标签:strong 显示 路径 nbsp 标记 深度学习 扩展 智能控制 abs
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Nature Machine Intelligence 2020
Abstract
人工智能在高风险决策应用中的主要目标是设计一种算法,该算法通过学习其世界的相关表征及其动态的可解释性解释,来同时表达可概括性。在此,我们结合了大脑启发的神经计算原理和可扩展的深度学习结构,设计出了紧凑的神经控制器,用于全栈自动驾驶汽车控制系统的任务特定舱室。我们发现,具有19个控制神经元的单个算法通过253个突触将32个封装的输入特征连接到输出,可以学习将高维输入映射为操纵命令。与数量级较大的黑盒学习系统相比,该系统显示出卓越的通用性,可解释性和鲁棒性。 获得的神经智能体可以为复杂的自治系统中任务特定的部分实现高保真自治。
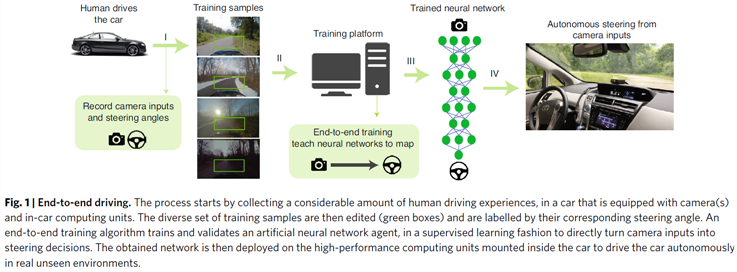
我们着手设计一种受大脑启发的智能体,该智能体可以直接从其摄像头输入中学习控制自动驾驶汽车(端到端学习控制1,2)。该智能体必须从多维感官信息中学习其世界的连贯表征,并利用它在看不见的情况下很好地进行泛化。令人惊讶的是,通过其近乎最佳的神经系统结构6,7以及和谐的神经信息处理机制,像秀丽线虫一样小的动物已经掌握了这样一个能力,用于执行运动3,运动控制4和导航5的能力。在复杂的现实世界场景中,例如,自动驾驶,这种神经计算的灵感9,10可以引出具有准确且可解释的模型的更具表现力的人工智能体11。
尽管深度学习算法在各种高维任务中取得了显著的成就2,12-16,但是仍然存在着重要的表征学习挑战17-19。例如,端到端控制的领域对安全至关重要。这要求智能控制器具有可解释的动态特性,这是研究其安全问题的第一步。此外,虽然学到的车辆控制智能体通常在离线测试和模拟中表现出出色的性能,但在实时驾驶中这会大大降低。另外,期望智能体在观察到的驾驶场景与其相应的最佳转向命令(智能体的特定任务)之间学习真正的因果结构21,22。理想情况下,对于保持车道的任务,我们希望智能体在做出当前的转向决策时隐式地学习遵守道路的地平线,同时在短期转向时保持出色的表现。然而,在实践中,性能模型已被证明可以学习各种不公平23和次优22的投入产出因果结构24,25。最后,在高维数据流输入的处理流水线中,智能体必须合并捕获时间依赖性的短期存储机制。
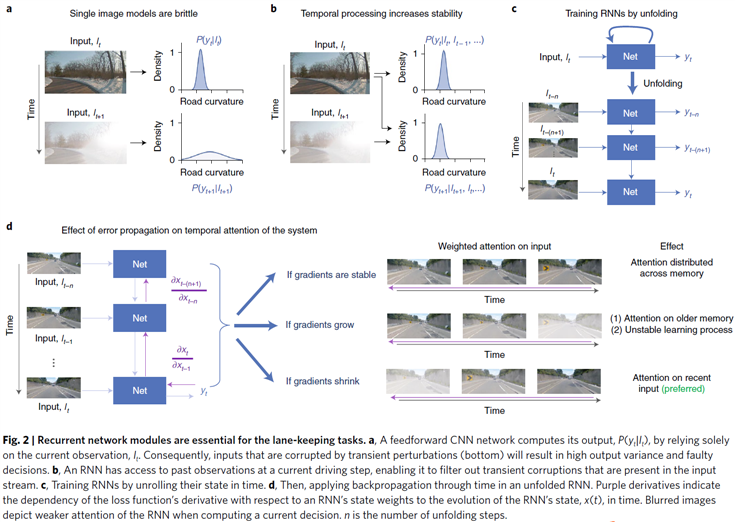
