标签:aml develop 问题 股票 开发 适合 medium 常见 离线

更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流。
微软亚洲研究院发布了 AI 量化投资开源平台“微矿 Qlib”。Qlib 涵盖了量化投资的全过程,为用户的 AI 算法提供了高性能的底层基础架构,从框架设计上让用户可以更容易地应用 AI 算法来辅助解决量化投资的各个关键问题,比如 Alpha 因子构建、风险预测、市场动态性建模等等。

Qlib 覆盖了量化投资的全过程,从底层构造开始就专为 AI 而生,从数据处理到计算力支撑,再到模型的训练与验证,都为基于 AI 的量化投资提供了全方位的框架支持。用户可以通过 Qlib 平台提供的多个工具模块,更加轻松地管理和使用自己的算法,特别是其 AI 算法。Qlib 的架构如下图所示:
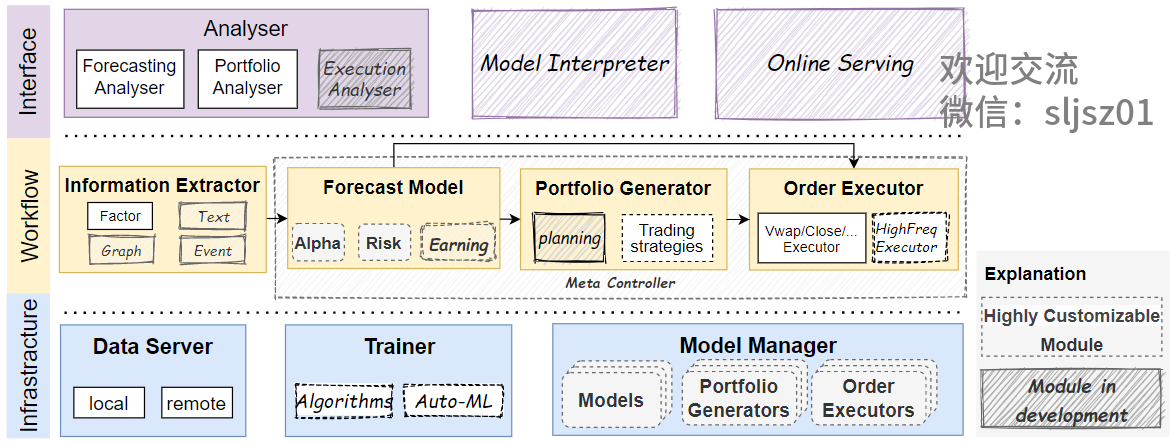
最底层的是基础架构层(Infrastructure)。Qlib 的数据服务模块(Data Server)提供了高性能的数据存储设计,让 AI 算法可以更快地处理更多金融数据。训练模块(Trainer)则为 AI 算法提供了灵活的接口来定义训练模型的过程,让 Auto-ML 等算法成为可能,也为分布式训练提供了接口。而模型管理模块(Model Manager)可以让用户更好地管理繁多的 AI 模型,更快地迭代其 AI 算法。
中间层是量化投资流程(Workflow)。信息抽取模块(Information Extractor)负责从异构数据中提取有效的信息,因为用 AI 进行投资分析数据是关键,尽管金融行业有一定的数据基础,但 AI 模型可以直接使用的高质量数据仍然十分有限,所以这就需要更多精细化处理和信息抽取。