Pandas入门详细教程
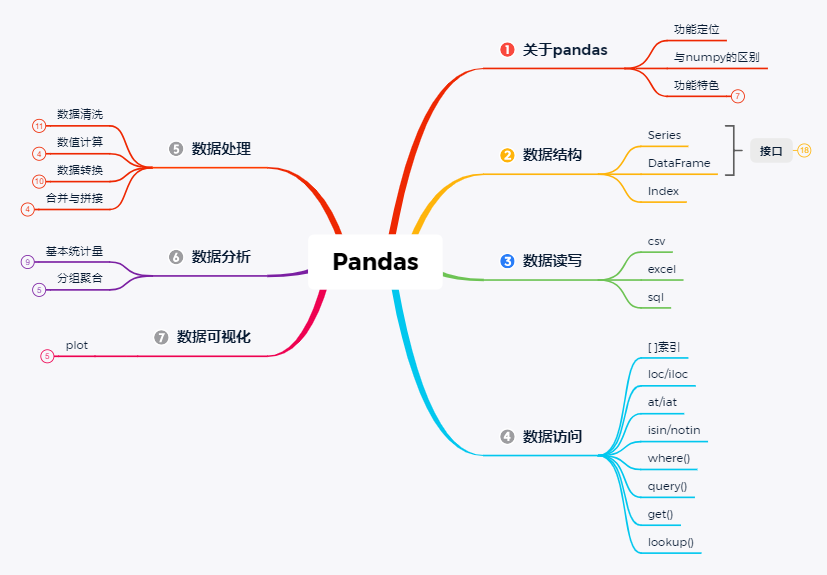
pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib的第三方数据分析库,与后两者共同构成了python数据分析的基础工具包,享有数分三剑客之名。
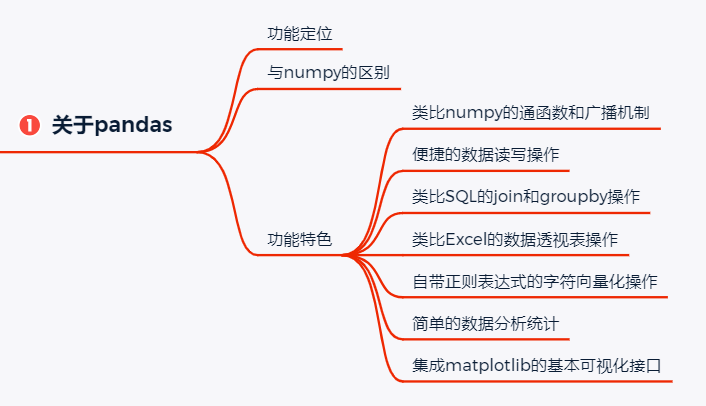
正因为pandas是在numpy基础上实现,其核心数据结构与numpy的ndarray十分相似,但pandas与numpy的关系不是替代,而是互为补充。二者之间主要区别是:-
从数据结构上看:
-
numpy的核心数据结构是ndarray,支持任意维数的数组,但要求单个数组内所有数据是同质的,即类型必须相同;而pandas的核心数据结构是series和dataframe,仅支持一维和二维数据,但数据内部可以是异构数据,仅要求同列数据类型一致即可
- numpy的数据结构仅支持数字索引,而pandas数据结构则同时支持数字索引和标签索引
-
从功能定位上看:
-
numpy虽然也支持字符串等其他数据类型,但仍然主要是用于数值计算,尤其是内部集成了大量矩阵计算模块,例如基本的矩阵运算、线性代数、fft、生成随机数等,支持灵活的广播机制
-
pandas主要用于数据处理与分析,支持包括数据读写、数值计算、数据处理、数据分析和数据可视化全套流程操作
- 按索引匹配的广播机制,这里的广播机制与numpy广播机制还有很大不同
- 便捷的数据读写操作,相比于numpy仅支持数字索引,pandas的两种数据结构均支持标签索引,包括bool索引也是支持的
- 类比SQL的join和groupby功能,pandas可以很容易实现SQL这两个核心功能,实际上,SQL的绝大部分DQL和DML操作在pandas中都可以实现
- 类比Excel的数据透视表功能,Excel中最为强大的数据分析工具之一是数据透视表,这在pandas中也可轻松实现
- 自带正则表达式的字符串向量化操作,对pandas中的一列字符串进行通函数操作,而且自带正则表达式的大部分接口
- 丰富的时间序列向量化处理接口
- 常用的数据分析与统计功能,包括基本统计量、分组统计分析等
- 集成matplotlib的常用可视化接口,无论是series还是dataframe,均支持面向对象的绘图接
02 数据结构
-
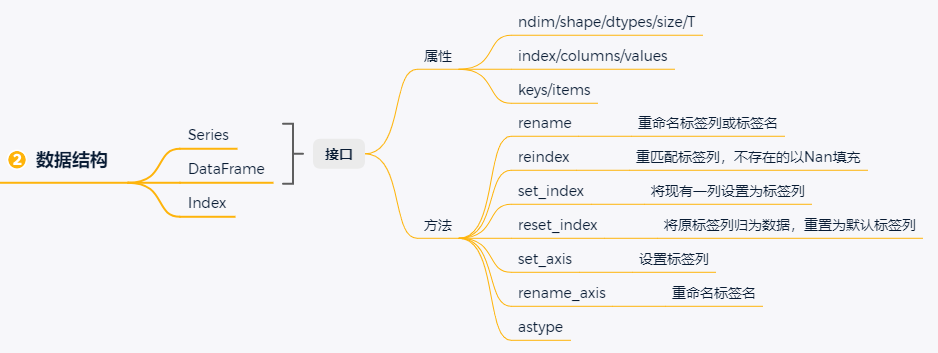
series和dataframe分别是一维和二维数组,因为是数组,所以numpy中关于数组的用法基本可以直接应用到这两个数据结构,包括数据创建、切片访问、通函数、广播机制等
