标签:style http color ar os sp 文件 数据 on
结束historyserver的命令如下所示:

第四步:验证Hadoop分布式集群
首先在hdfs文件系统上创建两个目录,创建过程如下所示:

Hdfs中的/data/wordcount用来存放Hadoop自带的WordCount例子的数据文件,程序运行的结果输出到/output/wordcount目录中,透过Web控制可以发现我们成功创建了两个文件夹:
接下来将本地文件的数据上传到HDFS文件夹中:

透过Web控制可以发现我们成功上传了文件:

也可通过hadoop的hdfs命令在控制命令终端查看信息:

运行Hadoop自带的WordCount例子,执行如下命令:

运行过程如下:



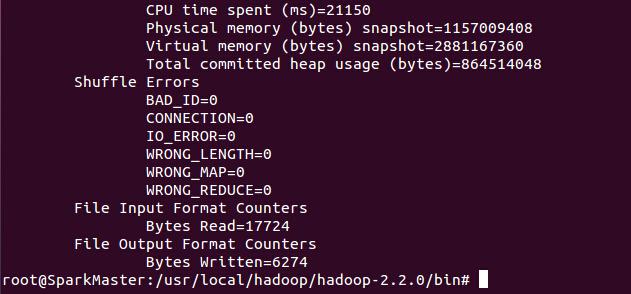
当我们在运行作业的过程中也可以查看Web控制台的信息:
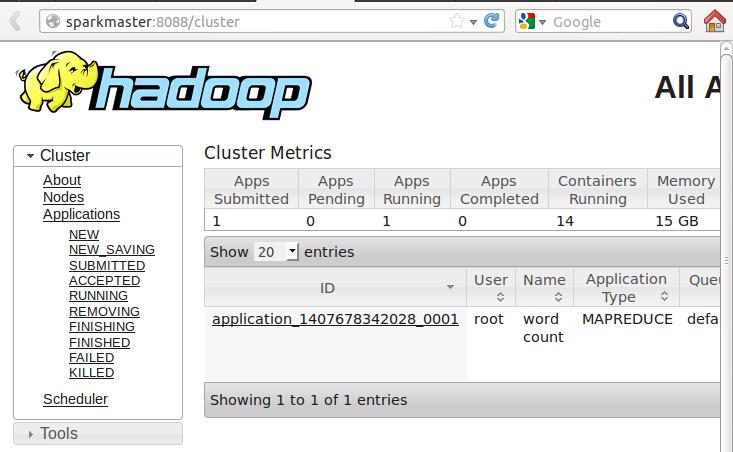
此时发现了一个作业ID,点击进入可以查看作业进一步的信息:
进一步看通过Web控制台看SparkWorker1中的Container中的运行信息:
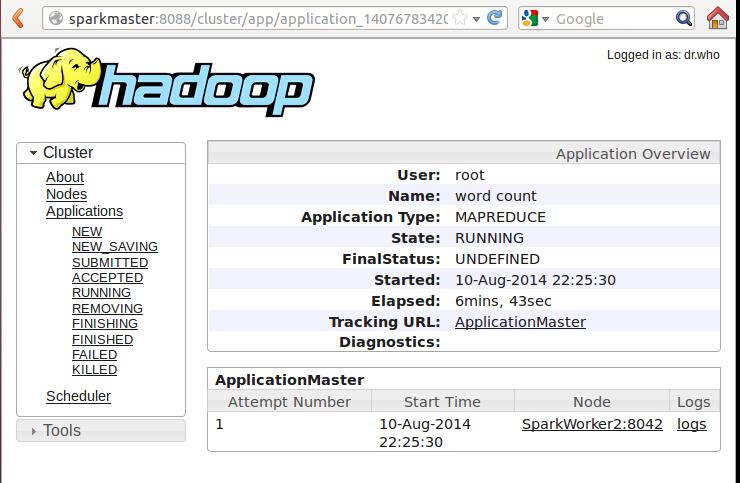

刷新Web控制台:

【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第五步)(6)
标签:style http color ar os sp 文件 数据 on
原文地址:http://my.oschina.net/u/1791057/blog/343854