标签:ISE opd 体验 分派 包括 绘制 资源池 site 部分
Rasterization,光栅化,又称为栅格化,它用于执行绘图指令生成像素的颜色值。光栅化是渲染流水线中的一个重要环节,但是不同的 UI Toolkit 和不同浏览器渲染引擎使用的光栅化策略并不一样,本文主要讨论各种不同的光栅化策略和它们各自的优劣。

上图是一个渲染流水线的极简版示意图,适用于大部分的 UI Toolkit 和浏览器渲染引擎,当然实际的细节可能会有出入。
我们一般将 1 ~ 4 归为渲染流水线的前半段,5 和 6 归为渲染流水线的后半段,在 Chromium 里面,将 Rasterization 和 Composite 归为 Graphics。
更多关于实际的渲染流水线设计,可以参考我之前的一些文章,比如Flutter 渲染流水线浅析。
在所有光栅化策略中,直接光栅化是最简单的一种。它就是直接将所有可见图层的 DisplayList 中可见区域内的绘图指令,执行光栅化直接在目标 Surface 的像素缓冲区上生成像素的颜色值。如果是完全的直接光栅化,这时,其实就不需要后面合成的步骤了。
一般来说渲染的 Viewport 是由 Root Layer 当前的 Scroll Offset 和目标 Surface 的大小来决定。如果图层在 Viewport 范围内,它就是可见的。
像 Android 和 Flutter,它们的 UI Toolkit 主要使用直接光栅化的策略,但是同时也支持间接光栅化。它们允许为指定图层分配额外的像素缓冲区,该图层的光栅化会先写入自身的像素缓冲区,渲染引擎再将这些图层的像素缓冲区通过合成输出到目标 Surface 的像素缓冲器。
无论是直接光栅化还是间接光栅化,它们都是所谓的同步光栅化,也就是说光栅化和合成通常都在同一个线程,即使不在同一个线程,也会通过线程同步的方式来保证光栅化和合成的执行顺序。这种同时使用直接和间接光栅化的方式,有时我们也称为即时光栅化(On Demand Rasterization)。
Android 提供了 View.setLayerType 允许应用来为指定 View 分配像素缓冲区,Flutter 目前应该没有提供类似的 API,只是内部根据一定的规则来决定为特定图层分配额外的像素缓冲区。
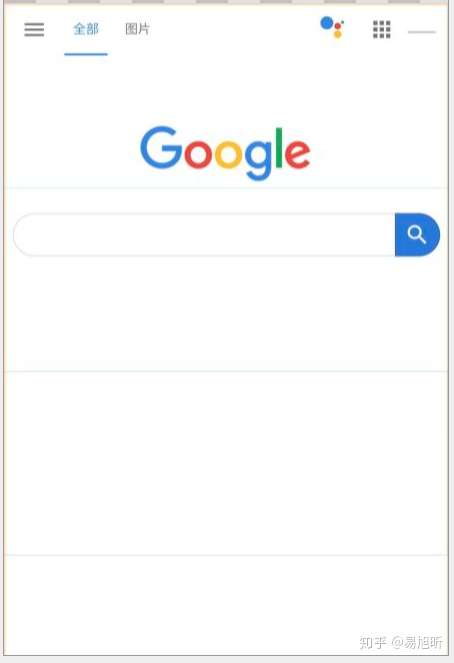
上图显示了 Google 搜索页面的图层(浅黄色)和分块(浅绿色)的边界
Chromium 使用的是异步分块光栅化的策略,除了一些特殊图层外(比如 Canvas,Video):
对于异步光栅化来说,为图层分配额外的像素缓冲区是必须的,而使用分块的方式比起分配一个完整大小的像素缓冲区有很多优势:
Android 的 UI Toolkit 和 Flutter 采用即时光栅化的策略 —— 以直接光栅化为主,光栅化和合成同步进行,在合成的过程中完成光栅化,而 Chromium 则使用异步分块的光栅化策略,这两种不同的光栅化策略,它们各自的优缺点是什么,这是接下来我们要讨论的问题。
以下内容对性能的讨论基于移动平台。
可以说内存占用是直接光栅化策略的最大优势, 采用异步分块光栅化的 Chromium 需要为每个合成器分配一个分块缓存的资源池,用于分配和回收分块缓存(像素缓冲区)。以 Android WebView 为例,它是按 WebView 可见大小的倍数(软上限是 10 倍,硬上限是 20 倍)来确定这个资源池的上限,对于 1080p 的手机,全屏大小的 WebView,一般的移动版网页,这个资源池正常会分配 40 ~ 60M 的分块缓存,峰值可能会超过 100M。如果是 2k 分辨率的手机,分块缓存的内存占用可能会翻番。并且如果多个 WebView 同时可见,分块缓存的内存占用可能是单个 WebView 的几倍(每个 WebView 的合成器是独立的)。
如果渲染引擎使用完全的直接光栅化,这就意味着不需要在合成过程中为图层额外分配任何像素缓冲区,理论上可以完全节省掉上面描述的这部分内存占用。