之后,预测模型(Forecast Model)会输入抽取的信息,输出可供金融专家参考的未来收益、风险等等预测,然而预测模型需要依靠底层海量数据才能训练出精准、有效的预测模型。而投资组合生成模块(Portfolio Generator)则能根据预测得到 Alpha 信号和风险信号辅助生成投资策略组合。订单执行模块(Order Executor)是投资的最后一步——交易执行,帮助用户判断何时下单也是一门艺术。在量化投资中,几乎不可能有一个模型在全时段都一直保持卓越的表现,所以对市场动态性建模,以及在不同时期适时地调整模型、策略、执行也是一个非常重要的课题。Qlib 中元控制器模块 (Meta Controller) 的设计正是要支持这类问题的研究,实时提供精准的参考信息和方案,辅助用户进行操作。
最上层是交互层(Interface)。其中,分析模块(Analyzer)会根据下层的预测信号、仓位、执行结果做出详细的分析并呈现给用户。
特别的,Qlib内置了时序量价数据、业内常用因子、以及 常见的金融 AI 模型(例如 LightGBM、GRU、GATs 等十几个模型) , 大大降低了 AI 使用的专业门槛 。Qlib内置数据集和模型分类如下。

QLib的测试数据支持在线、离线两种模式,QLib默认的是启用离线模式,该模式下,所有的回测数据的存储与读取都将在本地进行,而在线模式的数据将会部署在微软的服务器端。我们更推荐大家使用离线模式来进行策略研发,第一是策略数据一次落地即可使用,无需反复传输,无网络时同样可以测试;第二是策略代码完全在本地运行,保证了策略的安全性。
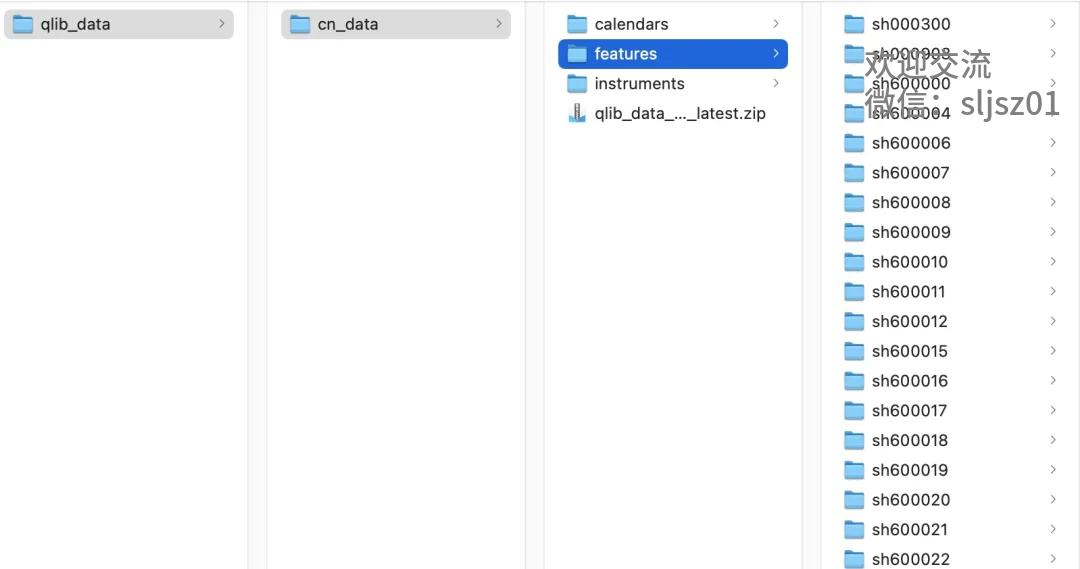
我们以离线模式为例,为大家展示QLib的数据准备过程。QLib包中提供了从雅虎财经获取金融数据的脚本,只需要在控制台调用对应的Python脚本,制定数据的存储路径,就能将数据下载到本地了。
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
