标签:0ms 默认 信息 inline let 设计 goroutine 退出 日志
调度本身是指操作系统中为每个任务分配其所需资源的方法。
在操作系充中,线程是任务执行的最小单位,是系统调度的基本单元。
虽然线程比进程轻量,但是在调度时也有比较大的额外开销,每个线程都会占用几M的内存,上下文切换时也会消耗几微秒的时间,这些都是高并发的阻碍。
Go语言的诞生有一个很重要的目的就是并发编程,所以开发者为Go语言设计了一个调度器来解决这些问题。
Go的调度器通过使用与CPU数量相等的线程减少线程频繁切换的内存和时间开销,同时在每一个线程上执行额外开销更低的协程来降低资源占用,完成更高并发。
最初的调度器极其简陋,只有40多行代码,程序只能存在一个活跃线程,由 \(G\) (goroutine) - \(M\) (thread)组成。
加入了多线程后,可以运行多线程任务了,但是存在严重的同步竞争问题。
引入了处理器 \(P\) (processor),构成了GMP模型。\(P\) 是调度器的中心,任何线程想要运行 \(G\) ,都必须服务 \(P\) 的安排,由 \(P\) 完成任务窃取。如果 \(G\) 发生阻塞,\(G\) 并不会主动让出线程,导致其他 \(G\) 饥饿。
另外,这一版的调度器的垃圾回收机制使用了比较笨重的 \(SWT\) (stop the world)机制,在回收垃圾时,会暂停程序很长时间。
抢占式调度器也发展了两个阶段:
对运行时的各种资源进行分区,但实现非常复杂,只停留在理论阶段。
最初的调度器只包括 \(G\) 和 \(M\) 两种结构,全局只有一个线程,所以系统中只能一个任务一个任务地执行,一旦发生阻塞,整个后续任务都无法执行。
单进程调度器的意义就是建立了 \(G\) 、\(M\) 结构,为后续的调度器发展打下了基础。
在1.0版本中,Go更换了多线程调度器,与单线程调度器相比,可以说是质的飞跃。
多线程调度器的整体逻辑与单线程调度器没有太大的区别,因为引入了多线程,所以Go使用环境变量GOMAXPROCS帮助我们灵活控制程序中的最大处理器数,即活跃线程数。
多线程调度器的主要问题是调度时的锁竞争会严重浪费资源,有14%的时间浪费在此。
主要问题有:
基于任务窃取的Go语言调度器使用了沿用至今的GMP模型,主要改进了两点:
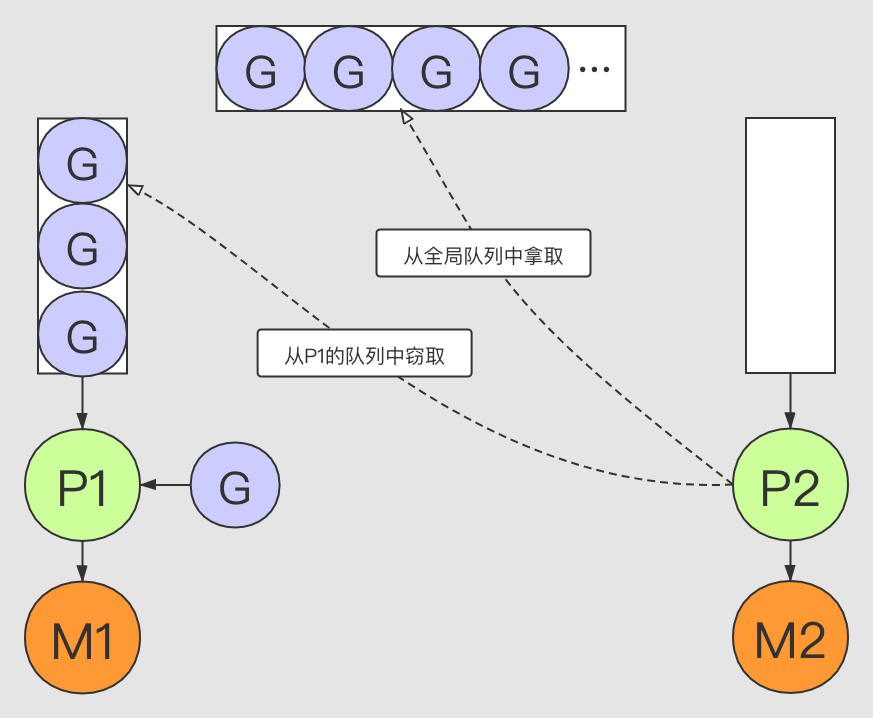
当前处理器P的本地队列中如果没有 \(G\) ,就会触发工作窃取,从其他的 \(P\) 的队列中随机获取一些 \(G\) 。调度器在调度时会将P的本地队列的队列头的 \(G\) 取出来,放到 \(M\) 上执行。
Goroutine/G 是 Go 语言调度器中待执行的任务,它在运行时调度器的地位与线程在操作系统中差不多,但它占用更小的空间,也极大地降低了上下文切换的开销。
\(G\) 只存在于 Go 语言的运行时,它只是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,能够在高并发的场景下更高效地利用机器的资源。
M的数量最多可以创建10000个,但其中大多数都不会执行用户代码而是陷入系统调用,最多也只有GOMAXPROCS个线程能够正常运行。
默认情况下,程序运行时会将GOMAXPROCS设置为当前机器的核数。且大多数情况下,我们都会使用 Go 的默认设置,也就是线程数等于 CPU 数。因为默认的设置不会频繁地触发操作系统的线程调度和上下文切换,所有的调度都发生在用户态,由 Go 语言调度器触发,能减少很多额外开销。
每个M都有两个 \(G\) ,G0和curg。G0是持有调度栈的 \(G\) ,curg是当前线程上运行的用户 \(G\) ,这是操作系统唯一关心的两个 \(G\) 。
G0深度参与 \(G\) 的调度,包括 \(G\) 的创建、大内存分配和 CGO 函数的执行。
Processor/P 是 \(G\) 和 \(M\) 的中间层,提供 \(G\) 需要的上下文环境,也负责调度 \(P\) 的等待队列和全局等待队列。
通过 \(P\) 的调度,每一个 \(M\) 都能够执行多个 \(G\) 。当 \(G\) 进行 I/O 操作时,\(P\) 会让这个 \(G\) 让出计算资源,提高 \(M\) 的利用率。
调度器会在启动时创建GOMAXPROCS个处理器,所以 \(P\) 的数量一定会等于GOMAXPROCS,这些 \(P\) 会绑定到不同的 \(M\) 上。
因为窃取式调度器存在饥饿和 \(STW\) 耗时过长的问题,所以后续又推出了基于协作的抢占式调度器。