把首屏性能单独拿出来讨论,一是因为它是一个比较重要的指标,二是因为首屏性能比较特殊,它意味页面是全新的内容,很难通过缓存中间光栅化的结果来提升性能。很明显,在首屏性能指标上,同步光栅化的策略是更有利的,同步光栅化的渲染流水线设计通常比异步光栅化的渲染流水线设计更精炼,它可以直接发起合成,在合成的过程中执行光栅化,而不需要先分派光栅化任务,调度任务的执行,等待所有任务执行完毕后再触发合成。当然,这个提升实际上也很有限,在首屏性能上,同步光栅化通常比起异步光栅化理论上可以提前一两帧完成,可能就二三十毫秒。如果应用首屏的主要瓶颈是在加载,这点点提升其实意义不大,但有时在切换标签页这种场景,所有内容都已经提前加载完毕,那几十毫秒的提升可能都是有意义的。
如果页面的内容在不断发生变化,这意味这异步光栅化的中间缓存大部分是失效的,需要重新光栅化,在这种情况下,类似首屏性能,因为同步光栅化的渲染流水线更精炼,并且也不需要先光栅化到中间缓存再合成,减少了渲染的步骤,同步光栅化的策略通常是更有利的。
图层动画包括各种图层的移动,滚动,淡入淡出等等。在动画的过程中,图层的内容没有发生变化,对使用异步光栅化的渲染引擎来说,它的分块缓存大部分都是有效的,不需要重新光栅化,或者针对图层滚动,只有少量从不可见到可见的分块需要重新光栅化。这也意味着在动画过程中,渲染引擎大部分时间只需要重新合成输出,而分块合成的开销非常低,通常最多只需要 2 ~ 3 毫秒的耗时。所以在图层动画上,异步分块光栅化的策略会有比较明显的优势,特别是在复杂的页面上。
对于非惯性滚动的其它图层动画,Android 的 UI Toolkit,Flutter 实际上也通过间接光栅化于引入图层缓存,减少不必要的重复光栅化来提升性能,只是 Android UI Toolkit 需要应用自己设置。并且这些图层动画不像惯性滚动对掉帧这么敏感,轻微的掉帧其实也不影响视觉体验,所以异步分块光栅化最大的优势还是在惯性滚动动画上面,在惯性滚动过程中,异步分块光栅化还可以提前对 Viewport 外的区域进行预光栅化,从而提升性能和减少 Checkerboard 的现象。这也是在 Android 手机上,浏览器在页面的惯性滚动上通常比原生应用表现的更流畅,极少出现卡顿掉帧的情况。
我们继续讨论光栅化的性能问题,它对异步光栅化来说相对而言没那么关键,但是对直接光栅化来说就非常关键了。虽然我们上面说过在惯性滚动动画场景,异步分块光栅化有更大的性能优势,但是帧率是有上限的,一般为屏幕的刷新率,对于绝大部分显示屏刷新率为 60hz 的手机,要达到满帧 , 60 帧就够了。如果光栅化足够快,能够保证在 16 毫秒内完成,那在直接光栅化的策略下实现稳定 60 帧的惯性滚动动画也是可以做到的。
早期光栅化引擎只支持软件(CPU)光栅化,性能极差,UI Toolkit 如果使用直接光栅化,性能会非常糟糕,比如在 Android 2.x 时期,因为 Android UI Toolkit 只支持软件光栅化,系统图形性能糟糕,应用卡顿明显。目前,应用最广的光栅化引擎 Skia,对硬件(GPU)光栅化的支持已经十分完善,硬件光栅化,把真正对像素缓冲区进行读写(着色)的部分操作转移到了 GPU,不再前台占用 CPU 的时间,极大的提升了光栅化性能。可以说,渲染引擎使用直接光栅化策略的前提条件就是光栅化引擎支持硬件光栅化。
Android 2.x 时期使用 Skia 作为光栅化引擎,只支持软件光栅化。4.x 开始使用两套光栅化引擎,Skia 仍然用于软件光栅化,另外自己实现了一套给 HWUI 用,用于支持硬件(GPU)光栅化。9.0 开始,HWUI 又改成使用 Skia 来支持硬件光栅化,也就是说目前 Android 无论是软件还是硬件光栅化都统一使用 Skia 作为自己的光栅化引擎。
但是即使是硬件光栅化,仍然需要大量 CPU 计算的耗时,以 Skia 为例子,光栅化过程中:
第一项的耗时会导致新内容首次出现的时候(或者即使不是首次出现,但是一段时间后之前的缓存已经被释放),光栅化耗时会突然大幅增加,直接光栅化容易在这种场景导致掉帧,页面的惯性滚动过程就比较容易出现这种场景。而异步分块光栅化则因为光栅化不会阻塞合成而避免掉帧,并且通过预先光栅化 Viewport 外的不可见区域来进一步提升性能和减少 Checkerboard。