-
series是带标签的一维数组,所以还可以看做是类字典结构:标签是key,取值是value;而dataframe则可以看做是嵌套字典结构,其中列名是key,每一列的series是value。所以从这个角度讲,pandas数据创建的一种灵活方式就是通过字典或者嵌套字典,同时也自然衍生出了适用于series和dataframe的类似字典访问的接口,即通过loc索引访问。
考虑series和dataframe兼具numpy数组和字典的特性,那么就不难理解二者的以下属性:注意,这里强调series和dataframe是一个类字典结构而非真正意义上的字典,原因在于series中允许标签名重复、dataframe中则允许列名和标签名均有重复,而这是一个真正字典所不允许的。
-
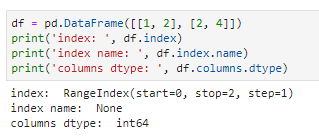
ndim/shape/dtypes/size/T,分别表示了数据的维数、形状、数据类型和元素个数以及转置结果。其中,由于pandas允许数据类型是异构的,各列之间可能含有多种不同的数据类型,所以dtype取其复数形式dtypes。与此同时,series因为只有一列,所以数据类型自然也就只有一种,pandas为了兼容二者,series的数据类型属性既可以用dtype也可以用dtypes获取;而dataframe则只能用dtypes。
-
index/columns/values,分别对应了行标签、列标签和数据,其中数据就是一个格式向上兼容所有列数据类型的array。为了沿袭字典中的访问习惯,还可以用keys()访问标签信息,在series返回index标签,在dataframe中则返回columns列名;可以用items()访问键值对,但一般用处不大。
关于series和dataframe数据结构本身,有大量的方法可用于重构结构信息:
-
rename,可以对标签名重命名,也可以重置index和columns的部分标签列信息,接收标量(用于对标签名重命名)或字典(用于重命名行标签和列标签)
-
reindex,接收一个新的序列与已有标签列匹配,当原标签列中不存在相应信息时,填充NAN或者可选的填充值
-
set_index/reset_index,互为逆操作,前者是将已有的一列信息设置为标签列,而后者是将原标签列归为数据,并重置为默认数字标签
-
set_axis,设置标签列,一次只能设置一列信息,与rename功能相近,但接收参数为一个序列更改全部标签列信息(rename中是接收字典,允许只更改部分信息)
