标签:amp always ssi nat uid comm efault 选择 滤镜
Manager提供的根QuerySet描述了数据库表中的所有对象。不过,通常,您只需要选择完整对象集的一个子集即可。
— Django文档
REST框架的通用列表视图的默认行为是返回模型管理器的整个查询集。通常,您会希望您的API限制查询集返回的项目。
筛选子类的任何视图的查询集的最简单方法GenericAPIView是覆盖该.get_queryset()方法。
通过覆盖此方法,您可以通过多种不同方式自定义视图返回的查询集。
您可能希望过滤查询集,以确保仅返回与发出请求的当前经过身份验证的用户相关的结果。
您可以根据的值进行过滤request.user。
例如:
from myapp.models import Purchase
from myapp.serializers import PurchaseSerializer
from rest_framework import generics
class PurchaseList(generics.ListAPIView):
serializer_class = PurchaseSerializer
def get_queryset(self):
"""
This view should return a list of all the purchases
for the currently authenticated user.
"""
user = self.request.user
return Purchase.objects.filter(purchaser=user)另一种过滤方式可能涉及基于URL的某些部分限制查询集。
例如,如果您的URL配置包含这样的条目:
re_path(‘^purchases/(?P<username>.+)/$‘, PurchaseList.as_view()),然后,您可以编写一个视图,该视图返回按URL的用户名部分过滤的购买查询集:
class PurchaseList(generics.ListAPIView):
serializer_class = PurchaseSerializer
def get_queryset(self):
"""
This view should return a list of all the purchases for
the user as determined by the username portion of the URL.
"""
username = self.kwargs[‘username‘]
return Purchase.objects.filter(purchaser__username=username)过滤初始查询集的最后一个示例是根据url中的查询参数确定初始查询集。
我们可以重写.get_queryset()以处理诸如的URL http://example.com/api/purchases?username=denvercoder9,仅username在URL中包含参数时才过滤查询集:
class PurchaseList(generics.ListAPIView):
serializer_class = PurchaseSerializer
def get_queryset(self):
"""
Optionally restricts the returned purchases to a given user,
by filtering against a `username` query parameter in the URL.
"""
queryset = Purchase.objects.all()
username = self.request.query_params.get(‘username‘)
if username is not None:
queryset = queryset.filter(purchaser__username=username)
return querysetREST框架不仅可以覆盖默认查询集,还包括对通用过滤后端的支??持,使您可以轻松构建复杂的搜索和过滤器。
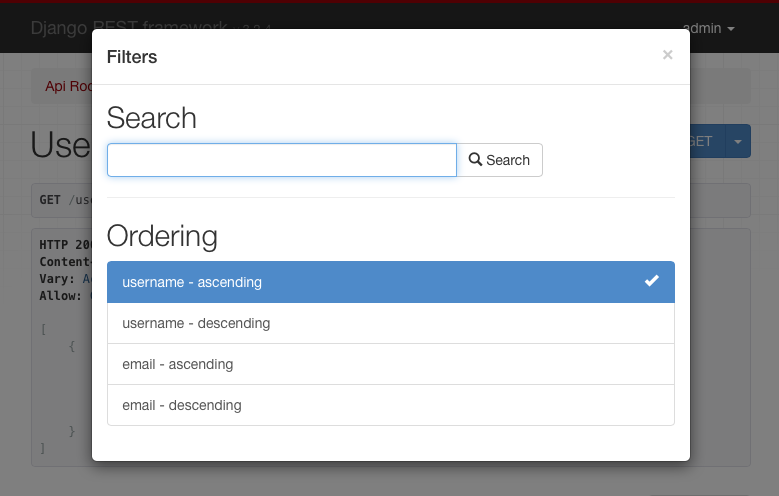
通用过滤器还可以将自己显示为可浏览API和admin API中的HTML控件。
可以使用该DEFAULT_FILTER_BACKENDS设置全局设置默认过滤器后端。例如。
REST_FRAMEWORK = {
‘DEFAULT_FILTER_BACKENDS‘: [‘django_filters.rest_framework.DjangoFilterBackend‘]
}您还可以使用GenericAPIView基于类的视图基于每个视图或每个视图集设置过滤器后端。
import django_filters.rest_framework
from django.contrib.auth.models import User
from myapp.serializers import UserSerializer
from rest_framework import generics
class UserListView(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
filter_backends = [django_filters.rest_framework.DjangoFilterBackend]请注意,如果为视图配置了过滤器后端,则该过滤器后端不仅用于过滤列表视图,还将用于过滤用于返回单个对象的查询集。
例如,给定前面的示例以及id为的产品4675,以下URL将返回相应的对象或返回404响应,具体取决于给定产品实例是否满足过滤条件:
http://example.com/api/products/4675/?category=clothing&max_price=10.00请注意,您可以同时使用覆盖.get_queryset()过滤和通用过滤,一切都会按预期进行。例如,如果Product与User名为的多对多关系purchase,则可能需要编写如下视图:
class PurchasedProductsList(generics.ListAPIView):
"""
Return a list of all the products that the authenticated
user has ever purchased, with optional filtering.