第二项的耗时,如果一个绘制指令只是重复执行,不需要产生新的资源缓存,一般来说单条指令的执行耗时其实是很低的(Skia 在目前手机上约莫在 0.0x ~ 0.1 毫秒这个范围)。但是如果绘制界面过于复杂,绘制元素太多,绘制所需的指令数太多,并且较多指令包含复杂路径(达到上百条甚至几百条这个规模),直接光栅化在低端机上也容易出现持续掉帧。
不过总的来说以当前手机 CPU 的性能,中高端手机应付第二项还是绰绰有余的(页面复杂度位于正常范围内),而第一项导致直接光栅化的偶尔掉帧虽然很难完全避免,但是对用户感受来说也不算特别严重,起码不是持续掉帧。所以随着手机 CPU 性能越好,直接光栅化策略的优势就越明显,对比异步分块光栅化,它在内存占用上有明显优势,在非图层动画外的其它场景也有一定的优势,渲染引擎通过引入间接光栅化也可以极大提升大部分图层动画的性能,除了部分场景下页面惯性滚动动画容易出现偶尔掉帧这个问题的确不好解决外,总体优势还是比较明显的。
很遗憾 Chromium 的工程师没有写一篇 How Viz Works 的文章来详细解析 Viz 这个重要的模块,能找到的一些相关文档都比较零散,所以我打算自己来写,不过个人研究深度有限,无法包括所有的细节,还请读者见谅。
计划写两到三篇文章,第一篇文章对 Viz 做一个概要的介绍,和它在 Chromium 整个合成器架构里面的角色。因为 Viz 的代码变动很快,所以文章的内容只是针对当前的版本 M75,部分内容在未来有可能会失效。
Viz 作为 Visual 的缩写,一开始的代码是源自 cc,gpu 等模块,它是 Chromium 整体架构转向服务化的一个重要组成部分。官方的文档里面说明 Viz 预计为 Chromium 其它模块提供以下四种服务:
Viz clients 分为两类,一种是 privileged client (特权客户),它只有一个,负责启动 Viz 服务,和为 unprivileged clients(非特权客户)提供 Viz 服务的访问接口,而 unprivileged clients 则仅仅是使用 Viz 服务,它可以同时存在多个。
对一个作为浏览器(非 Chrome OS)的 Chromium 来说,只有 Browser 进程可以作为 privileged client,Renderer 进程只能作为 unprivileged client。
Viz 运行在 Viz 进程,也就是以前的 GPU 进程,当然,在单进程架构下,Browser 进程可以兼做 Viz 进程。
Viz 的代码主要分布在 /services/viz 和 /components/viz 两个目录,从目录名字就差不多能够猜的出来:
不过从官方文档的说明来看,/components/viz 目录下的代码未来可能会迁入 /services/viz 里面。
Viz Mojo Service 对外提供了两个最重要的接口是 FrameSinkManager 和 CompositorFrameSink。
privileged client 通过 FrameSinkManager 接口请求创建一个 CompositorFrameSink 的实现,包括对应的 Surface,并把返回的接口传递给 unprivileged client,unprivileged client 则使用 CompositorFrameSink 的接口来提交 CompositorFrame 给 Display Compositor。我们后面还会详细讲述。
在继续解析 Viz 之前,我们需要了解目前 Chromium 合成输出的合成器架构,Compositor Stack 这篇文档比较详细地介绍了 Chromium 合成器架构的历史变迁,可以作为读者的参考。关于 Layer Compositor,更详尽的信息可以参考文章 How cc Works。
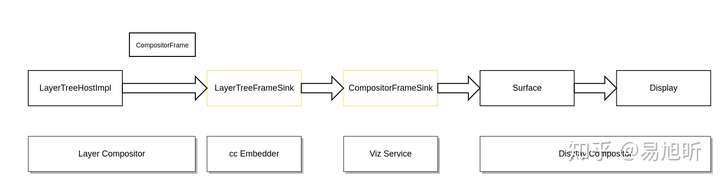
上图显示网页内容合成输出的一个合成器架构的简化示意图,需要说明的是 Chromium 目前的合成器架构并不仅仅限于网页内容的合成,包括浏览器 UI,多媒体,插件,Offscreen Canvas 等都可以通过这套合成器架构进行合成输出。Surface 和 Display 并不是一一对应的关系,一个 Display 实际上对应的是一棵父子结构的 Surface 树。