- rename_axis,重命名标签名,rename中也可实现相同功能

在pandas早些版本中,除一维数据结构series和二维数据结构dataframe外,还支持三维数据结构panel。这三者是构成递进包容关系,panel即是dataframe的容器,用于存储多个dataframe。2019年7月,随着pandas 0.25版本的推出,pandas团队宣布正式弃用panel数据结构,而相应功能建议由多层索引实现。
也正因为pandas这3种独特的数据结构,个人一度认为pandas包名解释为:pandas = panel +dataframe + series,根据维数取相应的首字母个数,从而构成pandas,这是个人非常喜欢的一种关于pandas缩写的解释。
03 数据读写
-
文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据
-
Excel文件,包括xls和xlsx两种格式均得到支持,底层是调用了xlwt和xlrd进行excel文件操作,相应接口为read_excel()和to_excel()
-
SQL文件,支持大部分主流关系型数据库,例如MySQL,需要相应的数据库模块支持,相应接口为read_sql()和to_sql()
此外,pandas还支持html、json等文件格式的读写操作。
04 数据访问
series和dataframe兼具numpy数组和字典的结构特性,所以数据访问都是从这两方面入手。同时,也支持bool索引进行数据访问和筛选。
-
[ ],这是一个非常便捷的访问方式,不过需区分series和dataframe两种数据结构理解:
-
series:既可以用标签也可以用数字索引访问单个元素,还可以用相应的切片访问多个值,因为只有一维信息,自然毫无悬念
- dataframe:无法访问单个元素,只能返回一列、多列或多行:单值或多值(多个列名组成的列表)访问时按列进行查询,单值访问不存在列名歧义时还可直接用属性符号" . "访问。切片形式访问时按行进行查询,又区分数字切片和标签切片两种情况:当输入数字索引切片时,类似于普通列表切片;当输入标签切片时,执行范围查询(即无需切片首末值存在于标签列中),包含两端标签结果,无匹配行时返回为空,但要求标签切片类型与索引类型一致。例如,当标签列类型(可通过df.index.dtype查看)为时间类型时,若使用无法隐式转换为时间的字符串作为索引切片,则引发报错
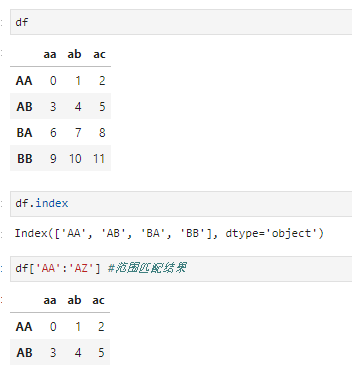
切片形式返回行查询,且为范围查询
