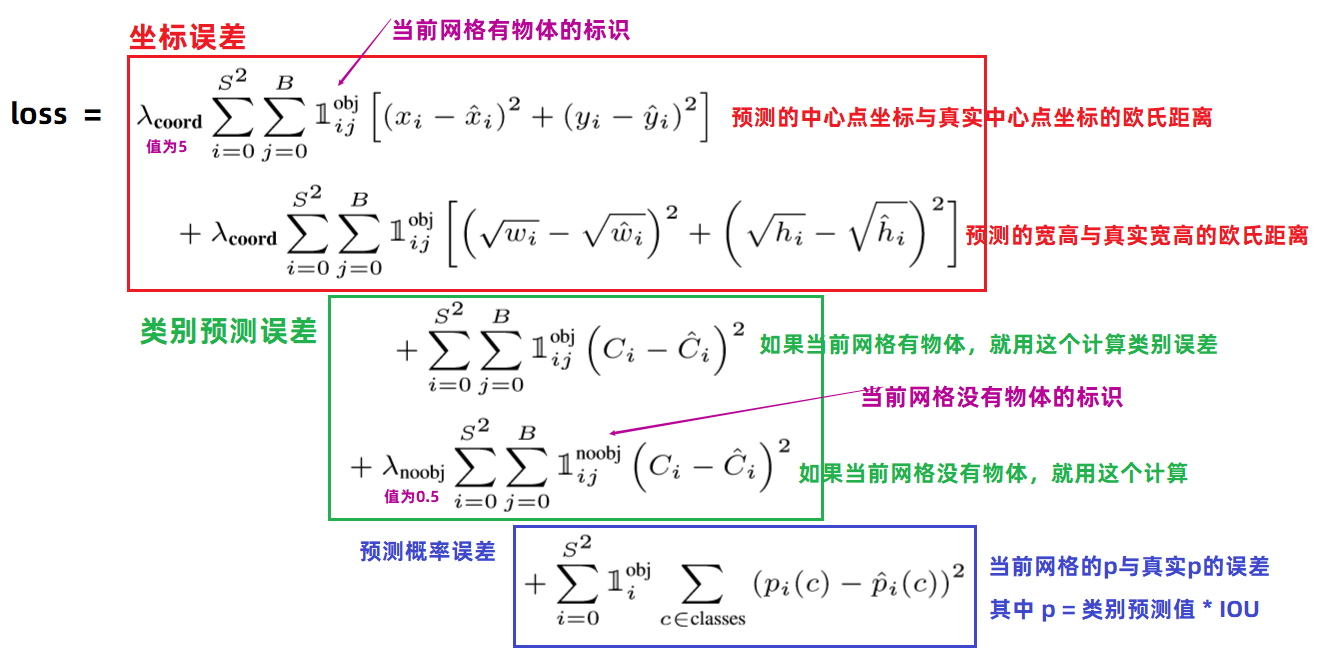
yolov1的损失函数。
首先需要知道我们使用的数据集的形式,因为每一个数据集的特征标注以及组织方式都不同。
我们可以去官网下载voc的数据集,这里使用的是voc2012数据集。
VOC数据集镜像网站. 下载voc2012的Train/Validation Data (1.9 GB)。
数据集下载之后解压出来是这样子:
每个文件夹存放的啥都标注好了,我们这里用不到那么多。
我们只用jpg原图,以及每个原图中目标的位置即可。(下边图片中画红框的两个文件夹)

但是我们发现,Annotations文件夹中的目标位置信息是存放在xml中,所以我们往下分析一个xml文件看看。
<filename>: 表示这个文件是对应于哪一个jpg图片的。
<size>:表示对应的jpg图片大小。
<object>:就是这个图片中的目标在图片中的信息。包括:目标名字,是否难识别,以及目标在整个图片中的坐标位置。(有几个 object 就是有几个目标)
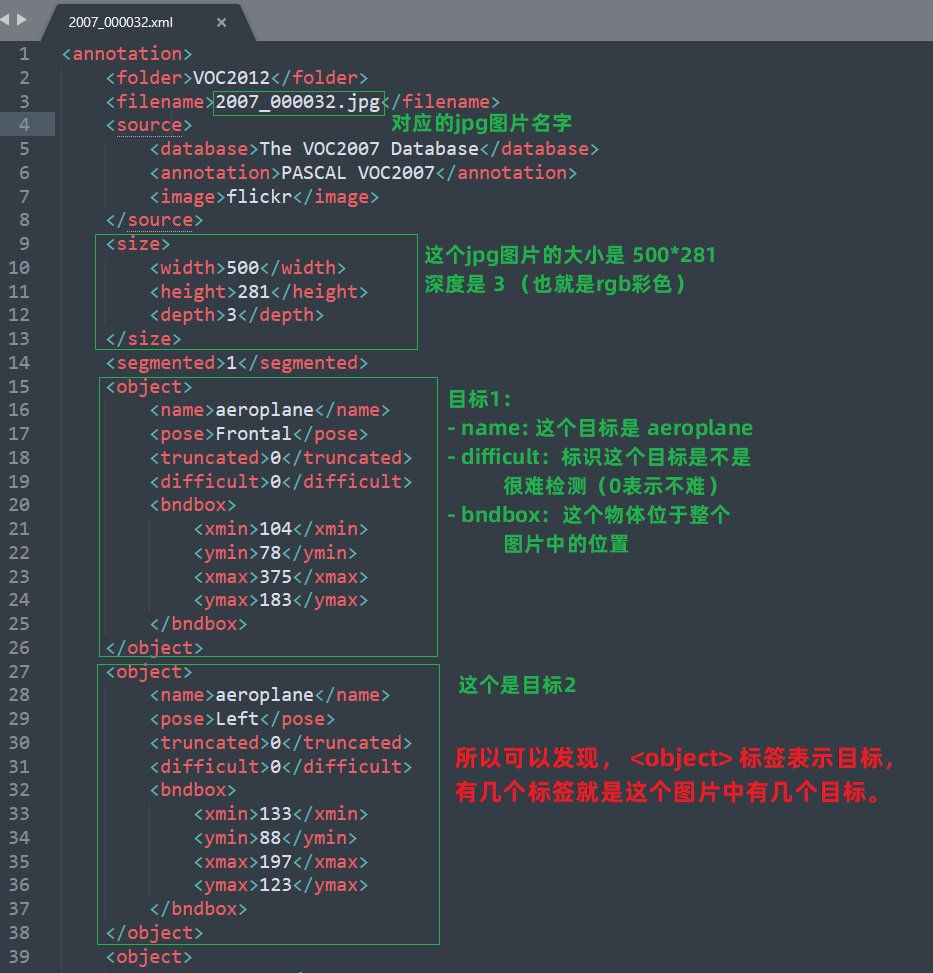
上边我们分析出每个图片中有什么目标都是存储在
xml文件中的,所以我们需要将xml文件的目标与类别数据提取出来,以便我们使用。
思路:
1、使用库 xml.etree.ElementTree 读取xml格式的文件,从中提取出每一个xml文件中的所有<ojgect>标签数据(个数就是目标的数量)。
2、将<object>标签提取出 类别、xmin、ymin、xmax、ymax ,并且将其归一化为 类别、x、y、w、h。
归一化就是根据从目标中提取出的
xmin、ymin、xmax、ymax得到目标的宽高,分别除以整个图片的宽高。
x:目标的中心位置x坐标。y:目标的中心位置y坐标。w:目标的宽度,h:目标的高度。
每一个
labels文件对应于一个图片,labels文件中的每一行就是这个图片中的一个目标的类别、x、y、w、h数据(一个图片有几个目标,对应的labels文件就有几行)。
例子:
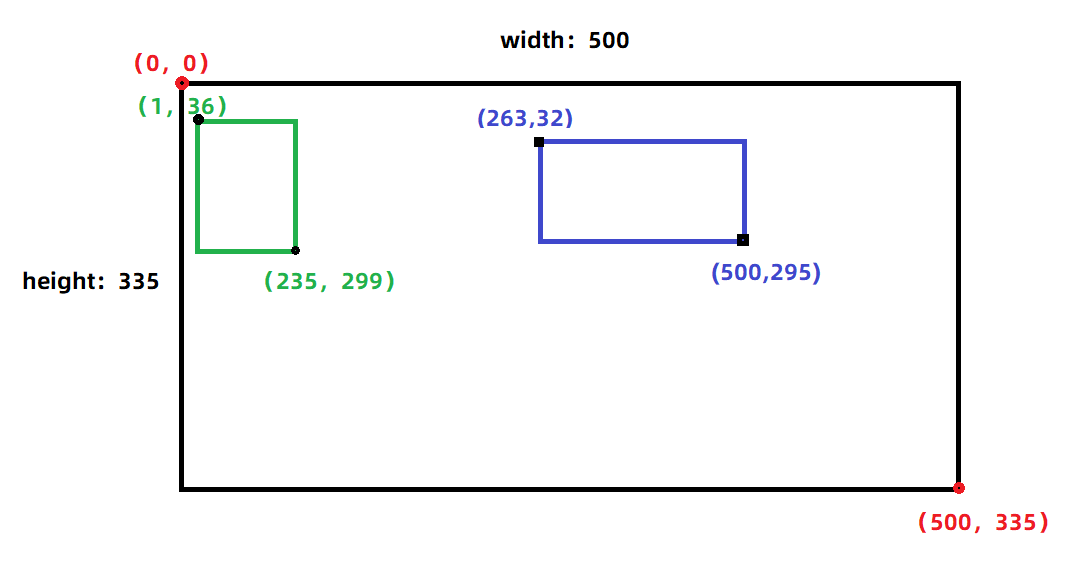
针对如下xml文件,可以得知:
- 对应的
jpg图片是2007_000042.jpg,并且图片的大小是500*335的三色图(这里的图片大小就是用来归一化的)。- 含有两个
<object>标签,所以这个图片中有两个目标,并且目标的类别、位置坐标可以根据name、xmin、ymin、xmax、ymax得到。
<annotation>
<folder>VOC2012</folder>
<filename>2007_000042.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size>
