标签:模拟 策略 报错 lazy 表格 行数据 刷新 大于 load
本作品不可用于任何商业途径,仅供学习交流!!!
分析:
在浏览器打开淘宝,随便搜索某件商品,打开浏览器的抓包工具,刷新网页,对抓取到的数据包进行分析和测试:
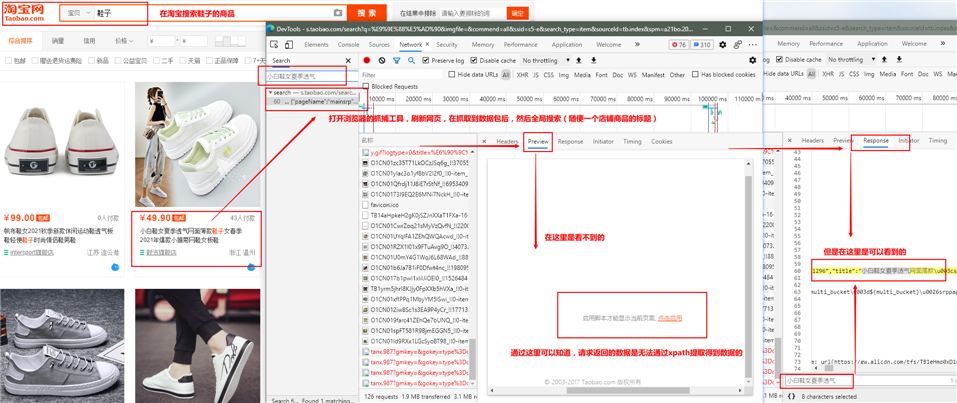
对上面的抓包的分析,进一步的分析、测试和验证:
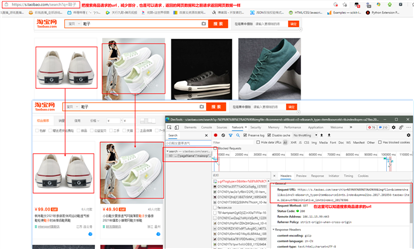
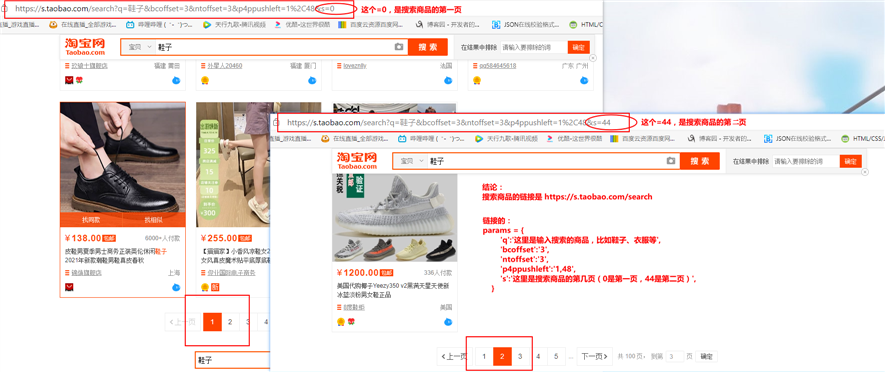
对上面的抓包的分析和结论,进一步的分析、测试和验证:
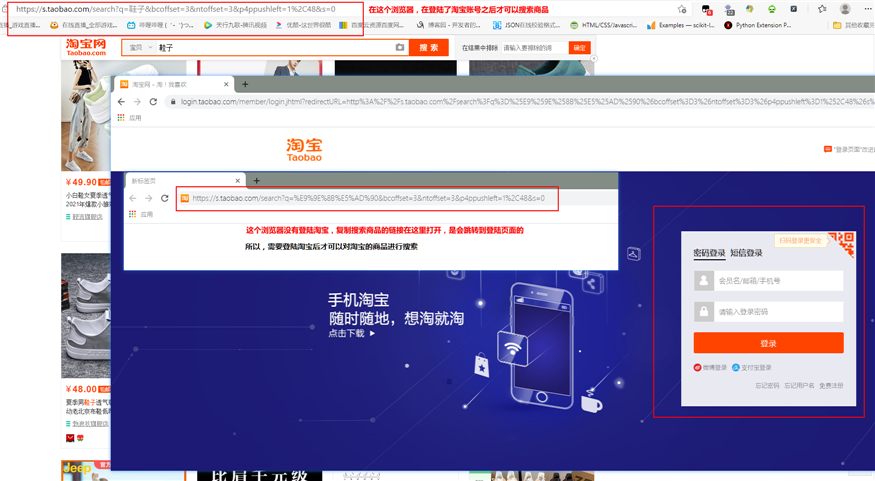
在另外的浏览器,对上面的抓包的分析和结论,进一步的分析、测试和验证(找是否有反爬策略),由于淘宝的有反爬策略(ua加密比较难破解),这里使用selenium模拟登陆传递cookie给requests(requests抓取数据)来处理:
淘宝的反爬是比较厉害的,如果频繁请求,淘宝的服务器就会检测到,就会出现滑动模块访问验证,要是出现这样的情况,就无法抓取到数据,所以该项目是有缺陷的(在requests, 不会处理这个反爬策略),在没有出现滑动模块访问验证,该工程才可以抓取到数据,反之不能!!