"""
model = Product
serializer_class = ProductSerializer
filterset_class = ProductFilter
def get_queryset(self):
user = self.request.user
return user.purchase_set.all()该django-filter库包含一个DjangoFilterBackend类,该类支持针对REST框架的高度可自定义的字段筛选。
要使用DjangoFilterBackend,请先安装django-filter。
pip install django-filter然后添加‘django_filters‘到Django的INSTALLED_APPS:
INSTALLED_APPS = [
...
‘django_filters‘,
...
]现在,您应该将过滤器后端添加到您的设置中:
REST_FRAMEWORK = {
‘DEFAULT_FILTER_BACKENDS‘: [‘django_filters.rest_framework.DjangoFilterBackend‘]
}或将过滤器后端添加到单个View或ViewSet。
from django_filters.rest_framework import DjangoFilterBackend
class UserListView(generics.ListAPIView):
...
filter_backends = [DjangoFilterBackend]如果只需要简单的基于等式的过滤,则可以filterset_fields在视图或视图集上设置一个属性,列出要过滤的字段集。
class ProductList(generics.ListAPIView):
queryset = Product.objects.all()
serializer_class = ProductSerializer
filter_backends = [DjangoFilterBackend]
filterset_fields = [‘category‘, ‘in_stock‘]这将自动FilterSet为给定的字段创建一个类,并允许您发出如下请求:
http://example.com/api/products?category=clothing&in_stock=True对于更高级的过滤要求,您可以指定FilterSet视图应使用的类。您可以FilterSet在django-filter文档中阅读有关的更多信息。还建议您阅读有关DRF集成的部分。
该SearchFilter级支持简单单的查询参数基于搜索和基于该admin界面的搜索功能。
使用时,可浏览的API将包含一个SearchFilter控件:

所述SearchFilter如果视图有一类将只应用于search_fields属性集。该search_fields属性应该是模型上文本类型字段名称的列表,例如CharField或TextField。
from rest_framework import filters
class UserListView(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
filter_backends = [filters.SearchFilter]
search_fields = [‘username‘, ‘email‘]这将允许客户端通过执行以下查询来过滤列表中的项目:
http://example.com/api/users?search=russell您还可以使用查找API双下划线表示法在ForeignKey或ManyToManyField上执行相关查找:
search_fields = [‘username‘, ‘email‘, ‘profile__profession‘]对于JSONField和HStoreField字段,您可以使用相同的双下划线符号根据数据结构内的嵌套值进行过滤:
search_fields = [‘data__breed‘, ‘data__owner__other_pets__0__name‘]默认情况下,搜索将使用不区分大小写的部分匹配。搜索参数可以包含多个搜索词,应将其用空格和/或逗号分隔。如果使用了多个搜索词,则仅当所有提供的词都匹配时,对象才会在列表中返回。
可以通过在字符前面添加各种字符来限制搜索行为search_fields。
例如:
search_fields = [‘=username‘, ‘=email‘]默认情况下,搜索参数名为‘search‘,但是此参数可能会被SEARCH_PARAM设置覆盖。
要根据请求内容动态更改搜索字段,可以对进行子类化SearchFilter并覆盖该get_search_fields()函数。例如,以下子类仅title在查询参数title_only在请求中时才搜索:
from rest_framework import filters
class CustomSearchFilter(filters.SearchFilter):
def get_search_fields(self, view, request):
if request.query_params.get(‘title_only‘):
return [‘title‘]
return super(CustomSearchFilter, self).get_search_fields(view, request)有关更多详细信息,请参见Django文档。
本OrderingFilter类支持的结果简单的查询参数进行控制顺序。

默认情况下,查询参数名为‘ordering‘,但这可以被ORDERING_PARAM设置覆盖。
例如,按用户名订购用户:
http://example.com/api/users?ordering=username客户端还可以通过在字段名称前添加“-”来指定相反的顺序,如下所示:
http://example.com/api/users?ordering=-username也可以指定多个顺序:
http://example.com/api/users?ordering=account,username建议您明确指定API应在排序过滤器中允许的字段。您可以通过ordering_fields在视图上设置属性来做到这一点,如下所示:
class UserListView(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
filter_backends = [filters.OrderingFilter]