<width>500</width>
<height>335</height>
<depth>3</depth>
</size>
<segmented>1</segmented>
<object>
<name>train</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>263</xmin>
<ymin>32</ymin>
<xmax>500</xmax>
<ymax>295</ymax>
</bndbox>
</object>
<object>
<name>train</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1</xmin>
<ymin>36</ymin>
<xmax>235</xmax>
<ymax>299</ymax>
</bndbox>
</object>
</annotation>
大致如下:绿色框 与 蓝色框 分别是两个目标。
使用xml文件中已有数据,得到 labels文件如下:
其中每一行是一个物体,每行的数据表示的意义是:
类别,x,y,w,h. (数据都是归一化过了)

所以,这个就是最初的labels文件的形式。
下一步就是将这个初始labels文件数据形式,组织成可以 直接与对应图片运行 的数据形式。
其实yolo的思想可以用一句话来代替:将一个张图片划分网格(通常是
7*7),然后找目标的中心落在那个网格中(得到目标中心点坐标),并且以中心点坐标为参考找出目标边框的宽与高。
如图,针对图片进行
7*7的网格划分。

所以这个图片中的两个目标
cat与person的中心点分别落在网格中的(5,1)与(3,4)两个位置,并且可以知道这个中心点相对于当前网格的坐标(就是紫色框表示的内容)。
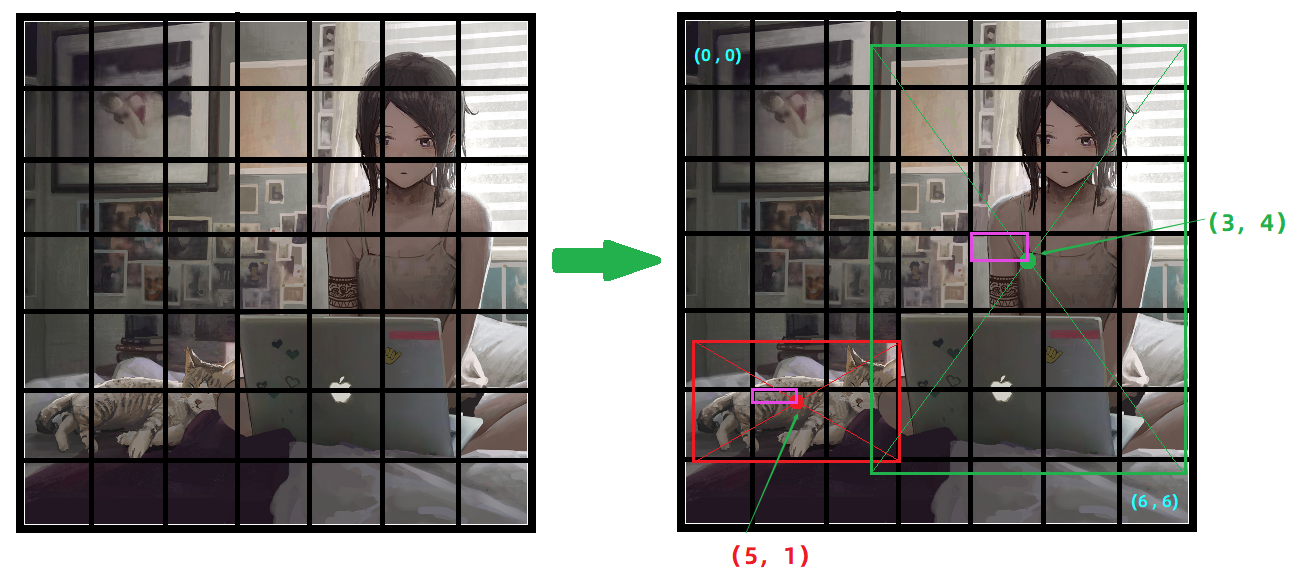
在物体中心点找出之后,以中心点为坐标找出边框的宽与高即可。
经过上边的分析,我们可以发现:想要确定一个物体,只要知道它的中心点坐标,以及相对于中心点坐标的物体宽高即可。
所以:当我们的模型拿到一张图片之后
labels的数据都是来自上边xml中提取的数据。
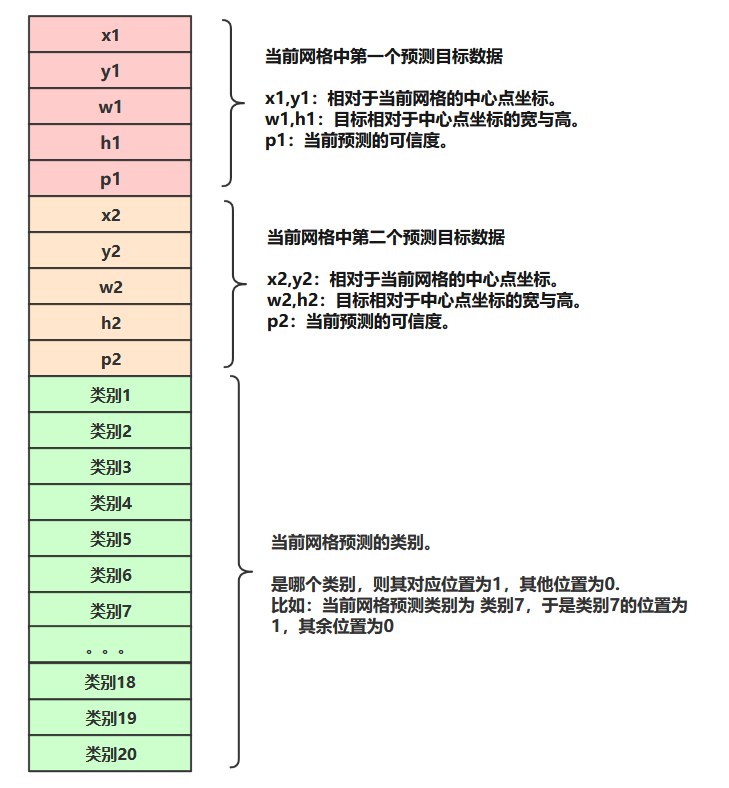
经过上边yolo运作流程的讲解,可以得知labels数据需要 针对每一个小网格 组织出:相对于当前网格中心点的坐标,宽高,预测概率,目标类别。
其中:
注意:由于每一个网格中可能会有多个目标的中心点,所以这里的labels组织的时候,将每个格子预测两个中心点。(细节见下图)
这个图是所有网格的数据形式。数据长度为30.