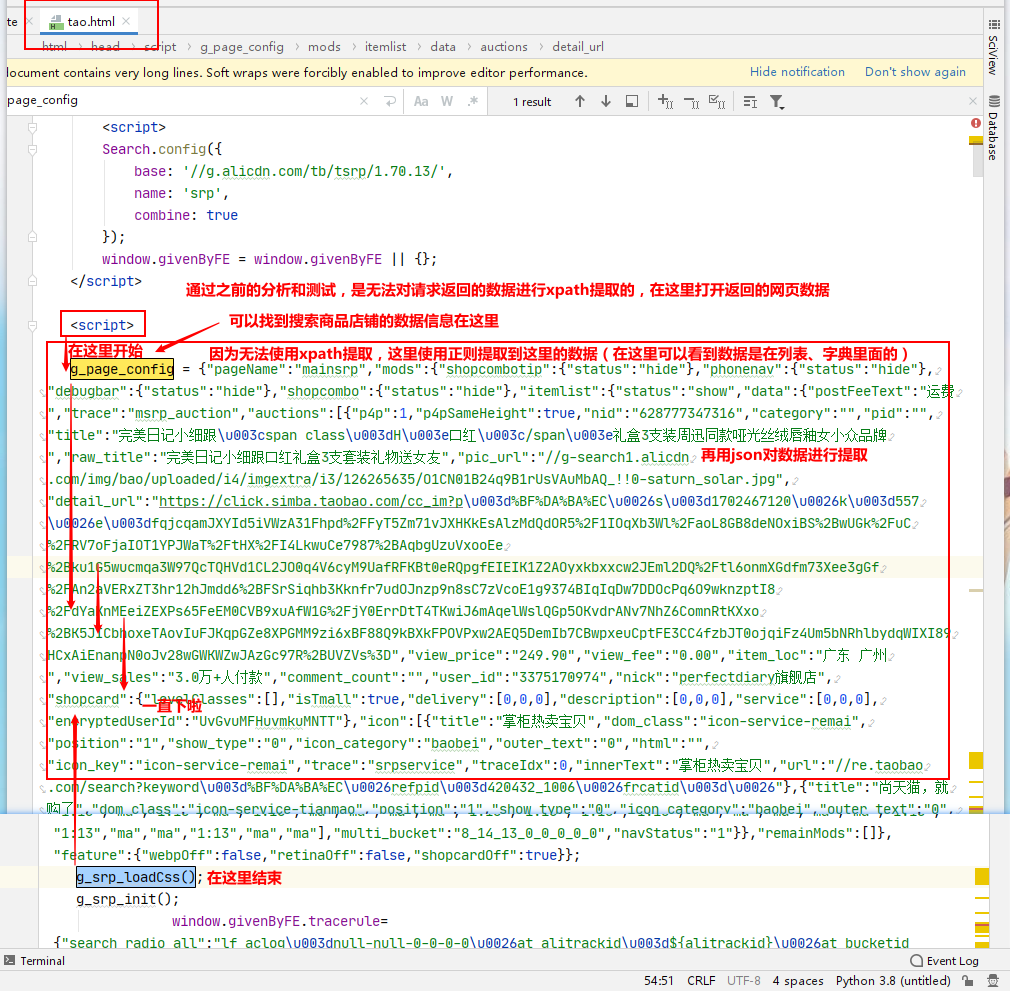
在pycharm,把抓取到的请求相应网页源数据以html保存在本地,进行多次测试、分析和验证,来实现工程(因为要测试很多次,加上淘宝的反爬是比较厉害的,要是以请求响应的数据进行测试的话,测试不了几次就测试不了了)
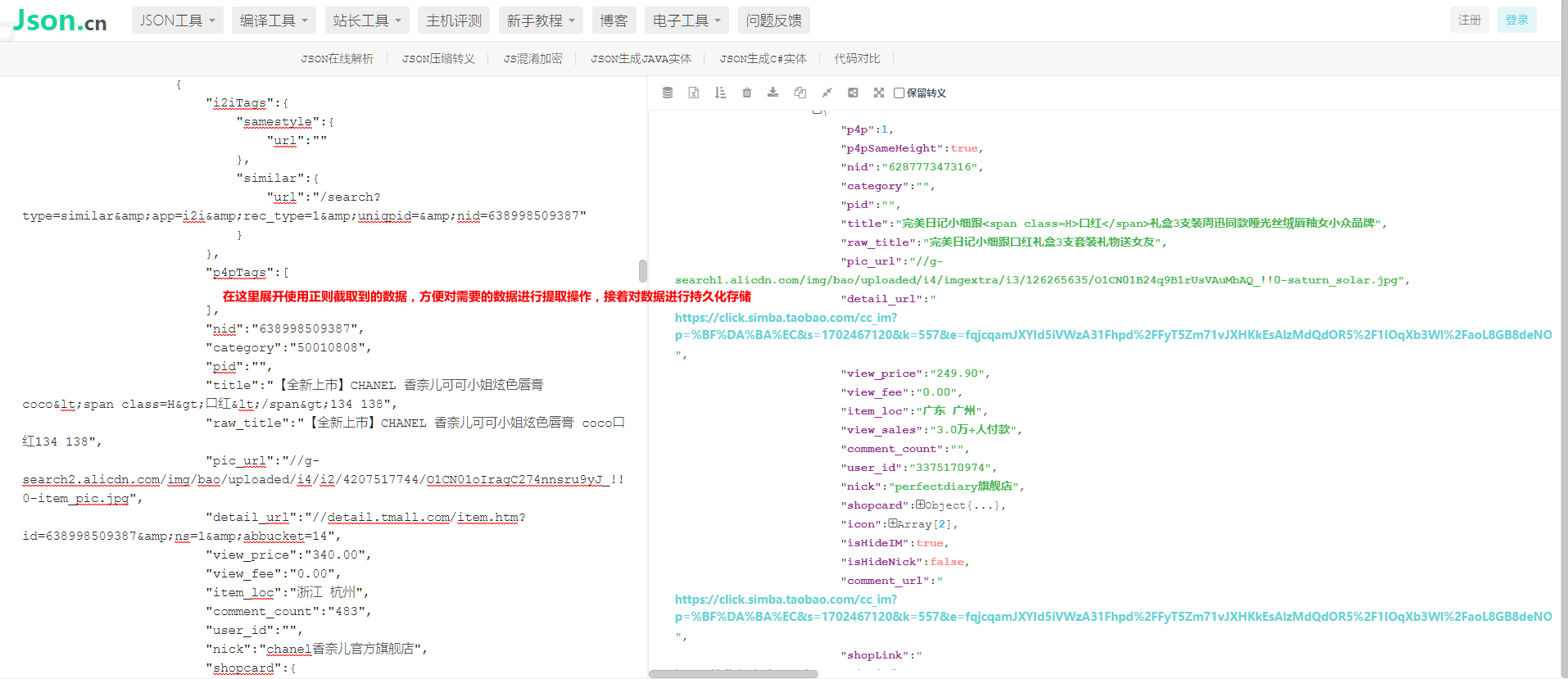