从上图我们可以看到:
后面的文章再继续讲述不同的 Chromium Configurations 实际的合成器架构。
Chromium 关于光栅化和合成的一些主要性能优化项目包括 OOPD (Out of Process Display Compositor,进程外 Display 合成器), OOPR (Out of Process Rasterization,进程外光栅化) 和 SkiaRenderer。
我们在Chromium Viz 浅析 - 合成器架构篇介绍过 OOPD,它的主要目的是将 Display Compositor 从 Browser 进程迁移到 Viz 进程(也就是原来的 GPU 进程),Browser 则变成了 Viz 的一个 Client,Renderer 跟 Viz 建立链接(CompositorFrameSink)虽然还是要通过 Browser,但是建立链接后提交 CompositorFrame 就是直接提交给 Viz 了。Browser 同样也是提交 CompositorFrame 给 Viz,最后在 Viz 生成最终的 CompositorFrame,通过 Display 交由 Renderer 合成输出。
在How cc Works 中文译文一文中,我们简单提及过 OOPR。OOPR 跟目前的 GPU 光栅化机制的主要区别是:
简而言之,就是将 Skia 光栅化的部分从 Renderer 进程转移到了 Viz 进程。
本文接下来的部分我们会对 SkiaRenderer 和 SkiaOutputSurface 进行分析。
在继续分析 SkiaRenderer 和 SkiaOutputSurface 之前,我们先简单介绍一下它们的基类 DirectRenderer 和 OutputSurface。
顾名思义,DirectRenderer 是 Display 用来合成输出最终的 CompositorFrame,它遍历 CompositorFrame 中的每一个 RenderPass,遍历每个 RenderPass 中的每个 DrawQuad,为每个 DrawQuad 生成相应的绘制指令。而 OutputSurface 则用来为最终的合成输出提供一个目标 Surface,对 Renderer 来说,它的主要作用是为 Renderer 提供一个绘图上下文。
在 SkiaRenderer 之前,我们在 GPU 合成时,使用的 Renderer 是 GLRenderer,顾名思义,它为每个 DrawQuad 生成的绘制指令是 GL 指令,它需要 OutputSurface 提供一个 ContextProvider 作为绘图上下文,通过 ContextProvider GLRenderer 可以获取一个基于 Command Buffer 的 GL 接口,然后通过该 GL 接口发出 GL 指令。
历史上还曾经有过 DelegatingRenderer,跟 DirectRenderer 对应,但是新的合成器架构应用后,DelegatingRenderer 已经不再需要了,所以现在只有 DirectRenderer 和它的派生类。
当我们开启 OOPD 后,Display Compositor 就运行在 Viz 进程的 Viz Compositor 线程,这意味则它跟 GPU 线程是同一个进程,理论上就不再需要使用 Command Buffer,虽然目前的 GLRenderer 还是需要使用一个 InProcessCommandBuffer 来做跨线程的 GL 指令调用。而 SkiaRenderer 则让我们可以完全避免在合成过程中使用 Command Buffer。
跟 GLRenderer 对应,SkiaRenderer 为每个 DrawQuad 生成的绘制指令是一个 Skia 的绘制指令,通过 SkiaOutputSurface 提供的 SkCanvas 输出。SkiaOutputSurface 有两个派生类 SkiaOutputSurfaceImpl 和 SkiaOutputSurfaceImplNonDDL,SkiaOutputSurfaceImplNonDDL 应该只是一个 Android WebView 的特殊合成器架构在重构过程中使用的一个过渡实现,所以我们重点讲解 SkiaOutputSurfaceImpl。
