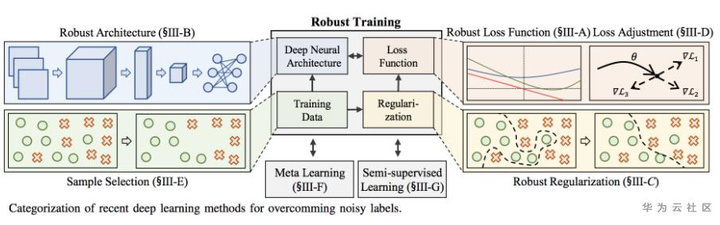
标签:data cdc 交流 cee ssl 产生 个数 组合 纠正
摘要:介绍带噪学习领域前沿方法,解决不完美场景下的神经网络优化策略,旨在提升模型性能。
神经网络的成功建立在大量的干净数据和很深的网络模型基础上。但是在现实场景中数据和模型往往不会特别理想,比如数据层面有误标记的情况,像小狗被标注成狼,而且实际的业务场景讲究时效性,神经网络的层数不能特别深。我们尝试不断迭代数据和模型缺陷情况下神经网络的有效训练方法,通过noisy label learning技术,解决网络训练过程中noisy data的问题,该技术已经在团队实际业务场景中落地,通过从损失函数、网络结构、模型正则化、损失函数调整、样本选择、标签纠正等多个模块的优化,不局限于全监督、半监督和自监督学习方法,提升整个模型的鲁棒性
主要是从损失函数去修改,核心思路是当数据整体是干净的时候,传统的交叉熵损失函数学习到少量的负样本,可以提升模型的鲁棒性;当数据噪声比较大时,CE会被噪声数据带跑偏,我们要修改损失函数使其在训练中每个样本的权重都是一样重要的,因此不难想到采用GCE Loss,控制超参数,结合了CE Loss和MAE Loss
另外,还有从KL散度想法借鉴过来的,作者认为在计算熵的时候,原始q, p代表的真实数据分布和预测值在较为干净的数据上没有问题,但是在噪声比较大的数据上,可能q并不能代表真实数据分布,相反的是不是p可以表示真实数据分布,因此提出基于对称的交叉熵损失函数(Symmetric cross entropy )
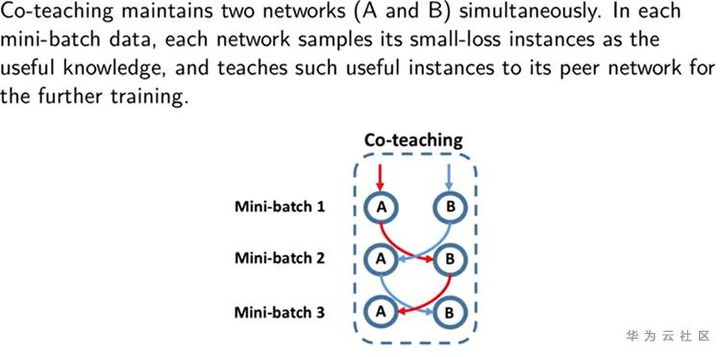
这一部分主要通过借鉴巧妙的网络结构,在模型训练过程中,通过模型对数据进行挑选,选择一批较为干净的数据,逐步提升模型的鲁棒性。首先要介绍的就是coteaching framework,首先是基于两个模型相互挑选数据输入给对方计算loss,传递给对方网络的数据是每个min-batch里面loss最低的一些数据,随着epoch增加,数据量有所变化,另外每一轮epoch结束,会shuffle数据,保证数据不会被永久遗忘
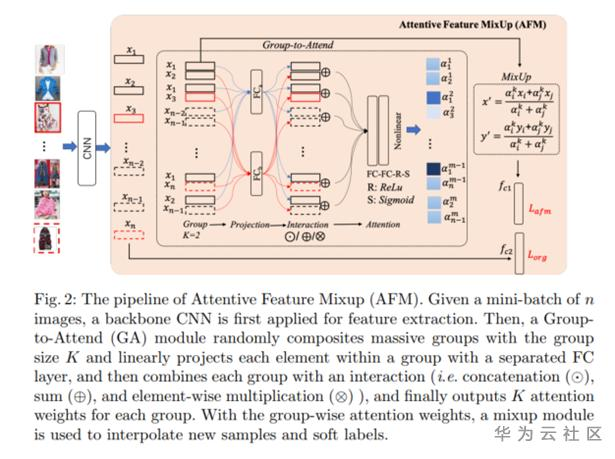
还有一种思路,是基于attention注意力机制给干净样本和噪声数据进行打分,文章叫做Attention Feature Mixup,在计算最终loss的时候有两部分,一部分是同一个类的每张图和标签计算的交叉熵损失;另外一个损失是数据mixup得到的新的数据x‘和标签y‘计算的loss