StackPreempt标记需要抢占的 \(G\)这种方式虽然增加了运行时的复杂度,但实现相对简单,没有带来额外开销,因为其是通过编绎器插入函数并通过调度函数作为入口触发抢占,所以是协作式的抢占。
协作抢占在一定程度上解决了窃取调度中的问题,但却产生了严重的边缘问题,非常影响开发体验[1]。
为了改善这些问题,在 1.14 版本中实现了非协作式的抢占式调度,为 \(G\) 增加新的状态和字段并改变原逻辑实现抢占。
程序初始化时会创建初始线程 \(M_0\) 和主协程 \(G_0\)[2],并将 \(G_0\) 绑定到 \(M_0\) 。
\(M_0\) 是启动程序后的编号为 0 的主线程,这个 \(M\) 对应的实例会在全局变量runtime.m0中,不需要在heap上分配,\(M0\) 负责执行初始化操作和启动第一个 \(G\) , 在之后 \(M_0\) 就和其他的 \(M\) 一样了。
\(G_0\) 是每次启动一个M都会第一个创建的gourtine,\(G_0\) 仅用于负责调度的 \(G\) ,\(G_0\) 不指向任何可执行的函数, 每个 \(M\) 都会有一个自己的 \(G_0\) 。在调度或系统调用时会使用 \(G_0\) 的栈空间。
系统初始化完毕后调用调度器初始化,此时会将maxmcount设置为10000,这是一个 Go 程序能够创建的最大线程数,虽然可以创建10000个线程,但是可以同时运行的 \(M\) 还中由GOMAXPROCS变量控制。
从环境变量中获取了GOMAXPROCS后就会更新程序中 \(P\) 的数量,这时整个程序不会执行任何用户的 \(G\) ,\(P\) 也会进入锁定状态。
GOMAXPROCS就扩容nil的位置使用new方法创建新的 \(P\) ,并调用 \(P\) 的初始化函数GOMAXPROCS,则截断全局队列使其相等[3]GOMAXPROCS的情况,所以这里的不相等,就是大于等于GOMAXPROCS之后调度器会完成相应数量的 \(P\) 的启动,等待用户创建新的 \(G\) 并为 \(G\) 调度处理器资源。
想在启动一个新的 \(G\) 来执行任务,需要使用 Go 语言的go关键字。
编绎器会根据go后的函数和当前调用程序创建新的 \(G\) 结构体并加入 \(P\) 的本地运行队列或者全局运行队列中。
当本地运行队列满时,会将本地队列中的一部分 \(G\) 和待加入的 \(G\) 添加到全局运行队列中。
\(P\) 的本地运行队列最多可以存储256个 \(G\) 。
调度器启动后,初始化 \(G_0\) 的栈,然后初始化线程并进入调度循环。
所以当前函数一定会返回一个可执行的 \(G\) ,如果实再获取不到,就会阻塞等待。
\(G_0\) 将获取到的 \(G\) 调度到当前 \(M\) 上执行。
当前的 \(G\) 执行完毕后,\(G_0\) 会重新执行调度函数触发新一轮的调度。
Go 语言的运行时调度是一个循环的过程,永不返回。
上面是 \(G\) 正常执行的调度过程,但实际上,\(G\) 也可能不正常执行,比如阻塞住,此时调度器会断开当前 \(M\) 和 \(P\) 的关系,创建或从休眠队列中获取一个新的 \(M\) 重新与 \(P\) 组合。原 \(M\) 和 \(G\) 会有一个超时时间,如果此期间没能执行完成,将会释放 \(M\) ,\(M\) 或休眠,或获取一个空闲的 \(P\) 继续工作,继续开始新的调度过程。
Go 语言的运行时会通过调度器改变线程的所有权,也提供了 runtime.LockOSThread 和 runtime.UnlockOSThread 让我们有能力绑定 Goroutine 和线程完成一些比较特殊的操作。
Goroutine 应该在调用操作系统服务或者依赖线程状态的非 Go 语言库时调用 runtime.LockOSThread 函数,例如:C 语言图形库等。
当 Goroutine 执行完特殊操作后,会分离 Goroutine 和线程。
在多数情况下,都用不到这一对函数。
Go 语言的运行时通过 \(M\) 执行 \(P\),如果没有空闲 \(M\) 就会创建新的 \(M\) 。
新创建线程只有主动调用退出命令或启动函数runtime.mstart返回时主动退出。
由此完成线程从创建到销毁的整个闭环。
当 GMP 组合 \(P\) 的本地队列中没有 \(G\) 时,\(M\) 就是自旋线程,自旋线程就会如果[2.3.1](#2.3.1 获取 \(G\))中所说一直阻塞查找 \(G\)。
自旋本质是保持线程运行,销毁再创建一个新的线程要消耗大量的CPU资源和时间。
如果创建了一个新的 \(G\) ,立即能被自旋线程捕获,而如果新建线程则不能保持即时性,也就降低了效率。