ordering_fields = [‘username‘, ‘email‘]这有助于防止意外的数据泄漏,例如允许用户针对密码哈希字段或其他敏感数据进行排序。
如果未ordering_fields在视图上指定属性,则过滤器类将默认为允许用户对由serializer_class属性指定的序列化器上的任何可读字段进行过滤。
如果您确信该视图使用的查询集不包含任何敏感数据,则还可以通过使用special值明确指定一个视图应允许对任何模型字段或查询集集合进行排序‘__all__‘。
class BookingsListView(generics.ListAPIView):
queryset = Booking.objects.all()
serializer_class = BookingSerializer
filter_backends = [filters.OrderingFilter]
ordering_fields = ‘__all__‘如果ordering在视图上设置了属性,则将其用作默认顺序。
通常,您可以通过order_by在初始查询集上进行设置来控制此操作,但是使用ordering视图上的参数可以指定顺序,然后将其作为上下文自动传递到呈现的模板。如果使用列标题对结果进行排序,则可以自动呈现不同的列标题。
class UserListView(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
filter_backends = [filters.OrderingFilter]
ordering_fields = [‘username‘, ‘email‘]
ordering = [‘username‘]该ordering属性可以是字符串,也可以是字符串列表/元组。
您还可以提供自己的通用过滤后端,或编写供其他开发人员使用的可安装应用。
为此,请重写BaseFilterBackend,并重写该.filter_queryset(self, request, queryset, view)方法。该方法应返回一个经过过滤的新查询集。
除了允许客户端执行搜索和过滤外,通用过滤器后端对于限制任何给定请求或用户应看到哪些对象也很有用。
例如,您可能需要限制用户只能看到他们创建的对象。
class IsOwnerFilterBackend(filters.BaseFilterBackend):
"""
Filter that only allows users to see their own objects.
"""
def filter_queryset(self, request, queryset, view):
return queryset.filter(owner=request.user)我们可以通过覆盖get_queryset()视图来实现相同的行为,但是使用过滤器后端可以使您更轻松地将此限制添加到多个视图,或将其应用于整个API。
通用过滤器也可以在可浏览的API中提供一个接口。为此,您应该实现一个to_html()方法,该方法返回过滤器的呈现的HTML表示形式。此方法应具有以下签名:
to_html(self, request, queryset, view)
该方法应返回呈现的HTML字符串。
您还可以通过实现一种get_schema_fields()方法,使过滤器控件可用于REST框架提供的模式自动生成。此方法应具有以下签名:
get_schema_fields(self, view)
该方法应返回coreapi.Field实例列表。
以下第三方软件包提供了其他过滤器实现。
在Django的休息框架过滤器封装与一起工作DjangoFilterBackend类,并允许您轻松地在关系创建过滤器,或在指定字段创建多个过滤器查找类型。
该djangorestframework词过滤开发作为替代品filters.SearchFilter,这将搜索文本完整的单词,或精确匹配。
django-url-filter提供了一种通过人类友好的URL过滤数据的安全方法。从某种意义上说,它可以嵌套,但它们被称为过滤器集和过滤器,在某种意义上来说,它的工作方式与DRF序列化器和字段非常相似。这提供了过滤相关数据的简便方法。该库也是通用的,因此可以用来过滤其他数据源,而不仅仅是Django QuerySet。
DRF-URL过滤是一个简单的Django应用程序对DRF应用滤镜ModelViewSet的Queryset一个清洁,简单和可配置的方式。它还支持对传入查询参数及其值的验证。一个漂亮的python包Voluptuous用于对传入的查询参数进行验证。关于性感的最好的部分是您可以根据查询参数要求定义自己的验证。
class SearchFilter(BaseFilterBackend): # The URL query parameter used for the search. search_param = api_settings.SEARCH_PARAM template = ‘rest_framework/filters/search.html‘ lookup_prefixes = { ‘^‘: ‘istartswith‘, ‘=‘: ‘iexact‘, ‘@‘: ‘search‘, ‘$‘: ‘iregex‘, } search_title = _(‘Search‘) search_description = _(‘A search term.‘) def get_search_fields(self, view, request): """ Search fields are obtained from the view, but the request is always passed to this method. Sub-classes can override this method to dynamically change the search fields based on request content. """ return getattr(view, ‘search_fields‘, None) def get_search_terms(self, request): """ Search terms are set by a ?search=... query parameter, and may be comma and/or whitespace delimited. """ params = request.query_params.get(self.search_param, ‘‘) params = params.replace(‘\x00‘, ‘‘) # strip