这一部分主要是通过一些添加正则ticks,防止模型过拟合到噪声数据上,常用的正则方法包含:label smooth、l1、l2、MixUp等
这一部分其实也是一些训练的ticks,其实和loss function改进是密不可分的,这里不做详细ticks的介绍
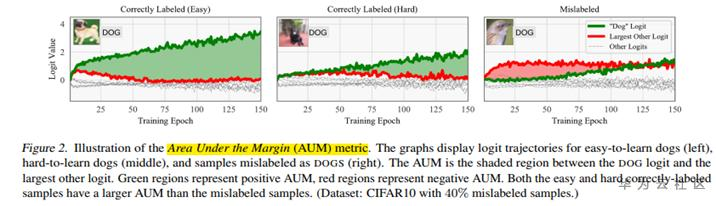
这一模块主要是从如何挑选出更好的数据为出发点,一种方法,叫做Area Under the Margin metric (AUM),是我们去年参加CVPR WebVision 2020(图像识别领域最高级别的比赛,接替ImageNet)取得冠军的方案。该方案是一种在训练过程中一边训练一边筛选数据的方式,具体思想是在一个min-batch利用模型计算每张图片的logits值和其它类中最大的logits求差值当做area,这样多轮epoch求平均,得到每张图的aum值。试验发现如果这个数据是较为干净的数据area的值会比较大,如果是存在mis-label的数据area值比较小,甚至是负值,作者就是通过这个思想将一个类的干净数据和噪声数据分离开的。当然论文在最后也指出,干净数据和噪声数据占比99%的阈值是最优的。
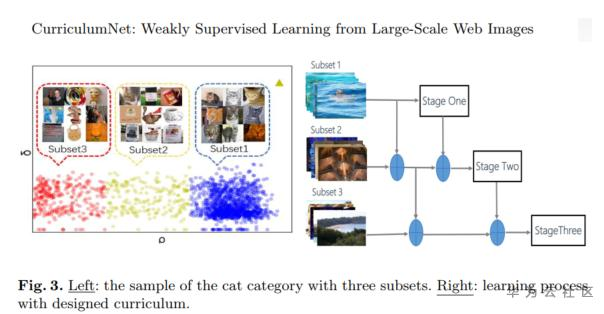
另外一篇,数据划分是通过密度聚类的思路,将一个类的数据分成easy dataset、smi-hard dataset和hard dataset,一般噪声数据是较为困难训练的数据,对于每张图分配一个权重,文中建议1.0、0.5和0.5;模型的训练借鉴了课程学习的思路
基于半监督学习的带噪学习算法,首先介绍一篇DivideMix方法,其实还是co-teaching的思路,但是在挑出干净样本和噪音样本后,把噪音样本当做无标签样本,通过 FixMatch 的方法进行训练,目前半监督图像分类的 SOTA 应该还是 FixMatch,其在 90% 的无标签样本下都能取得接近有监督的结果...所以现在取得高准确率的思路基本都是朝着半监督和如何完整区分出噪音这个大方向走的
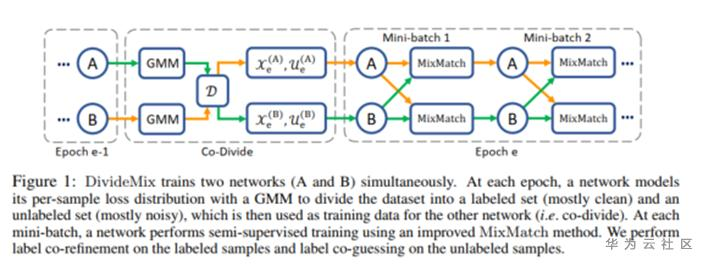
整体pipline分为两大部分:Co-Divide和基于semi-supervised learning
Co-Divide部分借鉴pre-trained model对N个样本计算loss,这里有个假设,这N个变量是由两个高斯分布的混合分布产生的,其中均值较大的那个分布是噪声样本,均值较小的是干净样本,那么接下来基于该设定,我们就可以根据每个样本的loss,分别求出它属于干净样本的概率wi,得到阈值就可以按照设定的阈值将训练数据分为有标签和无标签两类,然后借鉴SSL方法进行训练。