**这个图中的所有数据都可以根据 上文从xml中提取的数据得到。 **
由此可知,每个网格的labels是由长度为30的上述数据组成的;因为我们的图片划分为7*7个网格,所以就是有7*7个长度为30的数据组成整个图片的lables。即整张图片的labels数据形式为:7*7*30。labels数据矩阵如下图所示。
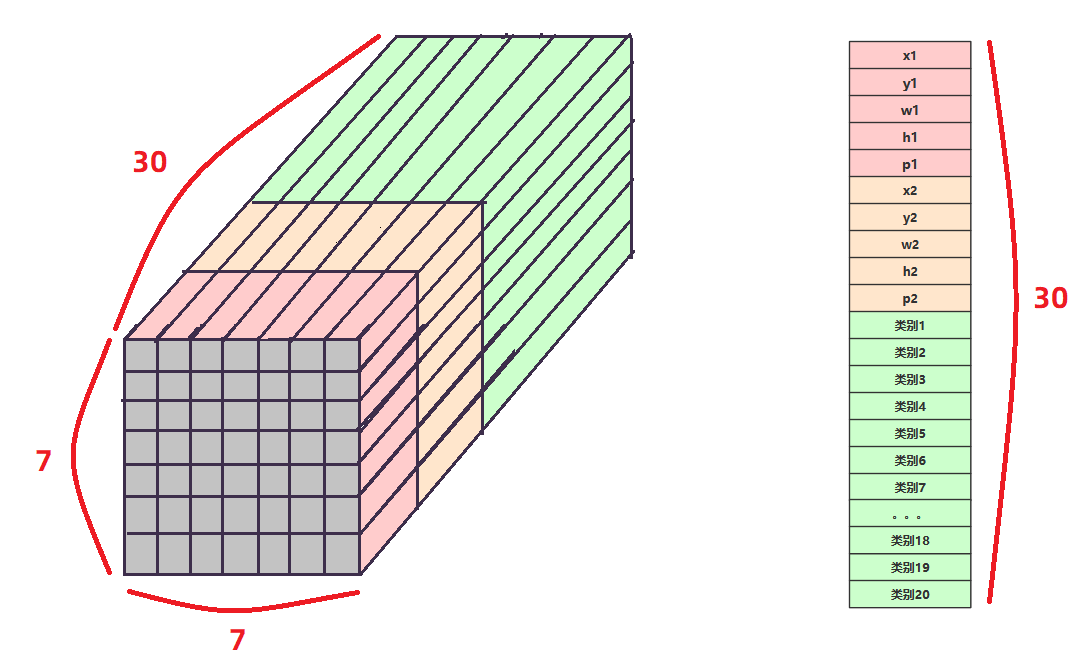
所以,我们输入网络的数据就是图片转为tensor的数据,inputs维度为:[batchsize,3,448,448].
网络的输入labels维度为:[batchsize,30,7,7]. 就是上边的数据矩阵。
网络的输出:[batchsize,30,7,7].