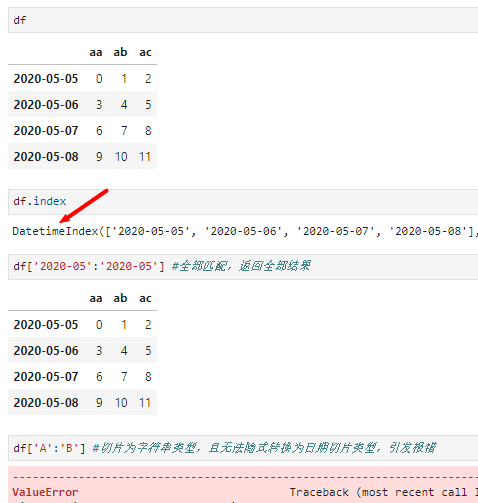
切片类型与索引列类型不一致时,引发报错
- loc/iloc,最为常用的两种数据访问方法,其中loc按标签值访问、iloc按数字索引访问,均支持单值访问或切片查询。与[ ]访问类似,loc按标签访问时也是执行范围查询,包含两端结果
- at/iat,loc和iloc的特殊形式,不支持切片访问,仅可以用单个标签值或单个索引值进行访问,一般返回标量结果,除非标签值存在重复
- isin/notin,条件范围查询,即根据特定列值是否存在于指定列表返回相应的结果
-
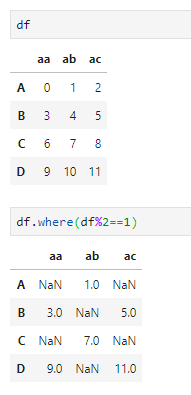
where,仍然是执行条件查询,但会返回全部结果,只是将不满足匹配条件的结果赋值为NaN或其他指定值,可用于筛选或屏蔽值
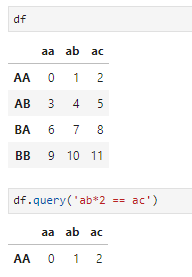
- query,按列对dataframe执行条件查询,一般可用常规的条件查询替代
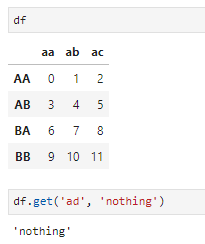
- get,由于series和dataframe均可以看做是类字典结构,所以也可使用字典中的get()方法,主要适用于不确定数据结构中是否包含该标签时,与字典的get方法完全一致
- lookup,loc的一种特殊形式,分别传入一组行标签和列标签,lookup解析成一组行列坐标,返回相应结果:
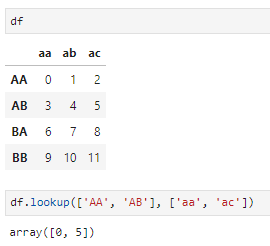
pandas中支持大量的数据访问接口,但万变不离其宗:只要联想两种数据结构兼具numpy数组和字典的双重特性,就不难理解这些数据访问的逻辑原理。当然,重点还是掌握[]、loc和iloc三种方法。
loc和iloc应该理解为是series和dataframe的属性而非函数,应用loc和iloc进行数据访问就是根据属性值访问的过程
另外,在pandas早些版本中,还存在loc和iloc的兼容结构,即ix,可混合使用标签和数字索引,但往往容易混乱,所以现已弃用
05 数据处理
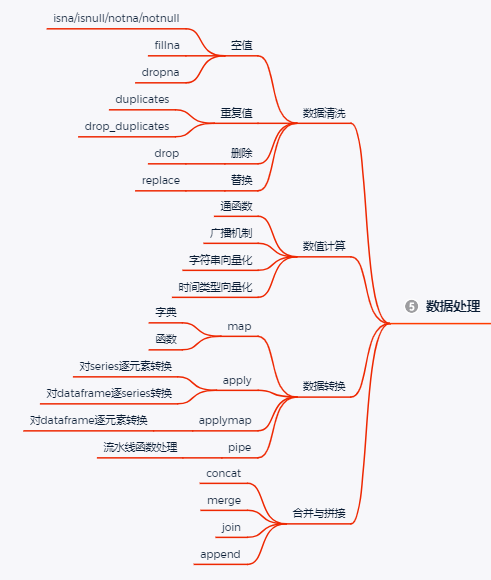
pandas最为强大的功能当然是数据处理和分析,可独立完成数据分析前的绝大部分数据预处理需求。简单归纳来看,主要可分为以下几个方面:
1.数据清洗
数据处理中的清洗工作主要包括对空值、重复值和异常值的处理:- 空值
- 判断空值,isna或isnull,二者等价,用于判断一个series或dataframe各元素值是否为空的bool结果。需注意对空值的界定:即None或numpy.nan才算空值,而空字符串、空列表等则不属于空值;类似地,notna和notnull则用于判断是否非空