我们将代码存储在家目录下的qlib_data文件夹内,完成下载后,我们查看对应目录,找到对应的数据位置。
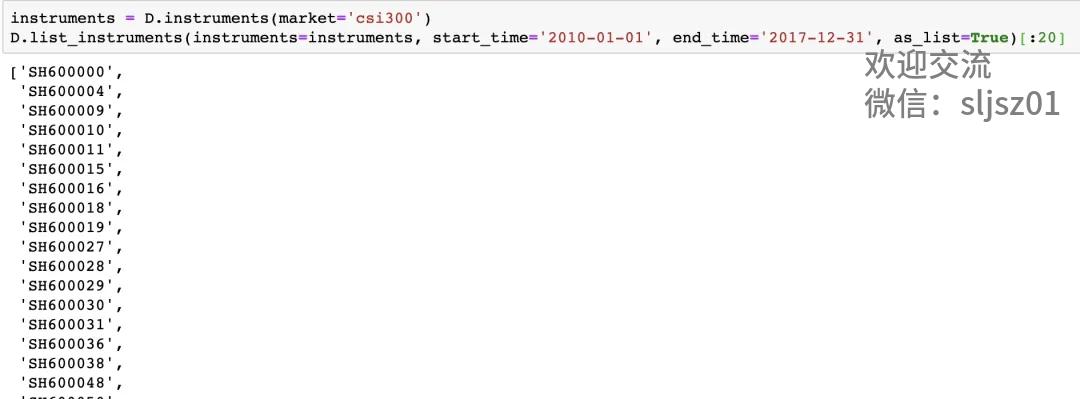
下一步,我们调用QLib库中的相关方法,尝试读取我们刚才下载到本地的数据,并尝试读取CIS300指数的成分股。
import qlib
from qlib.data import D
qlib.init(provider_uri=‘~/.qlib/qlib_data/cn_data‘)
instruments = D.instruments(market=‘csi300‘)
D.list_instruments(instruments=instruments, start_time=‘2010-01-01‘, end_time=‘2017-12-31‘, as_list=True)[:20]
在数据落地到本地,并且成功使用QLib库读取到本地数据之后,我们再来看QLib中最重要的一个配置文件,该配置文件叫做workflow。workflow中需要配置数据集地址、策略回测参数、训练模型参数、模型存储地址等,在整个测试过程中的关键配置。我们来看QLib一个完整的workflow配置示例。该示例包含两部分代码,我们分别展示,首先是qlib_init部分。
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
data_handler_config: &data_handler_config
start_time: 2008-01-01
end_time: 2020-08-01
fit_start_time: 2008-01-01
fit_end_time: 2014-12-31
instruments: *market
