标签:inf cluster net 分片 ica load attr public hosts
本文主要介绍ElasticSearch冷热分离架构以及实现。
冷热分离是目前ES非常火的一个架构,它充分的利用的集群机器的优劣来实现资源的调度分配。ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键点为使用固态磁盘存储数据。若全部使用固态,成本过高,且存放冷数据较为浪费,因而使用普通机械磁盘与固态磁盘混搭,可做到资源充分利用,性能大幅提升的目标。因此我们可以将实时数据(5天内)存储到热节点中,历史数据(5天前)的存储到冷节点中,并且可以利用ES自身的特性,根据时间将热节点的数据迁移到冷节点中,这里因为我们是按天建立索引库,因此数据迁移会更加的方便。
架构图:
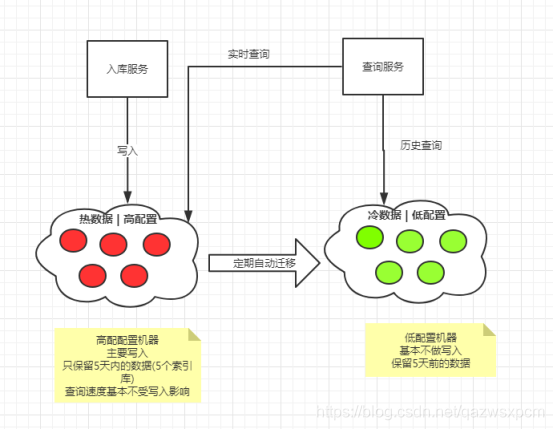
使用冷热分离的时候,我们需要将索引库建立在热节点中,等到一定的时间时间在将该索引库迁移冷节点中。因此这里我们需要更加热节点的量来进行设置分片数。
比如,我们拥有6个热节点,9个冷节点,索引库的主分片的数据量500G左右,那么该索引库建立18个分片并且都在在热节点中,此时该索引库的分片的分布是,热节点:18,冷节点0;等到该数据不是热数据之后,将该索引库的分片全部迁移到冷节点中,索引库的分片的分布是, 热节点:0,冷节点18。
单个索引库热冷节点分片分布示例:
| 时间 | 索引库名称 | 热节点分片数量 | 冷节点分片数量 |
|---|---|---|---|
| 20190707 | TEST_20190703 | 18 | 0 |
| 20190708 | TEST_20190703 | 0 | 18 |
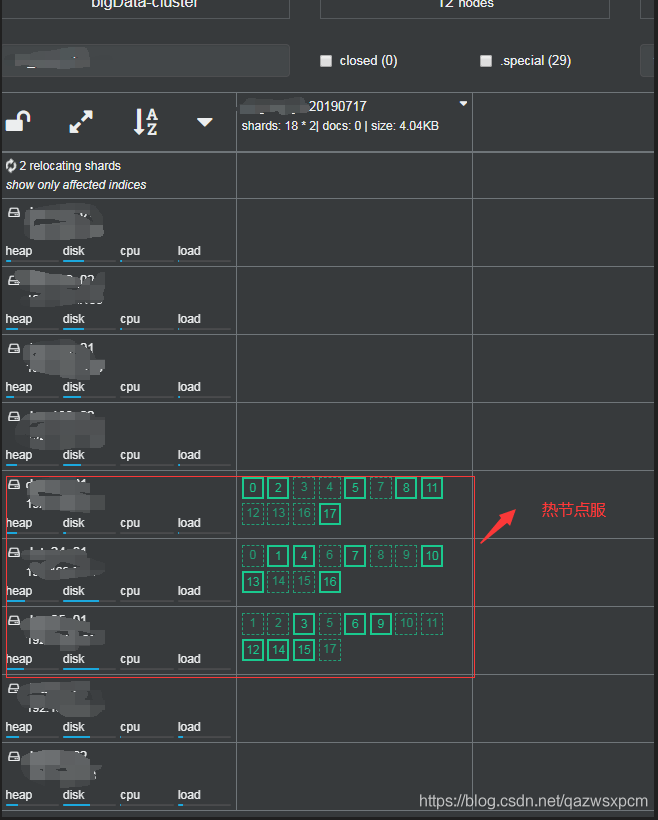
最终实现效果图,这里我用cerebro界面截图来表示
cerebro示例图:
写入ES索引库中,分片分布在热节点中
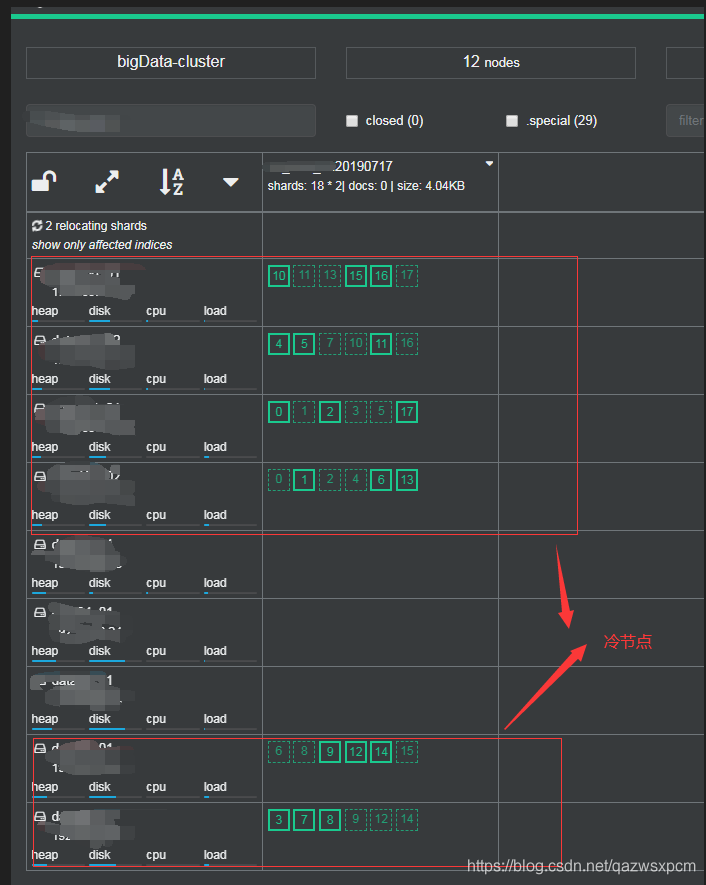
过了一段时间之后进行了迁移,分片数据迁移到了冷节点:
更多ElasticSearch的相关介绍可以查看我的这篇博文:https://www.cnblogs.com/xuwujing/p/12093933.html
ElasticSearch冷热分离架构是一种思想,其实现原理是使用ElasticSearch的路由完成,在data节点设置对应的路由,然后在创建索引库时指定分布到那些服务器,过一段时间之后,根据业务要求在将这些索引库的数据进行迁移到其他data节点中。
这里需要改变的节点为data节点,其他的节点配置无需更改。这里我就用以前写的ElasticSearch实战系列一: ElasticSearch集群+Kibana安装教程里面的配置进行更改。
data节点的elasticsearch.yml原配置:
cluster.name: pancm
node.name: data1
path.data: /home/elk/datanode/data
path.logs: /home/elk/datanode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9300
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: false
node.data: true
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
相比普通的data节点, 主要是增加了这两个配置:
node.attr.rack: r1
node.attr.box_type: hot
热节点配置示例:
cluster.name: pancm
node.name: data1
path.data: /home/elk/datanode/data
path.logs: /home/elk/datanode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9300
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: false
node.data: true
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
node.attr.rack: r1
node.attr.box_type: hot
冷节点配置大体相同,就是后面的值进行更改
node.attr.rack: r9
node.attr.box_type: cool
冷节点配置示例:
cluster.name: pancm
node.name: data1
path.data: /home/elk/datanode/data
path.logs: /home/elk/datanode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9300
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: false
node.data: true
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
node.attr.rack: r1
node.attr.box_type: hot
在创建索引库的时候需要指定默认索引库的分片归属,如果没有指定,就会根据ElasticSearch默认进行均匀分布。这里我们将索引库默认创建到hot节点中,满足业务条件之后在使用命令或代码将该索引库设置到冷节点中。
索引示例:
PUT TEST_20190717
{
"index":"TEST_20190717",
"settings": {
"number_of_shards" :18,
"number_of_replicas" : 1,
"refresh_interval" : "10s",
"index.routing.allocation.require.box_type":"hot"
},
"mappings": {
"mt_task_hh": {
"properties": {
"accttype": {
"type": "byte"
},
....
}
}
根据业务要求,我们可以对索引库的数据进行迁移,使用dsl语句在kibana上执行或者使用java代码实现都可以。
dsl语句:
PUT TEST_20190717/_settings
{
"index.routing.allocation.require.box_type":"cool"
}
java代码实现:
public static void setCool(String index) throws IOException {
RestClient restClient = null;
try {
Objects.requireNonNull(index, "index is not null");
restClient = client.getLowLevelClient();
String source = "{\"index.routing.allocation.require.box_type\": \"%s\"}";
source = String.format(source, "cool");
HttpEntity entity = new NStringEntity(source, ContentType.APPLICATION_JSON);
restClient.performRequest("PUT", "/" + index + "/_settings", Collections.<String, String>emptyMap(), entity);
} catch (IOException e) {
throw e;
} finally {
if (restClient != null) {
restClient.close();
}
}
}
完整代码地址: https://github.com/xuwujing/java-study/tree/master/src/main/java/com/pancm/elasticsearch
其实这篇文章本应来说在2019年就完成了初稿,但是因为其他的事情一直耽搁,好在查看草稿是发现了,于是便补了。因为时隔太久,细节上相比之前的文章有一定的差距。不过好在是写出来了,以后的话写文章的话还是尽早,不然后面就忘了。目前ElasticSearch实战系列已经写了10篇了,虽然中间的间隔有点久,后面我会慢慢的更新这个系列,尽量把自己所学所感悟的写出来,如有写的不好,希望能够指出讨论。
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
掘金出处:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
个人博客出处:http://www.panchengming.com
ElasticSearch实战系列十: ElasticSearch冷热分离架构
标签:inf cluster net 分片 ica load attr public hosts
原文地址:https://www.cnblogs.com/xuwujing/p/14599290.html