- 填充空值,fillna,按一定策略对空值进行填充,如常数填充、向前/向后填充等,也可通过inplace参数确定是否本地更改
-
删除空值,dropna,删除存在空值的整行或整列,可通过axis设置,也包括inplace参数
- 重复值
- 检测重复值,duplicated,检测各行是否重复,返回一个行索引的bool结果,可通过keep参数设置保留第一行/最后一行/无保留,例如keep=first意味着在存在重复的多行时,首行被认为是合法的而可以保留
-
删除重复值,drop_duplicates,按行检测并删除重复的记录,也可通过keep参数设置保留项。由于该方法默认是按行进行检测,如果存在某个需要需要按列删除,则可以先转置再执行该方法
- 异常值,判断异常值的标准依赖具体分析数据,所以这里仅给出两种处理异常值的可选方法
- 删除,drop,接受参数在特定轴线执行删除一条或多条记录,可通过axis参数设置是按行删除还是按列删除
- 替换,replace,非常强大的功能,对series或dataframe中每个元素执行按条件替换操作,还可开启正则表达式功能
2.数值计算
由于pandas是在numpy的基础上实现的,所以numpy的常用数值计算操作在pandas中也适用:
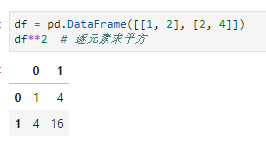
- 通函数ufunc,即可以像操作标量一样对series或dataframe中的所有元素执行同一操作,这与numpy的特性是一致的,例如前文提到的replace函数,本质上可算作是通函数。如下实现对数据表中逐元素求平方
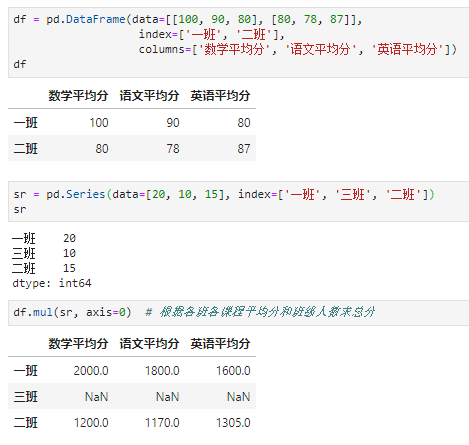
- 广播机制,即当维度或形状不匹配时,会按一定条件广播后计算。由于pandas是带标签的数组,所以在广播过程中会自动按标签匹配进行广播,而非类似numpy那种纯粹按顺序进行广播。例如,如下示例中执行一个dataframe和series相乘,虽然二者维度不等、大小不等、标签顺序也不一致,但仍能按标签匹配得到预期结果
- 字符串向量化,即对于数据类型为字符串格式的一列执行向量化的字符串操作,本质上是调用series.str属性的系列接口,完成相应的字符串操作。尤为强大的是,除了常用的字符串操作方法,str属性接口中还集成了正则表达式的大部分功能,这使得pandas在处理字符串列时,兼具高效和强力。例如如下代码可用于统计每个句子中单词的个数
