标签:请求 put xtend new 业务逻辑 做什么 参数调整 应用 app
接上文,复习整理大数据相关知识点,这章节从MapReduce开始...
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
MapReduce运行在yarn集群
这两个阶段合起来正是MapReduce思想的体现。
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
Hadoop MapReduce构思:
分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
统一构架,隐藏系统层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统
层面的处理细节。
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。MapReduce
处理的数据类型是键值对。
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
Map: (k1; v1) → [(k2; v2)]
Reduce: (k2; [v2]) → [(k3; v3)]
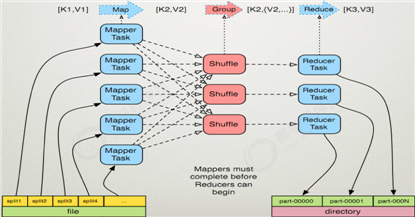
MapReduce 框架结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为 2 个步骤,Shuffle 阶段 4个步骤,Reduce 阶段分为 2 个步骤
Map 阶段 2 个步骤
Shuffle 阶段 4 个步骤
Reduce 阶段 2 个步骤
转换为代码,例子如下
Map阶段
public class WordCountMapper extends Mapper<Text,Text,Text, LongWritable> {
/**
* K1-----V1
* A -----A
* B -----B
* C -----C
*
* K2-----V2
* A -----1
* B -----1
* C -----1
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
context.write(key,new LongWritable(1));
}
}
Reduce阶段
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
shuffle阶段,举一个分区的例子:
public class WordCountPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
if (text.toString().length() > 5) {
return 1;
}
return 0;
}
}
主方法
public class JobMain extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new JobMain(),args);
}
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "wordcout");
job.setJarByClass(JobMain.class);
//输入
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/"));
//map
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//shuffle阶段
job.setPartitionerClass(WordCountPartitioner.class);
job.setNumReduceTasks(2);
//reduce阶段
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//输出
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/"));
return 0;
}
}
具体步骤:
InputFormat (默认 TextInputFormat) 会通过 getSplits 方法对输入目录中文件进行逻辑切片规划得到 splits, 有多少个 split 就对应启动多少个MapTask . split 与 block 的对应关系默认是一对一splits 之后, 由 RecordReader 对象 (默认是LineRecordReader)进行读取, 以 \n 作为分隔符, 读取一行数据, 返回 <key,value> . Key 表示每行首字符偏移值, Value 表示这一行文本内容MapReduce 提供 Partitioner 接口, 它的作用就是根据 Key 或 Value 及Reducer 的数量来决定当前的这对输出数据最终应该交由哪个 Reduce task处理, 默认对 Key Hash 后再以 Reducer 数量取模. 默认的取模方式只是为了平均 Reducer 的处理能力, 如果用户自己对 Partitioner 有需求, 可以订制并设置到 Job 上。环形缓冲区其实是一个数组, 数组中存放着 Key, Value 的序列化数据和 Key,Value 的元数据信息, 包括 Partition, Key 的起始位置, Value 的起始位置以及Value 的长度. 环形结构是一个抽象概念缓冲区是有大小限制, 默认是 100MB. 当 Mapper 的输出结果很多时, 就可能会撑爆内存, 所以需要在一定条件下将缓冲区中的数据临时写入磁盘, 然后重新利用这块缓冲区. 这个从内存往磁盘写数据的过程被称为 Spill, 中文可译为溢写. 这个溢写是由单独线程来完成, 不影响往缓冲区写 Mapper 结果的线程.溢写线程启动时不应该阻止 Mapper 的结果输出, 所以整个缓冲区有个溢写的比例 spill.percent . 这个比例默认是 0.8, 也就是当缓冲区的数据已经达到阈值 buffer size * spill percent = 100MB * 0.8 = 80MB , 溢写线程启动,锁定这 80MB 的内存, 执行溢写过程. Mapper 的输出结果还可以往剩下的20MB 内存中写, 互不影响如果 Job 设置过 Combiner, 那么现在就是使用 Combiner 的时候了. 将有相同 Key 的 Key/Value 对的 Value 加起来, 减少溢写到磁盘的数据量.Combiner 会优化 MapReduce 的中间结果, 所以它在整个模型中会多次使用那哪些场景才能使用 Combiner 呢? 从这里分析, Combiner 的输出是Reducer 的输入, Combiner 绝不能改变最终的计算结果. Combiner 只应该用于那种 Reduce 的输入 Key/Value 与输出 Key/Value 类型完全一致, 且不影响最终结果的场景. 比如累加, 最大值等. Combiner 的使用一定得慎重, 如果用好, 它对 Job 执行效率有帮助, 反之会影响 Reducer 的最终结果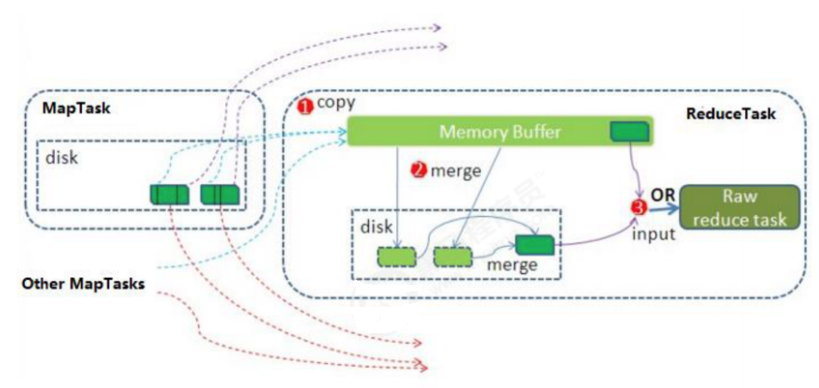
Reduce 大致分为 copy、sort、reduce 三个阶段,重点在前两个阶段。copy 阶段包含一个 eventFetcher 来获取已完成的 map 列表,由 Fetcher 线程去 copy 数据,在此过程中会启动两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行 merge。待数据 copy 完成之后,copy 阶段就完成了,开始进行 sort 阶段,sort 阶段主要是执行 finalMerge 操作,纯粹的 sort 阶段,完成之后就是 reduce 阶段,调用用户定义的 reduce 函数进行处理
详细步骤:
map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 shuffle
shuffle: 洗牌、发牌 ——(核心机制:数据分区,排序,分组,规约,合并等过程)
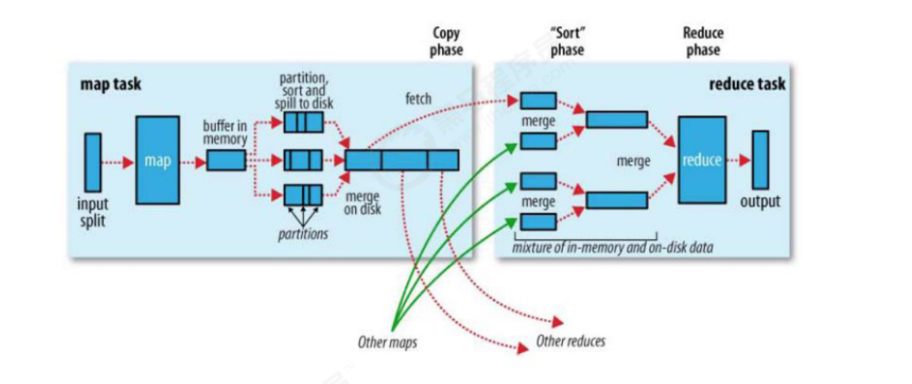
缓冲区的大小可以通过参数调整, 参数:mapreduce.task.io.sort.mb 默认100M
标签:请求 put xtend new 业务逻辑 做什么 参数调整 应用 app
原文地址:https://www.cnblogs.com/whgk/p/14547291.html