成功的端到端自主控制方法2,26–28(图1)仅依赖于深度卷积神经网络结构29,基于最新的摄像头帧在时间 t 转向车辆30(2a)。尽管在输入数据理想的情况下,这种前馈模型可以正确地驱动车辆,但如果数据嘈杂,它们通常会失败。这是因为它们没有利用任务的时间性质,从而使它们能够滤除瞬态干扰。作为结果,输入流的暂时损坏(即如图2a所示的突然的阳光照射)导致不稳定的预测。相反,循环神经网络(RNN)31,32是一类人工神经网络,通过反馈机制考虑了当前输出决策时的过去观察。因此,原则上,它们应导致更强大的端到端控制器(图2b)。RNN通过应用于其展开前馈表示32的反向传播算法33在有限长度的标记训练序列上进行训练(图2c,d)。从历史上看,由于在学习阶段梯度RNN升高或消失,训练RNN一直具有挑战性31,32。由于先进的门控RNN的发展,例如长短期记忆(LSTM)34,通过将循环权重固定为1并消除反馈路径中的非线性,强制执行恒定的误差流来解决这一挑战31。
从时间序列建模的角度来看,具有恒定的误差流是理想的属性,因为任意数据序列可能具有长期关系(图2d,右)。但是,在端到端自动驾驶的情况下,由于基础任务的短期因果关系,学习长期依赖关系可能是有害的。当驾驶车辆沿着车道行驶时,人们不会回想起几秒钟前操作方向盘的道路图像35。因此,LSTM网络可能会捕获训练数据中可能存在的虚假长期依赖关系,从而学习不足的因果模型21。相反,梯度消失使RNN无法学习具有长期依赖性的事件的相关性36-38。该属性反直观地提高了学到的RNN智能体的真实世界的控制性能,因为它优先考虑网络的时间注意力范围,而不是最近的观察结果。
普遍满足上述表示学习挑战的单个任务特定算法的开发一直是人工智能的主要目标9,10。为了朝着这个目标前进,我们从已知在生物大脑中发生的神经计算中汲取灵感6,7,39,40,并实现了显著程度的可控制性3–5,8。我们开发了称为神经回路策略(NCP)的紧凑表征,与现代深度模型相比,其中每个神经元都具有增强的计算能力41。我们表明,NCP导致稀疏网络更易于解释,并在自动驾驶的背景下证明了这一点。我们发现,对于上述车道保持任务,结合紧凑型卷积神经网络(CNN)29,可以实现非常小的大脑启发性神经模型网络(即具有仅由19个神经元组成的控制室的网络)。与最新模型相比,在学习如何直接从高维度输入中引导车辆方面具有卓越的性能。在此,我们使用表示学习的挑战作为评估自主控制智能体性能的主要标准。
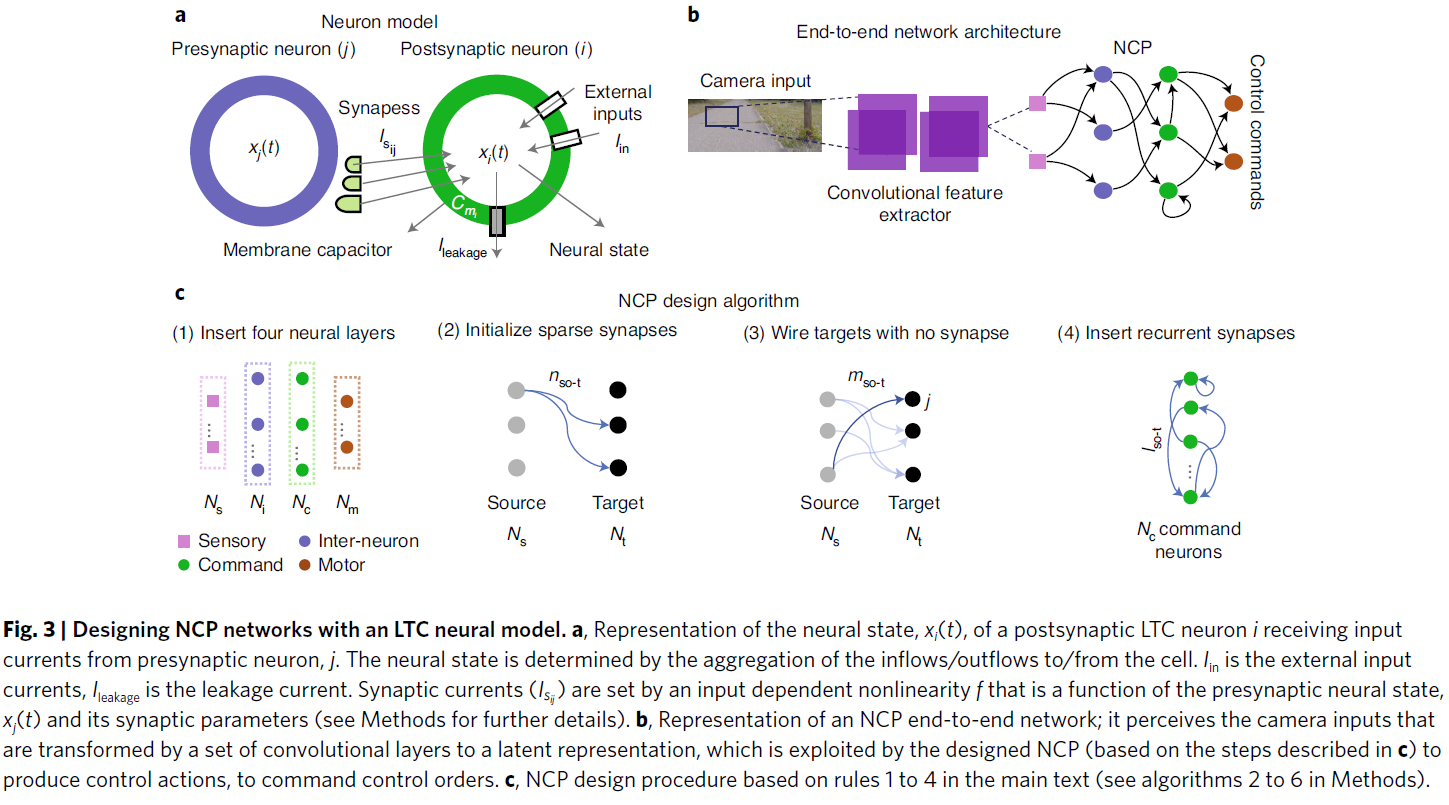
Designing and learning NCPs
Neural circuit policies enabling auditable autonomy
标签:strong 显示 路径 nbsp 标记 深度学习 扩展 智能控制 abs
原文地址:https://www.cnblogs.com/lucifer1997/p/14587182.html