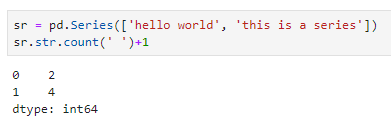
需注意的是,这里的字符串接口与python中普通字符串的接口形式上很是相近,但二者是不一样的。
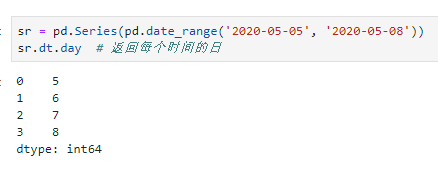
- 时间类型向量化操作,如字符串一样,在pandas中另一个得到"优待"的数据类型是时间类型,正如字符串列可用str属性调用字符串接口一样,时间类型列可用dt属性调用相应接口,这在处理时间类型时会十分有效。
3.数据转换
前文提到,在处理特定值时可用replace对每个元素执行相同的操作,然而replace一般仅能用于简单的替换操作,所以pandas还提供了更为强大的数据转换方法
- map,适用于series对象,功能与python中的普通map函数类似,即对给定序列中的每个值执行相同的映射操作,不同的是series中的map接口的映射方式既可以是一个函数,也可以是一个字典

- apply,既适用于series对象也适用于dataframe对象,但对二者处理的粒度是不一样的:apply应用于series时是逐元素执行函数操作;apply应用于dataframe时是逐行或者逐列执行函数操作(通过axis参数设置对行还是对列,默认是行),仅接收函数作为参数

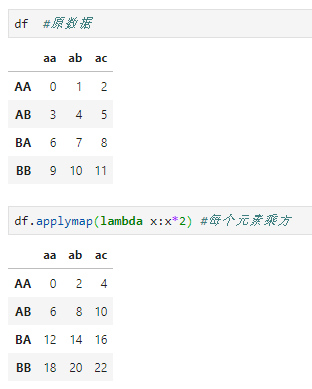
- applymap,仅适用于dataframe对象,且是对dataframe中的每个元素执行函数操作,从这个角度讲,与replace类似,applymap可看作是dataframe对象的通函数。
4.合并与拼接
pandas中又一个重量级数据处理功能是对多个dataframe进行合并与拼接,对应SQL中两个非常重要的操作:union和join。pandas完成这两个功能主要依赖以下函数:
-
concat,与numpy中的concatenate类似,但功能更为强大,可通过一个axis参数设置是横向或者拼接,要求非拼接轴向标签唯一(例如沿着行进行拼接时,要求每个df内部列名是唯一的,但两个df间可以重复,毕竟有相同列才有拼接的实际意义)
-
merge,完全类似于SQL中的join语法,仅支持横向拼接,通过设置连接字段,实现对同一记录的不同列信息连接,支持inner、left、right和outer4种连接方式,但只能实现SQL中的等值连接
-
join,语法和功能与merge一致,不同的是merge既可以用pandas接口调用,也可以用dataframe对象接口调用,而join则只适用于dataframe对象接口
-