在这个网站查看展开的json的字典数据,方便提取需要是信息,接着持久化保存数据信息:
工程代码部分:
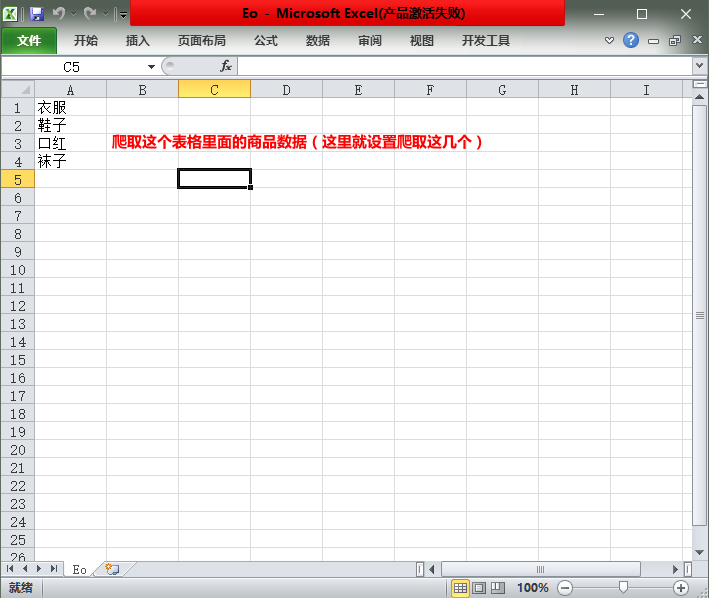
这里抓取csv表格文件里面商品的数据(这里就设置搜索4个商品)
搜索商品的请求函数,函数返回请求的响应:

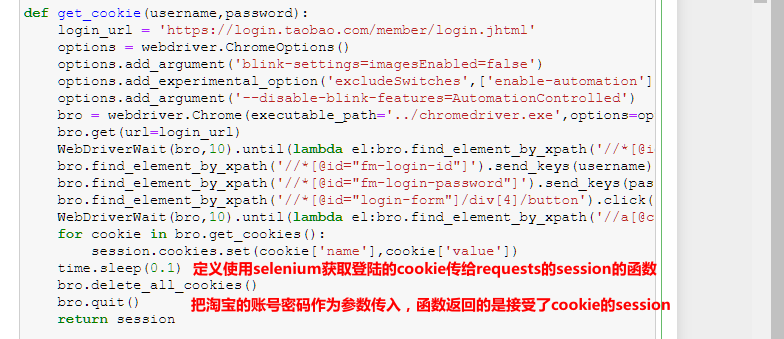