null characters params = params.replace(‘,‘, ‘ ‘) return params.split() def construct_search(self, field_name): lookup = self.lookup_prefixes.get(field_name[0]) if lookup: field_name = field_name[1:] else: lookup = ‘icontains‘ return LOOKUP_SEP.join([field_name, lookup]) def must_call_distinct(self, queryset, search_fields): """ Return True if ‘distinct()‘ should be used to query the given lookups. """ for search_field in search_fields: opts = queryset.model._meta if search_field[0] in self.lookup_prefixes: search_field = search_field[1:] # Annotated fields do not need to be distinct if isinstance(queryset, models.QuerySet) and search_field in queryset.query.annotations: return False parts = search_field.split(LOOKUP_SEP) for part in parts: field = opts.get_field(part) if hasattr(field, ‘get_path_info‘): # This field is a relation, update opts to follow the relation path_info = field.get_path_info() opts = path_info[-1].to_opts if any(path.m2m for path in path_info): # This field is a m2m relation so we know we need to call distinct return True return False def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) if not search_fields or not search_terms: return queryset orm_lookups = [ self.construct_search(str(search_field)) for search_field in search_fields ] base = queryset conditions = [] for search_term in search_terms: queries = [ models.Q(**{orm_lookup: search_term}) for orm_lookup in orm_lookups ] conditions.append(reduce(operator.or_, queries)) queryset = queryset.filter(reduce(operator.and_, conditions)) if self.must_call_distinct(queryset, search_fields): # Filtering against a many-to-many field requires us to # call queryset.distinct() in order to avoid duplicate items # in the resulting queryset. # We try to avoid this if possible, for performance reasons. queryset = distinct(queryset, base) return queryset def to_html(self, request, queryset, view): if not getattr(view, ‘search_fields‘, None): return ‘‘ term = self.get_search_terms(request) term = term[0] if term else ‘‘ context = { ‘param‘: self.search_param, ‘term‘: term } template = loader.get_template(self.template) return template.render(context) def get_schema_fields(self, view): assert coreapi is not None, ‘coreapi must be installed to use `get_schema_fields()`‘ assert coreschema is not None, ‘coreschema must be installed to use `get_schema_fields()`‘ return [ coreapi.Field( name=self.search_param, required=False, location=‘query‘, schema=coreschema.String( title=force_str(self.search_title), description=force_str(self.search_description) ) ) ] def get_schema_operation_parameters(self, view): return [ { ‘name‘: self.search_param, ‘required‘: False, ‘in‘: ‘query‘, ‘description‘: force_str(self.search_description), ‘schema‘: { ‘type‘: ‘string‘, }, }, ]
标签:amp always ssi nat uid comm efault 选择 滤镜
原文地址:https://www.cnblogs.com/a00ium/p/14635978.html