标签:head max ram 参考 人工智能 策略 建模 char 数学函数
该算法旨在在一组数据点中,用基因表达式编程的方法,根据基因遗传定律,物竞天择、优者生存,劣者淘汰的思想,不断进化种群,找出适宜度最高的染色体来模拟出数据点之间所存在的数学表达式关系。通常该算法用来解决符号回归问题:符号回归(Symbolic Regression)作为一种一种监督学习方法,试图发现某种隐藏的数学公式,以此利用特征变量预测目标变量。符号回归的优点就是可以不用依赖先验的知识或者模型来为非线性系统建立符号模型。符号回归基于进化算法,它的主要目标就是利用进化方法综合出尽可能好的解决用户自定义问题的方法(数学公式,计算机程序,逻辑表达式等)。
一段基因由两部分组成:头部和尾部,形如:

其中,红色部分为头部基因,其长度为9,绿色部分为尾部基因,其长度为8。
基因中的每个元素分为两种形式:函数和终点,它们分别从函数集和终点集中进行选择:
基因头部长度我们用h表示,尾部长度用t表示,函数集所需最大参数用n表示,比如一个函数集为{+、-、*、/、sin、cos},其中所需参数的最大个数为2,则n为2
那么h、t、n三者之间的关系是:\(t=h*(n-1)+1\)
维持这样的关系,可以保证产生的基因编码都是合法编码。
比如下方的数学表达式:
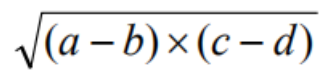
翻译成表达式树为,其中Q表示开方:
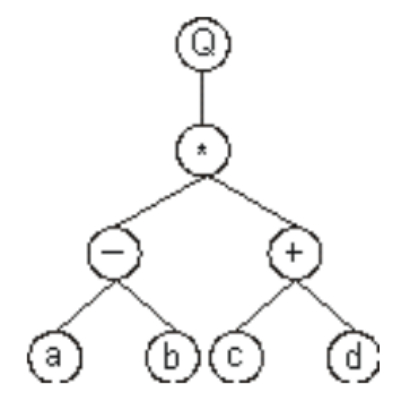
那么可以得到它的基因型为:

下面来看看一个基因型翻译成表达式的过程:
基因型如下:
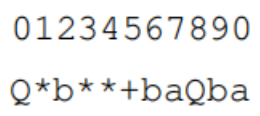
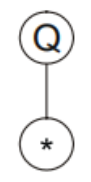
基因的起点对应表达式树的根:

Q(开方)需要一个参数,那么往后取一个参数:
乘法需要两个参数,往后取两个参数:
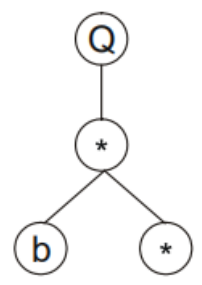
以此类推,可以画出该基因型的表达式树为:
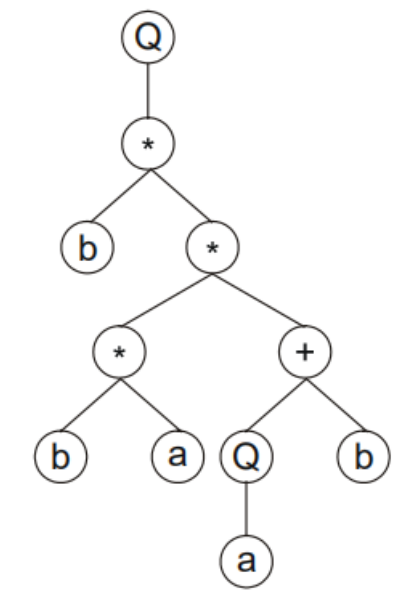
我们可以看出,表达式树的根一定要是函数集的元素,叶子节点一定是终点集的元素。
一条染色体可以由多个基因构成,那么我们需要设定基因连接符,比如用+、-、 *、/等符号进行连接,比如:
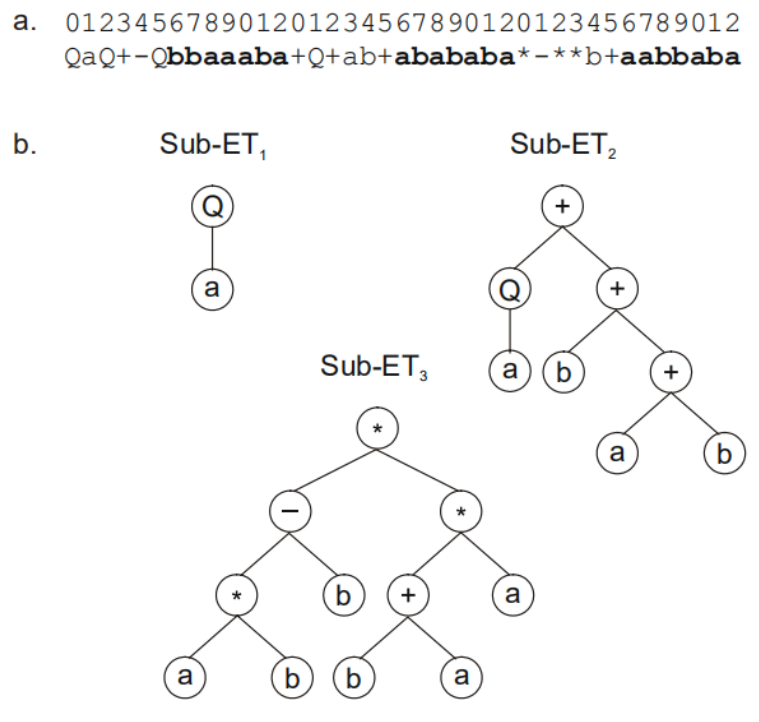
这三个子树我们可以通过+进行连接:
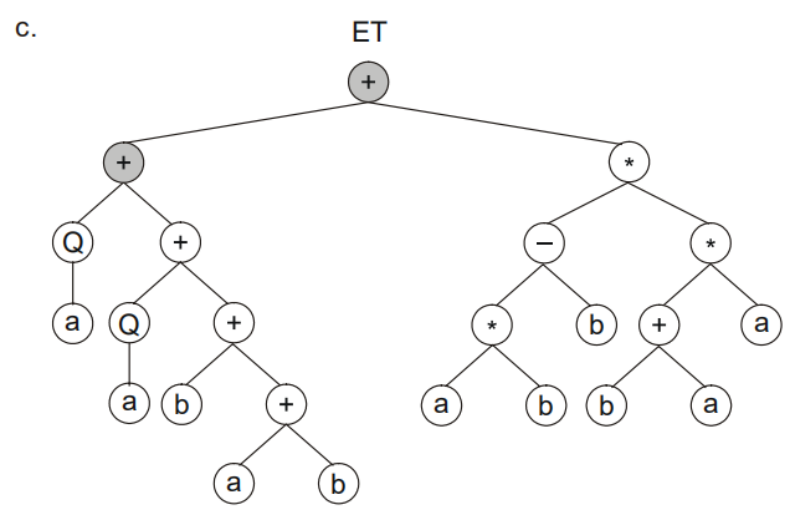
其次一条染色体代表一个个体,那么一个种群就可以有多个染色体。
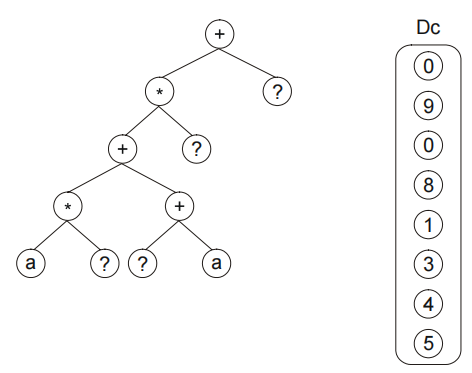
在符号回归问题种,我们使用这样的结构来操纵随机数值常量。例如,如下的染色体:

含有一个附加域 Dc,这个附加域用来对随机数值常量进行编码。该染色体的翻译过程如下图所示:
基因的进化分为以下几种:
下面我们对进化操作分别进行讲解:
变异的原则:
void Gene::mutation() {
int index = rand() % gene_len;
char ch;
if (index <= HEAD_LEN)
ch = getRandomElem();
else
ch = getTermElem();
text[index] = ch;
}
IS转座是从种群中随机选择一个染色体,然后随机从IS转座长度中选择IS长度,然后在染色体中选择IS长度的基因片段,并随机选择基因,插入到除基因首元素之外的头部部分中,如下所示:

void Individual::transposition_is() {
// 随机选取转座长度
int len_array = sizeof(IS_LEN) / sizeof(int);
int index = rand() % len_array;
int len_is = IS_LEN[index];
// 从整段染色体中随机选取len_is个长度的片段
index = rand() % (len - len_is); // 随机起始索引
string str = content_without_space().substr(index, len_is); // 截取字符串
// 随机选择基因
index = index_rand(); gene[index].transposition(str);
}
所有的RIS元素都是从一个函数开始,因此是选自头部分中的序列。因此在头中任选一点,沿基因向后查找,直到发现一个函数为止。该函数成为RIS元素的起始位置。如果找不到任何函数,则变换不执行任何操作。该算子随机选取染色体,需要修饰的基因,RIS元素以及其长度。变化过程如图所示:

void Individual::transposition_ris() {
// 随机选择基因
int index = index_rand();
// 在头中随机选取一点
int pos = rand() % HEAD_LEN;
// 沿该点向后查找直到发现一个函数 该点即为RIS转座的起始点
int a;
if ((a = gene[index].find_func(pos)) == -1)
return;
pos = a + Gene::length() * index;
// 随机选取RIS转座长度
int len_array = sizeof(RIS_LEN) / sizeof(int);
index = rand() % len_array; int len_ris = RIS_LEN[index];
// 从起始点向后取len_ris个长度的片段 string str = content_without_space().substr(pos, len_ris);
index = index_rand(); gene[index].transposition(str);
}
基因转座仅仅改变基因在同一染色体中的位置,如图所示:

void Individual::transposition_gene() {
// 随机选取两个不同位置的基因
if (GENE_NUM > 1) {
int index1 = 0;
int index2 = 0;
while (index1 == index2) {
index1 = index_rand();
index2 = index_rand();
}
Gene temp(gene[index1]);
gene[index1] = gene[index2];
gene[index2] = temp;
}
}
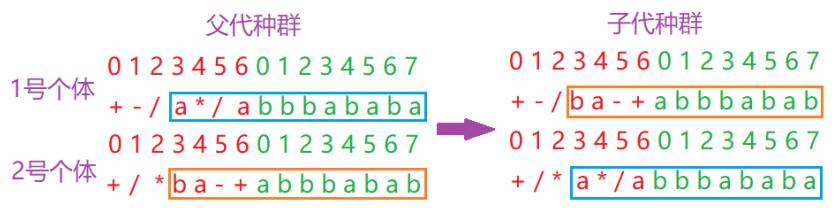
进行单点重组的时候,父代染色体相互配对并在相同的位置切断,两个染色体相互交换重组点之后的部分,如图所示:
void Population::recombination_one() {
double prob = rand() / double(RAND_MAX);
if (prob < PROB_RECOMBE_ONE) {
// 随机选取两个不同个体
int index1 = 0;
int index2 = 0;
while (index1 == index2) {
index1 = rand() % count;
index2 = rand() % count; }
// 随机选取重组点
int pos = rand() % Individual::length();
string subStr1 = individual[index1].content_without_space().substr(0, pos);
string subStr2 = individual[index2].content_without_space().substr(0, pos);
// 交换两个染色体的片段 individual[index1].recombination(0, pos, subStr2);
individual[index2].recombination(0, pos, subStr1);
}
}
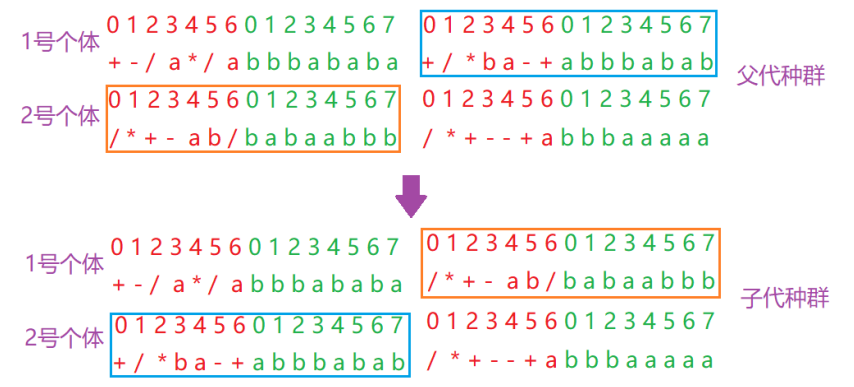
进行两点重组的时候,父代染色体相互配对,在染色体中随机选择两个点,将染色体切断。两个染色体相互交换重组点之间的部分,形成两个新的子代染色体。如图所示:

void Population::recombination_two() {
double prob = rand() / double(RAND_MAX);
if (prob < PROB_RECOMBE_TWO) {
// 随机选取两个不同个体
int index1 = 0;
int index2 = 0;
while (index1 == index2) {
index1 = rand() % count;
index2 = rand() % count;
}
// 随机选取左、右重组点
int pos_left = rand() % Individual::length();
int pos_right = (rand() % (Individual::length() - pos_left)) + pos_left;
int len = pos_right - pos_left + 1; // 重组点之间的距离
// 重组点之间的字符串,包括左、右重组点
string subStr1 = individual[index1].content_without_space().substr(pos_left, len);
string subStr2 = individual[index2].content_without_space().substr(pos_left, len);
// 交换两个染色体的片段
individual[index1].recombination(pos_left, len, subStr2);
individual[index2].recombination(pos_left, len, subStr1);
}
}
在 GEP 的第三种重组中,两个染色体中的整个基因相互交换,形成的两个子代染色体含有来自两个父体的基因。
void Population::recombination_gene() {
double prob = rand() / double(RAND_MAX);
if (prob < PROB_RECOMBE_GENE) {
// 随机选取两个不同个体 int index1 = 0;
int index2 = 0; while (index1 == index2) {
index1 = rand() % count; index2 = rand() % count;
}
// 随机选取基因索引
int index = rand() % GENE_NUM;
// 获取两个个体相应索引的基因
string subStr1 = individual[index1].content_without_space().substr(index * Gene::length(), Gene::length());
string subStr2 = individual[index2].content_without_space().substr(index * Gene::length(), Gene::length());
// 交换
individual[index1].recombination(index * Gene::length(), Gene::length(), subStr2);
individual[index2].recombination(index * Gene::length(), Gene::length(), subStr1);
}
}
个体程序 的适应度 可以用第一个方程来表示,当误差类型选为相对误差的时候,个体程序的适应度 可以用方程(3.1b)来表示:
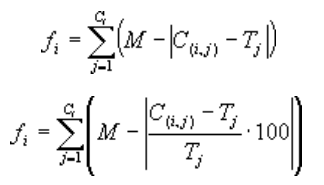
其中\(M\)是选择范围,\(C_{(i,j)}\)是染色体个体\(i\)对于适应度样本\(j\)(来自\(C_t\)集合中)的返回值。而\(T_j\)是适应度样本\(j\)的目标值。请注意,两个方程中的绝对值项都对应各自的误差(前一个方程中对应于绝对误差,后一个方程中对应于相对误差)。该项称为精度\(p\)。因此,对于一个完美适应的情况, 且 \(C_{(i, j)}=C_t\)且\(f_i=f_{max}=C_tM\)。
在 GEP 中,个体通过赌盘轮采样策略根据其适应度进行选择。每个个体用圆形赌盘的一块来代表其适应度的比例。赌盘按照群体中个体数的值进行相应次数的旋转,从而始终保持群体的大小不变。
采用这种选择策略,确实有时候会丢失一些最佳个体,而一些普通个体进入到了下一代。但是这样也不一定就不好,因为种群会一代一代地向前推进。而且,因为我们使用每一代中的最佳个体复制策略,所以最佳个体的存在和复制能够得到保证。这样,至少最优的特性从来没有丢失过,并且能够达到不断学习的目的。
还有几种其他最常用的选择算法——赌盘选择、确定性选择、锦标赛选择。
| 参数名称 | 参数值 |
|---|---|
| 函数集 | {+、-、*、/} |
| 终点集 | a |
| 头部长度 | 7 |
| 是否开启Dc域 | True |
| Dc域最大值 | 10.0 |
| Dc域最小值 | 0.0 |
| Dc域元素个数 | 10 |
| 基因数目 | 4 |
| 基因连接符 | + |
| 种群大小 | 20 |
| 繁衍代数 | 1000 |
| 变异概率 | 0.043 |
| IS转座概率 | 0.1 |
| RIS转座概率 | 0.1 |
| IS元素长度 | 3 |
| RIS元素长度 | 3 |
| 基因转座概率 | 0.1 |
| 单点重组概率 | 0.8 |
| 两点重组概率 | 0.8 |
| 基因重组概率 | 0.8 |
| 是否选用绝对误差 | True |
| 选择范围 | 1000.0 |
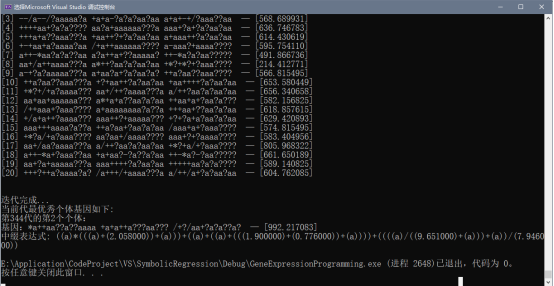 经过化简,得到其数学表达式为:
经过化简,得到其数学表达式为:
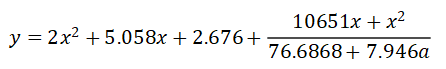 其图像如下所示,其中橙色曲线为函数轨迹,红色点为数据点
其图像如下所示,其中橙色曲线为函数轨迹,红色点为数据点
《基因表达式编程 —— 用一种人工智能方法进行数学建模》
基因表达式编程(Gene Expression Programming,GEP)
标签:head max ram 参考 人工智能 策略 建模 char 数学函数
原文地址:https://www.cnblogs.com/ain1/p/14617697.html