模拟登陆,获取到的cookie传给requests的session,函数返回的是接收了cookie的session:
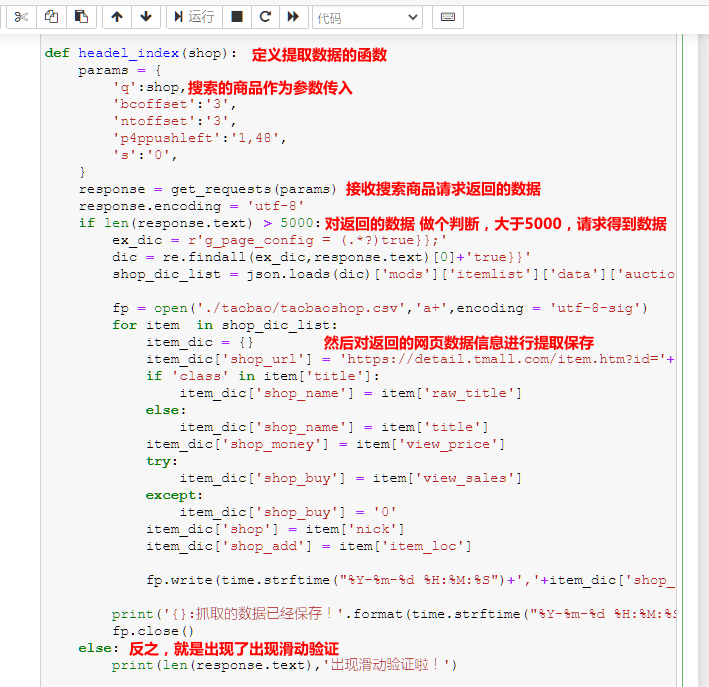
把要搜索的商品最为参数传入该函数,并且对搜索商品请求返回的网页源数据做个判断;对搜索商品数据大于5000的(请求到数据),进行数据提取保存,反之则是出现的滑动验证,不做数据提取保存,打印报错(‘出现滑动验证‘!)
