标签:展示 pandas odi env 编号 font cluster error rgb
一、kmeans聚类
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import re pd.set_option(‘max_columns‘, 600) pd.set_option(‘max_rows‘, 500) from sklearn.manifold import TSNE from scipy.cluster.vq import vq, kmeans, whiten a = np.random.multivariate_normal([0, 0], [[4, 1], [1, 4]], size=10) b = np.random.multivariate_normal([30, 10], [[10, 2], [2, 1]], size=10) features=np.concatenate((a, b)) #白化处理 whitened = whiten(features) #k-means聚类 codebook, distortion = kmeans(whitened, 3)# 返回聚类中心点和每个类的平均误差 #返回每行数据聚类的编号及偏差 codes, error = vq(whitened, codebook) #将聚类结果形成dataframe df=pd.DataFrame(features) df[‘code‘]=codes #可视化展现聚类效果 d=df.loc[df.code==0,:] plt.plot(d[0],d[1],‘r.‘) d=df.loc[df.code==1,:] plt.plot(d[0],d[1],‘go‘) d=df.loc[df.code==2,:] plt.plot(d[0],d[1],‘b*‘) plt.show()
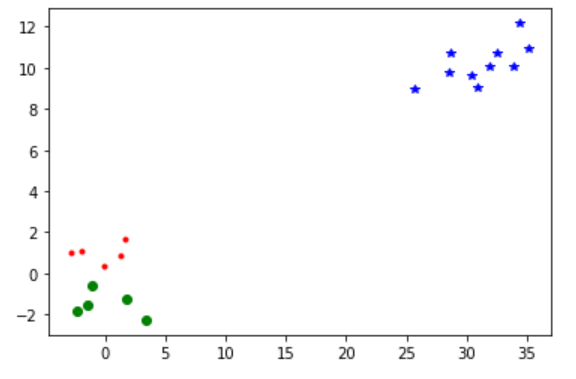
二、TNSE
TSNE提供了一种有效的降维方式,可以对高于2维数据的聚类结果以二维的方式展示出来。
#!/usr/bin/env python #-- coding:utf-8 -- #接kmeans.py #k_means.py中得到三维规范化数据data_zs; #r增加了最后一列,列索引为“聚类类别” from sklearn.manifold import TSNE tsne=TSNE() tsne.fit_transform(data_zs) #进行数据降维,降成两维 #a=tsne.fit_transform(data_zs) #a是一个array,a相当于下面的tsne_embedding tsne=pd.DataFrame(tsne.embedding_,index=data_zs.index) #转换数据格式 import matplotlib.pyplot as plt d=tsne[r[u‘聚类类别‘]==0] plt.plot(d[0],d[1],‘r.‘) d=tsne[r[u‘聚类类别‘]==1] plt.plot(d[0],d[1],‘go‘) d=tsne[r[u‘聚类类别‘]==2] plt.plot(d[0],d[1],‘b*‘) plt.show()
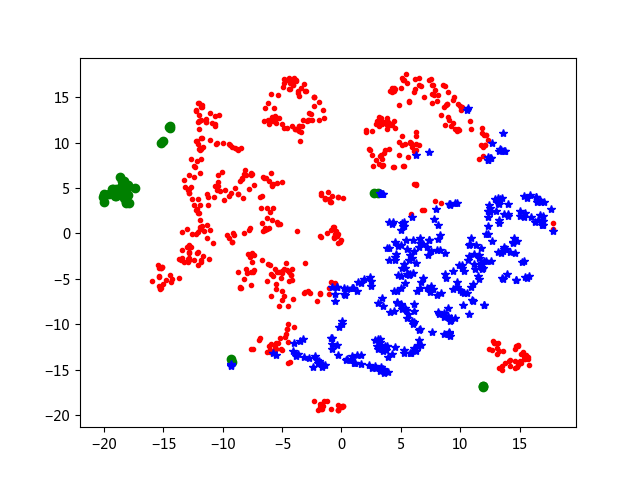
标签:展示 pandas odi env 编号 font cluster error rgb
原文地址:https://www.cnblogs.com/gczr/p/14613087.html