但自旋线程数量也不宜过多,过多的自旋线程同样也是浪费CPU资源,所以系统中最多有GOMAXPROCS个自旋线程,通常数量有GOMAXPROCS - 正在运行的非自旋线程数量,多余的线程会休眠或被销毁。
go tool trace记录了运行时的信息,能提供可视化的web页面。
测试代码:
// trace.go
package main
import (
"os"
"fmt"
"runtime/trace"
)
func main() {
//创建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
//启动trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
//main
fmt.Println("Hello World")
}
运行程序:
$ go run trace.go
会得到一个trace.out文件,然后可以用go内置的trace打开这个文件:
$ go tool trace -http=0.0.0.0:9999 trace.out
2021/03/28 17:29:24 Parsing trace...
2021/03/28 17:29:24 Splitting trace...
2021/03/28 17:29:24 Opening browser. Trace viewer is listening on http://[::]:9999
访问http://127.0.0.1:9999/trace或你指定的host:port可以查看可视化的调度过程。

点击 Goroutines 对应的那一条蓝色矩形,下面的窗口会输入一些详细信息

程序运行过程中一共创建了两个 \(G\) ,其中一个是必须创建的 \(G_0\) 。
所以 \(G_1\) 才是 main goroutine ,从可运行状态变为正在运行,然后程序结束。
点击 Thread 对应的紫色矩形:

一共有两个 \(M\) ,其中一个是 \(M_0\) ,程序初始化时创建。
\(G_1\) 中调用的main.main,创建了本次使用的trace G \(G_2\) ,\(G_1\) 运行在 \(P_1\) 上, \(G_2\) 运行在 \(P_0\) 上。
//trace2.go
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i < 5; i++ {
time.Sleep(time.Second)
fmt.Println("Hello World")
}
}
需要先编绎:
$ go build trace2.go
运行:
$ GODEBUG=schedtrace=1000 ./trace
SCHED 0ms: gomaxprocs=2 idleprocs=0 threads=5 spinningthreads=1 idlethreads=1 runqueue=0 [0 0]
Hello World
SCHED 1009ms: gomaxprocs=2 idleprocs=2 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0]
Hello World
SCHED 2016ms: gomaxprocs=2 idleprocs=2 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0]
Hello World
SCHED 3022ms: gomaxprocs=2 idleprocs=2 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0]
Hello World
SCHED 4030ms: gomaxprocs=2 idleprocs=2 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0]
Hello World
关键字说明:
SCHED 调度器的缩写,标志本行输入是 Goroutine 调度器的输出0ms 从程序启动到输出这行日志经过的时间gomaxprocs 最大活跃线程/ \(P\) 的数量,与CPU数量一致idleprocs 空闲 \(P\) 数量threads 系统线程数量spinningthreads 自旋线程数量idlethreads 空闲线程数量runqueue 调度器全局队列中 \(G\) 的数量[0 0] 分别为2个 \(P\) 的本地队列中 \(G\) 的数量标签:0ms 默认 信息 inline let 设计 goroutine 退出 日志
原文地址:https://www.cnblogs.com/thepoy/p/14593796.html