append,concat执行axis=0时的一个简化接口,类似列表的append函数一样
建表语句
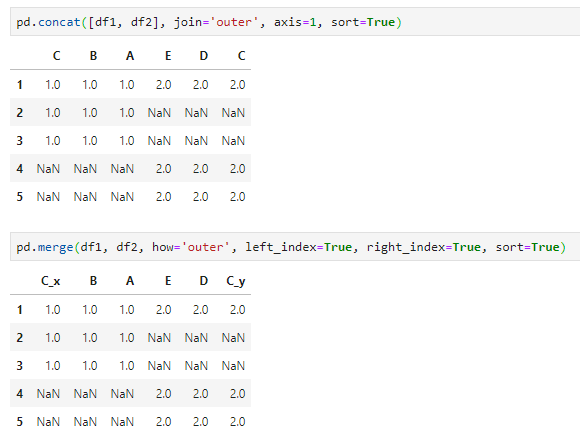
通过设置参数,concat和merge实现相同效果
06 数据分析
pandas中的另一大类功能是数据分析,通过丰富的接口,可实现大量的统计需求,包括Excel和SQL中的大部分分析过程,在pandas中均可以实现。
1.基本统计量
pandas内置了丰富的统计接口,这是与numpy是一致的,同时又包括一些常用统计信息的集成接口。
-
info,展示行标签、列标签、以及各列基本信息,包括元素个数和非空个数及数据类型等
-
head/tail,从头/尾抽样指定条数记录
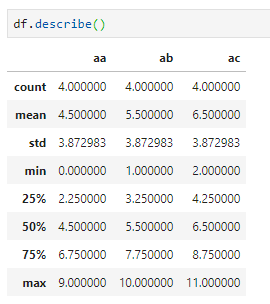
- describe,展示数据的基本统计指标,包括计数、均值、方差、4分位数等,还可接收一个百分位参数列表展示更多信息
- count、value_counts,前者既适用于series也适用于dataframe,用于按列统计个数,实现忽略空值后的计数;而value_counts则仅适用于series,执行分组统计,并默认按频数高低执行降序排列,在统计分析中很有用

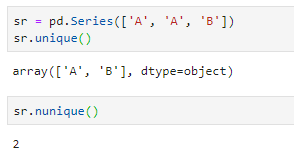
- unique、nunique,也是仅适用于series对象,统计唯一值信息,前者返回唯一值结果列表,后者返回唯一值个数(number of unique)
- sort_index、sort_values,既适用于series也适用于dataframe,sort_index是对标签列执行排序,如果是dataframe可通过axis参数设置是对行标签还是列标签执行排序;sort_values是按值排序,如果是dataframe对象,也可通过axis参数设置排序方向是行还是列,同时根据by参数传入指定的行或者列,可传入多行或多列并分别设置升序降序参数,非常灵活。另外,在标签列已经命名的情况下,sort_values可通过by标签名实现与sort_index相同的效果。
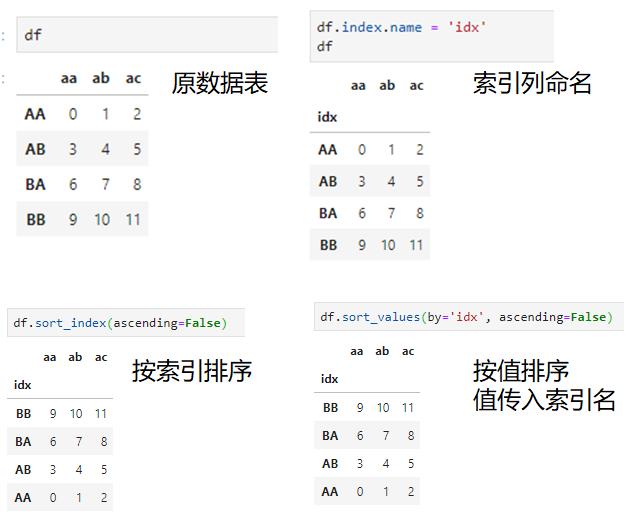
2.分组聚合
pandas的另一个强大的数据分析功能是分组聚合以及数据透视表,前者堪比SQL中的groupby,后者媲美Excel中的数据透视表。- groupby,类比SQL中的group by功能,即按某一列或多列执行分组。一般而言,分组的目的是为了后续的聚合统计,所有groupby函数一般不单独使用,而需要级联其他聚合函数共同完成特定需求,例如分组求和、分组求均值等。