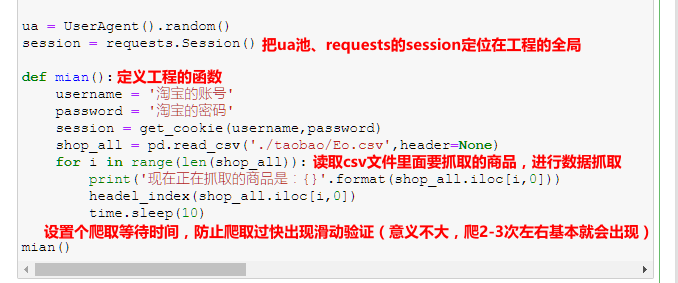
定义工程控制函数:
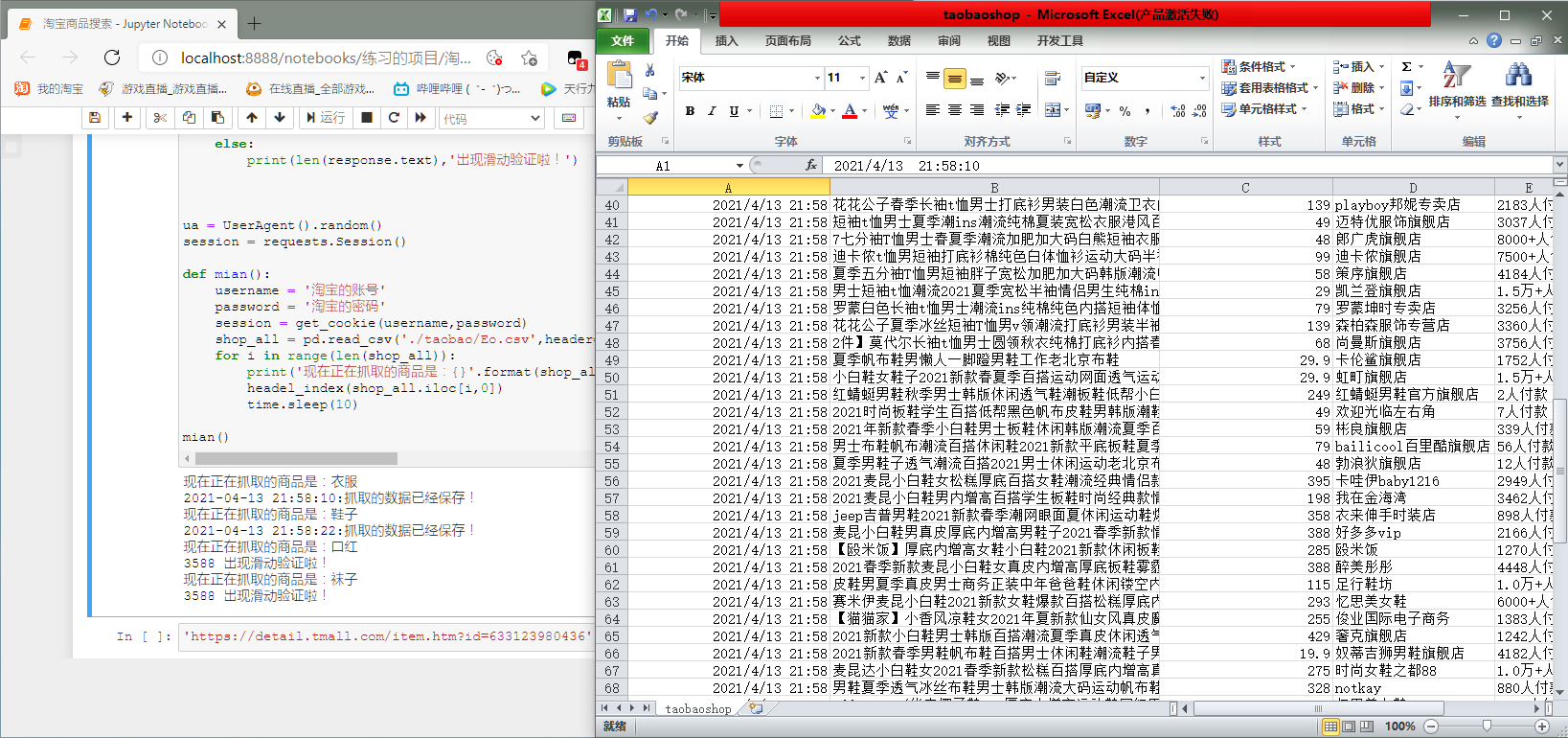
最后,跑该工程的成果图:
本作品不可用于任何商业途径,仅供学习交流!!!
selenium模拟登陆 + requests抓取数据:淘宝商品搜索!!!
标签:模拟 策略 报错 lazy 表格 行数据 刷新 大于 load
原文地址:https://www.cnblogs.com/YYQ-4414/p/14653800.html