port_analysis_config: &port_analysis_config
strategy:
class: TopkDropoutStrategy
module_path: qlib.contrib.strategy.strategy
kwargs:
topk: 50
n_drop: 5
backtest:
verbose: False
limit_threshold: 0.095
account: 100000000
benchmark: *benchmark
deal_price: close
open_cost: 0.0005
close_cost: 0.0015
min_cost: 5
qlib_init部分的关键配置参数包括:回测数据存储路径(provider_uri),即我们刚才下载数据的路径;market:股票池的选股范围是csi300;benchmark:策略比较基准是沪深300指数;start_time、end_time代表策略测试的起始、终止时间,而fit_start_time、fit_end_time代表训练样本的起始、终止时间;strategy:策略的选股规则,我们采用TopkDropoutStrategy,即选中topk的股票,并去掉n_drop数量;backtest是历史回测的参数,包括策略阈值、初始资金、成交价格、手续费等的设置。然后,我们来看第二部分,task部分的配置代码。
task:
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.0421
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
kwargs: {}
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config: *port_analysis_config
task部分,包含三个小类别的配置,分别是model(模型相关)、dataset(训练测试集相关)、record(模型存储相关)。在model的配置中,这里我们采用了lgb的模型,并在后续制定了关键的模型参数,比如误差衡量指标、学习率等等;而在dataset的配置中,我们采用了系统内置的Alpha158常用因子,并且将整体数据按时间分成了训练集、验证集和测试集三部分;最后一个record的配置,主要记录了训练过程、训练模型的存储路径,方便后续策略构建完毕的展示与评估。
我们只需要将qlib_init、task两部分代码合并保存到同一个文件下,文件后缀.yaml,例如我们将配置文件保存为test.yaml,再使用QLib库中的qrun函数调用.yaml的配置文件,即可完成整个策略运行过程了。
qrun test.yaml
最后,我们为大家运行一个QLib官方提供的示例策略,向大家展示策略运行的完整过程。我们找到示例策略目录examples下,选择lightGBM模型构建的示例策略,并找到该示例策略的workflow,也就是我们在上一小节提到的.yaml文件。
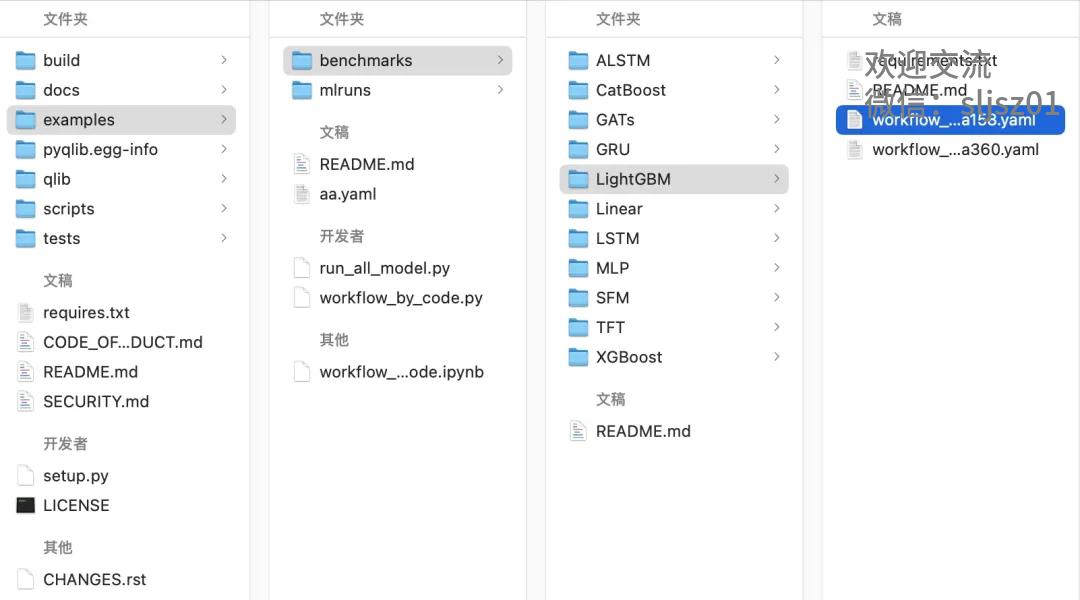
同样的,对于配置好的workflow,采用qrun + workflow,一句话启动策略运算。
qrun /examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
运行完成后,策略的关键结果会被记录在workflow指定的存储目录中, 更多的过程信息会被写入主目录下的workflow_by_code.ipynb 中,我们可以用Jupyter运行该文件,查看更丰富的策略报告。
仔细阅读一下workflow_by_code中的代码,可以看到模型建立、执行、预测等全部数据都已经存储完毕,我们只需要按顺序运行代码,即可查看策略的可视化结果。包括策略的回测曲线、分组收益率、每期IC系数、IC月度均值及分布等等。