pandas官网关于groupby过程的解释
级联其他聚合函数的方式一般有两种:单一的聚合需求用groupby+聚合函数即可,复杂的大量聚合则可借用agg函数,agg函数接受多种参数形式作为聚合函数,功能更为强大。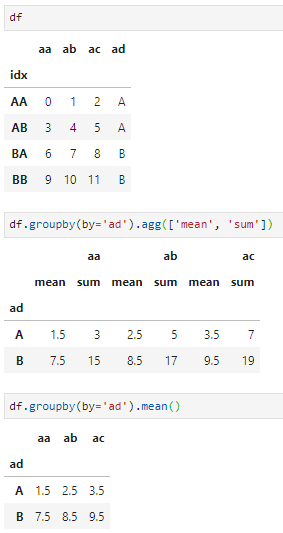
两种分组聚合形式
- pivot,pivot英文有"支点"或者"旋转"的意思,排序算法中经典的快速排序就是不断根据pivot不断将数据二分,从而加速排序过程。用在这里,实际上就是执行行列重整。例如,以某列取值为重整后行标签,以另一列取值作为重整后的列标签,以其他列取值作为填充value,即实现了数据表的行列重整。以SQL中经典的学生成绩表为例,给定原始学生—课程—成绩表,需重整为学生vs课程的成绩表,则可应用pivot实现:
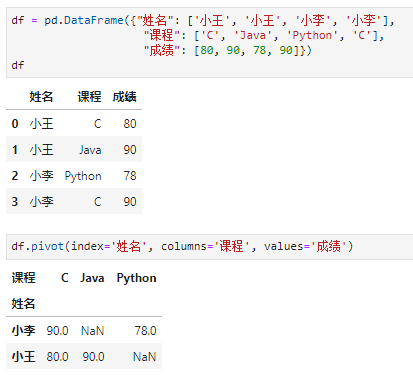
另外,还有一对函数也常用于数据重整,即stack和unstack,其中unstack执行效果与pivot非常类似,而stack则是unstack的逆过程。
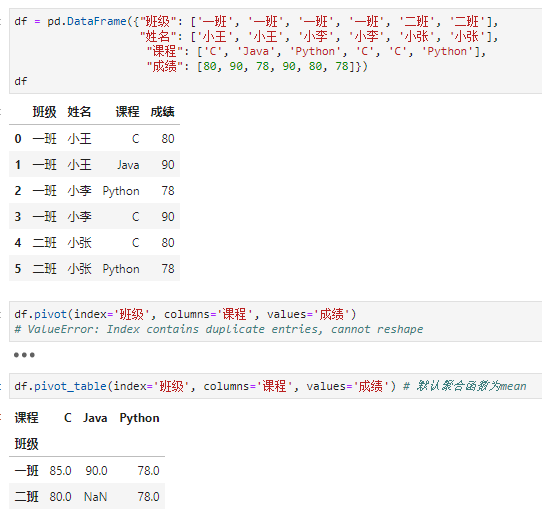
- pivot_table,有了pivot就不难理解pivot_table,实际上它是在前者的基础上增加了聚合的过程,类似于Excel中的数据透视表功能。仍然考虑前述学生成绩表的例子,但是再增加一列班级信息,需求是统计各班级每门课程的平均分。由于此时各班的每门课成绩信息不唯一,所以直接用pivot进行重整会报错,此时即需要对各班各门课程成绩进行聚合后重整,比如取平均分。
07 数据可视化
pandas集成了matplotlib中的常用可视化图形接口,可通过series和dataframe两种数据结构面向对象的接口方式简单调用。关于面向对象接口和plt接口绘图方式的区别,可参考python数据科学系列:matplotlib入门详细教程。
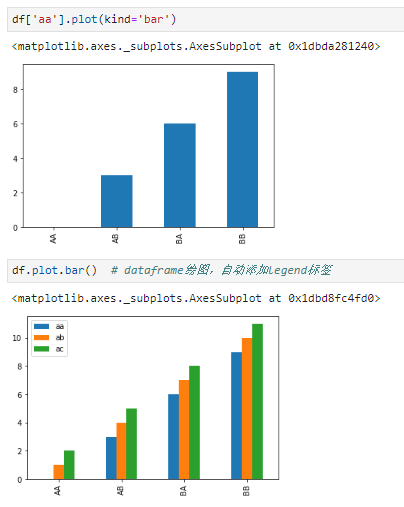
两种数据结构作图,区别仅在于series是绘制单个图形,而dataframe则是绘制一组图形,且在dataframe绘图结果中以列名为标签自动添加legend。另外,均支持两种形式的绘图接口:- plot属性+相应绘图接口,如plot.bar()用于绘制条形图
-
plot()方法并通过传入kind参数选择相应绘图类型,如plot(kind=‘bar‘)
不过,pandas绘图中仅集成了常用的图表接口,更多复杂的绘图需求往往还需依赖matplotlib或者其他可视化库。