ok,上边的数据组织完成,那么接下来就是将组织好的 inputs 与 labels 送入网络训练即可。
IOU就是交并比,因为原来有一个正确的目标边框数据,此时我们预测一个边框数据之后,计算出两个边框相交的面积,在计算出相并的面积,然后求出比值,就是交并比。
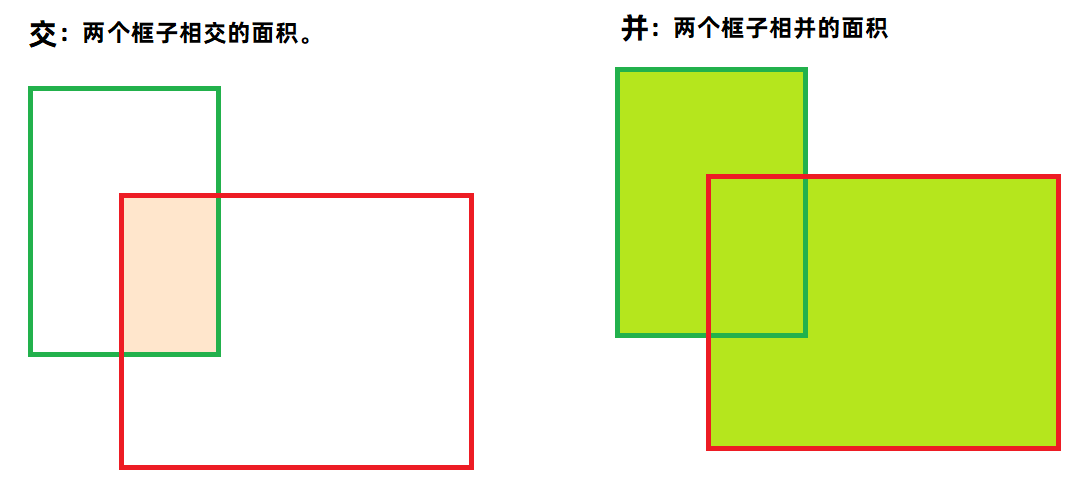
交并比越 大 ,说明两个框子越相似,说明预测结果越好。最大 IOU=1 ,就是预测框与真实框重合。
交并比越 小 ,说明两个框子越不相似,说明预测结果越差。最小 IOU=0 ,就是预测框与真实框没有一点相交的地方。
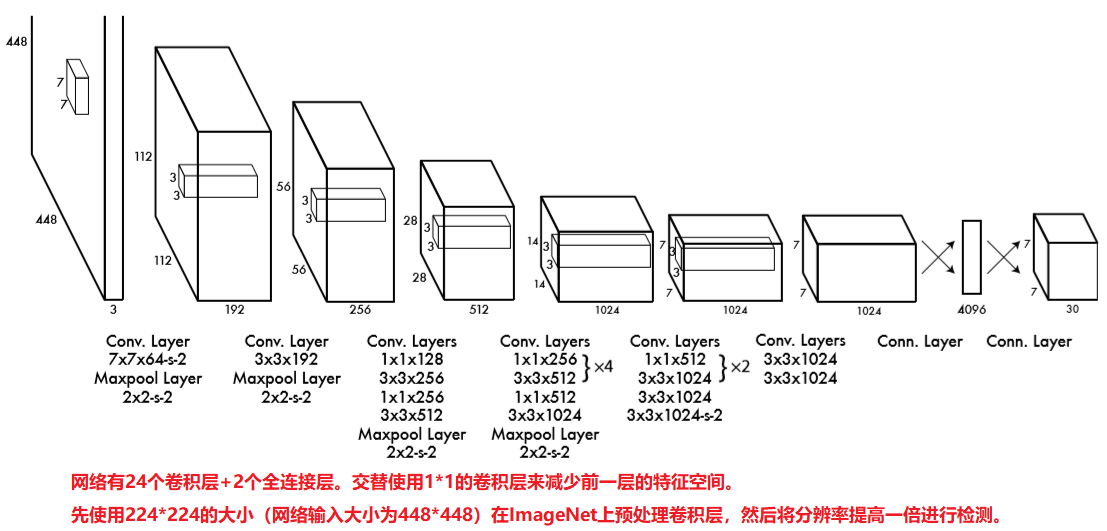
三部分组成。
目标检测入门论文YOLOV1精读以及pytorch源码复现(yolov1)
标签:标签 细节 zoom 处理 卷积层 方式 strong 形式 cal
原文地址:https://www.cnblogs.com/xiaoxiaojiea/p/14534513.html