之前我们讲过 Display Compositor 运行在 Viz Compositor 线程,由它来调用 SkiaRenderer,但是 Skia 输出的 GPU 指令必须在 GPU 线程才能执行。所以实际上 SkiaOutputSurfaceImpl 给 SkiaRenderer 提供的 SkCanvas,它的目标 SkSurface 并不是真正用于当前输出的 SkSurface,而是一个 Compatible SkSurface。SkiaOutputSurfaceImpl 使用最终 SkSurface 的特征信息生成 SkDeferredDisplayListRecorder,然后获取 SkDeferredDisplayListRecorder 提供的 SkCanvas,SkiaRenderer 通过该 SkCanvas 输出的绘制指令实际上被存储到 Recorder 内部的 SkDeferredDisplayList 中。
当 SkiaRenderer 绘制完一个 RenderPass 后,SkiaOutputSurfaceImpl 从 SkDeferredDisplayListRecorder 剥离对应的 SkDeferredDisplayList,然后通过 Post GPU Task 的方式传递给在 GPU 线程等待的 SkiaOutputSurfaceImplOnGpu,SkiaOutputSurfaceImplOnGpu 再将这个 SkDeferredDisplayList playback 到真正输出的 SkSurface 上。
Promise SkImage 是一个蛮有意思的概念,它的引入主要是因为 SkiaRenderer 运行在 Viz Compositor 线程,并没有 GPU 上下文,所以当它需要绘制一个图片时,此时无法访问该图片对应的 GPU 资源,但是实际上该图片又是一个 GPU 资源的引用。不过因为 SkiaRenderer 是先绘制到 SkDeferredDisplayList,然后 SkDeferredDisplayList 再在 GPU 线程被 playback,所以引入了 Promise SkImage 来解决这个问题。
Promise SkImage 实际上是一个 placeholder,它包含了一些用于定位对应 GPU 资源的 meta 信息和一组回调函数的指针,当 SkDeferredDisplayList 被 playback 过程中,当需要绘制该 Promise SkImage 时,就会调用这些回调函数进行 Fulfill,Fulfill 回调函数会返回一个包含对应的 GPU 资源信息 SkPromiseImageTexture 供 Skia 使用。
所以 Promise SkImage 实际上就是 - "Make a promise, and fulfill in future"。
仅仅是用 SkiaRenderer 替换原来的 GLRenderer,其实并没有马上带来什么性能上的优势。诚然,SkiaRenderer 不需要使用 Command Buffer,省去了 Encode/Decode 的开销,但是 Skia 本身的开销也不小,两相比较,也很难说有多少性能提升。所以 SkiaRenderer 更多是跟 OOPR 一起,为后续的进一步渲染性能优化打下基础。
我们可以看到,当 OOPD,OOPR 和 SkiaRenderer 都开启后:
这意味着,当 Skia 对 Vulkan,Metal,DX12 等其它 3D API 的支持完善后,Chromium 就可以根据不同的平台和设备,来决定 Skia 使用哪个 GPU API 来做光栅化和合成。而 Vulkan,Metal,DX12 这些更 Low Level 的 3D API,对比 GL API,可以带来更低的 CPU 开销和更好的性能。
标签:ISE opd 体验 分派 包括 绘制 资源池 site 部分
原文地址:https://www.cnblogs.com/bigben0123/p/14551345.html