需要注意为了让模型收敛,我们需要在划分数据之前,先用全部的数据对模型训练几个epochs,以达到“预热”的目的。然而“预热”过程会导致模型对非对称噪声样本过拟合从而使得噪声样本也具有较小的loss,这样GMM就不好判别了,会影响到后面的训练。为了解决这个问题,我们在“预热”训练时的,可以在原先交叉熵损失的基础上加入额外的正则项-H,这个正则项就是一个负熵,惩罚预测概率分布比较尖锐的样本,令概率分布平坦一些,这样就可以防止模型过于“自信”。
对训练数据进行划分之后,我们就可以利用一些现成的半监督学习方法来训练模型,论文中采用的是目前常用的MixMatch方法,不过再用MixMatch之前,论文还做了co-refinement与co-guess的改进

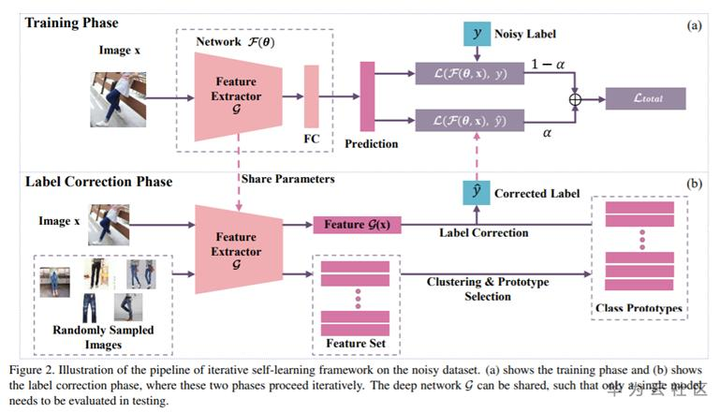
标签纠正方法思路很简单就是相当于是一个重新打一个伪标签的概念,但是完全放弃原始的标签也过于暴力,ICCV2019的这篇文章在“label correction phase”通过一个pre-trained模型得到随机选择每个类中的几张图采用聚类的方法得到Prototype样本的每个类的聚类中心,对输入图片得到的特征向量和各类聚类中心计算距离,得到图片的伪标签,最后的loss是原始标签计算的交叉熵损失和伪标签计算的伪标签的求和
带噪学习领域的研究是十分有意义的,我们在我们的场景进行了验证,都有不错的提升,最低有2~3个点的提升,最高有10个点的提升,当然在一个场景的验证不能够完全说明方法的有效性,我们也发现多种方法的组合有时候并不能起到一个double性能的提升,反而有可能降低最终的结果。
我们希望能够采用AutoML的思路来选择最优的组合方式,另外希望带噪学习的方法迁移性能够强一些,毕竟现在大部分还都集中在分类任务当中,后期我们也会探究一下Meta Learning在带噪学习领域的方法,同时会不断更新每个模块的最新方法,完善在mmclassification当中,欢迎一起交流
附件下载:learning with noisy label.pptx 8.51MB
本文分享自华为云社区《Learning from Noisy Labels with Deep Neural Networks》,原文作者:猜沟。
标签:data cdc 交流 cee ssl 产生 个数 组合 纠正
原文地址:https://www.cnblogs.com/huaweiyun/p/14657022.html