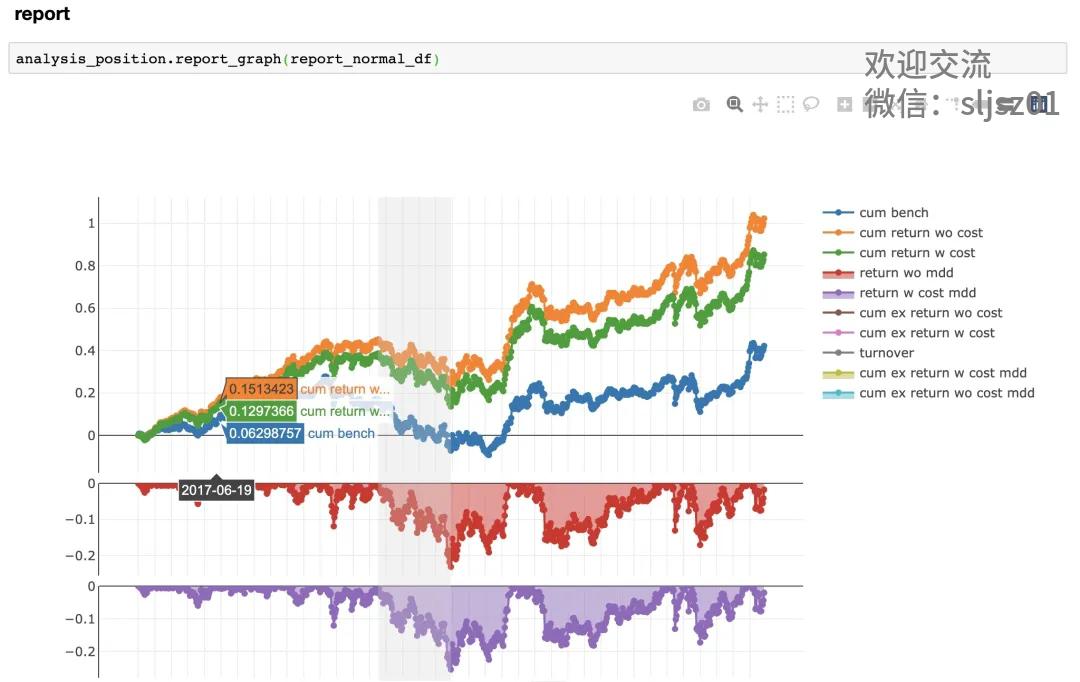
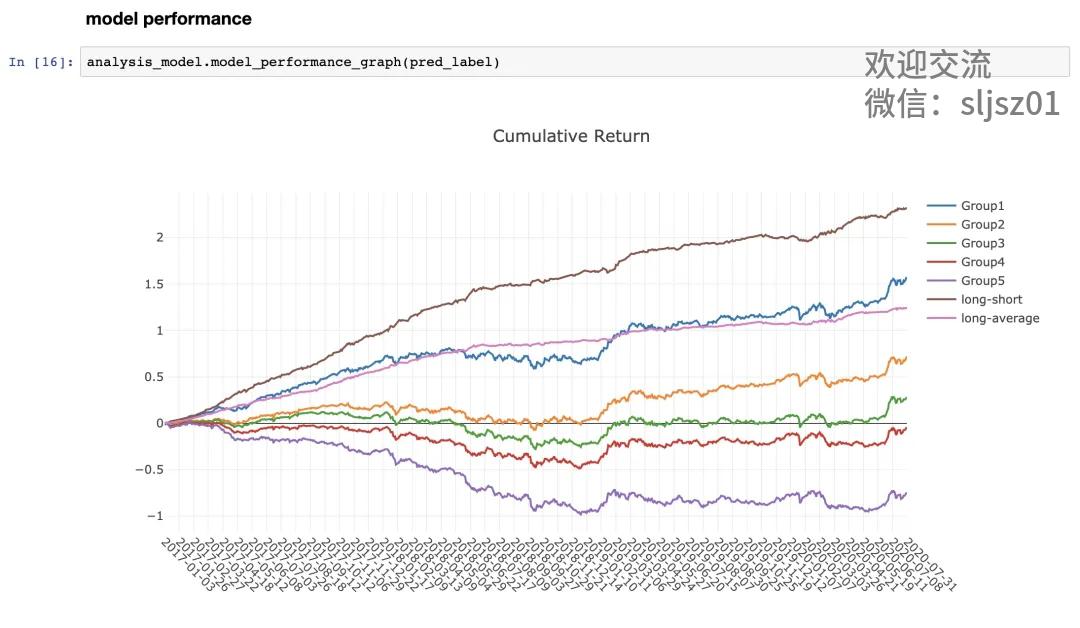
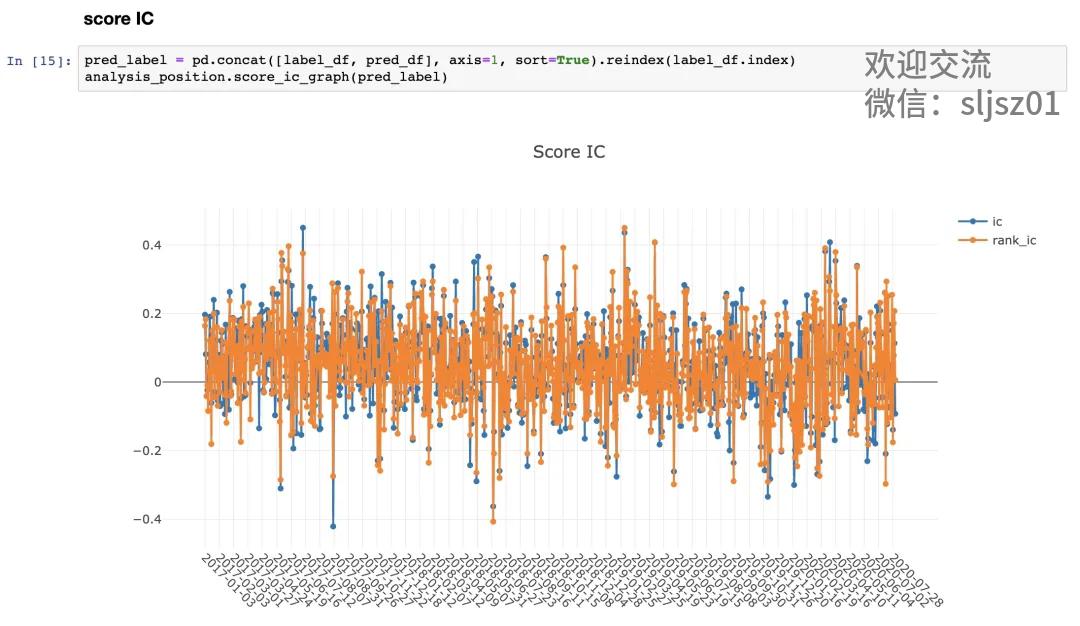
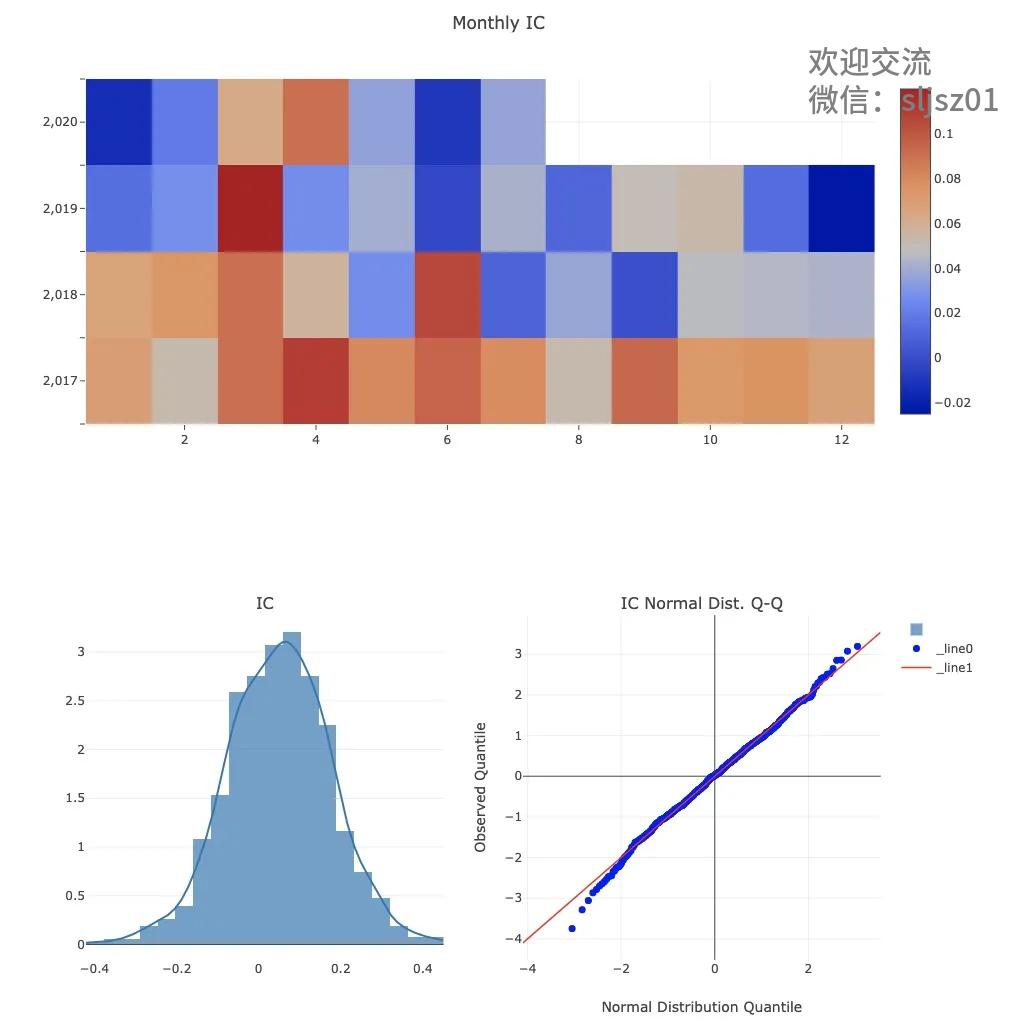
当然,QLib的功能强大,能玩的策略、数据、输出,远远不止我们上述举例的这些,如果大家对于AI量化投资感兴趣,可以尝试用QLib做轮子,创造自己的AI策略。
想要获取本次分享的完整代码,或是任何关于数据分析、量化投资的问题,欢迎添加技术宅微信:sljsz01,与我交流


Omega System Trading and Development Club内部分享策略Easylanguage源码
【数量技术宅|量化投资策略系列分享】基于指数移动平均的股指期货交易策略
AMA指标原作者Perry Kaufman 100+套交易策略源码分享
【数量技术宅|金融数据系列分享】套利策略的价差序列计算,恐怕没有你想的那么简单
【数量技术宅|量化投资策略系列分享】成熟交易者期货持仓跟随策略
【数量技术宅|金融数据分析系列分享】为什么中证500(IC)是最适合长期做多的指数
商品现货数据不好拿?商品季节性难跟踪?一键解决没烦恼的Python爬虫分享
【数量技术宅|金融数据分析系列分享】如何正确抄底商品期货、大宗商品
【数量技术宅|量化投资策略系列分享】股指期货IF分钟波动率统计策略
【数量技术宅 | Python爬虫系列分享】实时监控股市重大公告的Python爬虫
标签:aml develop 问题 股票 开发 适合 medium 常见 离线
原文地址:https://www.cnblogs.com/sljsz/p/14629526.html