标签:pos attention with The 子类 strong 降维 概念 att
论文:《Learning Similarity Conditions Without Explicit Supervision》
论文地址:https://arxiv.org/pdf/1908.08589.pdf
代码地址:https://github.com/rxtan2/Learning-Similarity-Conditions
联系方式:
Github:https://github.com/ccc013
知乎专栏:机器学习与计算机视觉,AI 论文笔记
微信公众号:AI 算法笔记

目前搭配方面的工作都比较依赖于多种相似条件,比如在颜色、类型和形状的相似性,通过学习到基于条件的 embedding,这些模型可以学习到不同的相似信息,但是也受限于这种做法以及显式的标签问题,导致它们没办法生成没见过的类别。
所以,本文希望在弱监督的条件下,将不同的相似条件和属性作为一个隐变量,学习到对应的特征子空间,如下图所示,对比了本文的方法和先前的一些工作。
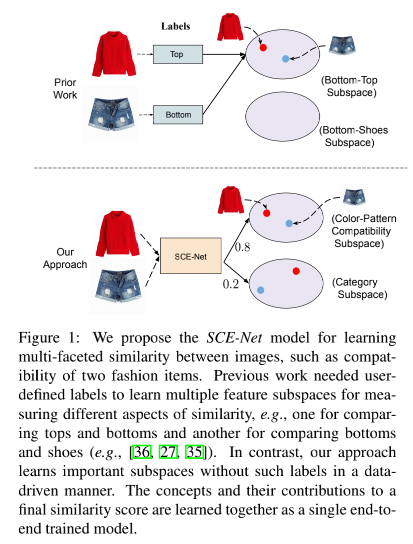
先前的工作需要用户定义的标签来学习不同相似性的特征子空间,比如上衣和裤子的子空间,或者裤子和鞋子的子空间。而对于本文的方法来说,并不需要这些显式的标签来学习特征子空间。
本文是提出了一个相似条件向量网络(Similarity Condition Embedding Network,SCE-Net)模型从一个统一的向量空间中联合学习不同的相似条件,一个整体结构示意图如下所示:
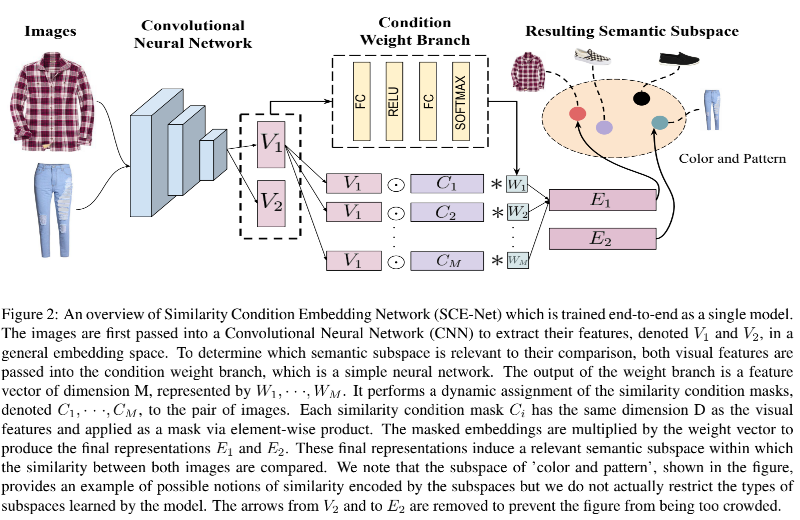
本文的贡献归纳如下:
这部分将介绍本文提出的 SCE-Net 模型,它是在一个弱监督条件下,将不同的相似条件以及属性当做隐变量,从而学习到对应的特征子空间。
首先输入的图片将输入到 CNN 中提取特征,这里我们用 $g(x;\theta)$ 进行表示,其中 x 表示输入图片,而$\theta$ 表示模型参数。本文的网络主要包含两个部件:
这会在接下来的两个小节里分别介绍,然后第三小节会介绍在不同输入形式下,条件权重分支的变形。
本文的模型的一个关键组件就是一组 M 个平行的相似条件掩码,记作 $C_1, C_2,\cdots,C_M$,其维度是 D,其中 M 是通过held out data 进行实验得到的数值。
这组相似条件掩码和图片特征进行点积的计算,从而让图片特征映射到一个编码了不同相似子结构的二阶语义子空间 $R^D$.
令 $C_j$ 表示每个相似条件掩码,$V_i$ 表示生成的图片特征,则上述操作可以如下所示:
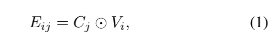
上述输出结果的维度是 $M\times D$,令 O 表示掩码操作的输出,即 $O=[E_{i1},\cdots,E_{iM}]$ ,所以最终的输出为:

这里的 w 是一个维度为 M 的权重向量,它是由条件权重分支计算得到的。
没有选择预先定义一套相似条件,本文选择使用一个条件权重分支来让模型自动决定需要学习的条件。
条件权重分支会基于一对给定比较的对象决定了每个条件掩码的关联性。对于一对图片 $x_i, x_j$ ,它们经过 CNN 提取到的特征计算如下所示:
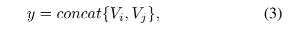
这里的 concat 表示连接操作,如之前给出的整体结构图所示,经过 CNN 提取特征然后进行 concat 操作后,将进入条件权重分支,主要是包括多个全连接层和 RELU 激活函数,最后使用一个 softmax 层得到 M 维的向量 w。
对于学习复杂相似性关系的时候,很常用的一个方法就是 triplet loss。我们定义一个三元组 ${x_i, x_j, x_k}$ ,其中 $x_i$ 是目标对象,而 $x_j, x_k$ 则分别是正负样本,即在一些不可见的条件 c 下,和 $x_i$ 在语义上相似和不相似的两个样本。triplet loss 的计算如下所示:
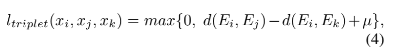
其中 $d(E_i, E_j)$ 采用的是欧式距离,然后间隔 $\mu$ 是一个超参数。
除此之外,本文还对相似条件掩码采用一个 L1 loss 来鼓励稀疏性和分离性。另外还用一个 L2 loss 来约束学习的图片特征,所以最终整个模型的目标函数如下所示:
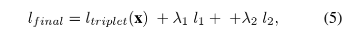
除了仅输入图片外,本文也进行了其他不同输入形式的实验,这包括了:
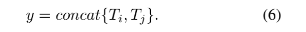
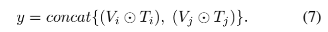
实际上还有其他处理文本和图片特征的方式,比如连接后映射到相同的向量空间,但是在本文实验中上述直接进行点积操作是性能最好的。
本文采用了 3 个数据集进行实验,分别是 Maryland-Polyvore , Polyvore-Outfits,以及 UT-Zappos50k。其中前两个数据集包含两种任务的验证集,分别是搭配匹配性预测和 fill-in-the-blank 任务,而第三个数据集是用于评估本文模型识别不同强度的属性的能力。
Maryland-Polyvore:该数据集包含了在社交网站 Polyvore 上的 21799 套搭配,这里采用作者提供的分割好的训练集、验证集和测试集,分别是 17316,1407 和 3076 套搭配;
Polyvore-Outfits:这个比上个数据集更大一些,包含了 53306 套搭配的训练集和 10000 套搭配的测试集,5000 套搭配的验证集,同样来自 Polyvore 网站,但和 Maryland-Polyvore 不同的是,该数据集还包含了衣服类别标签和相关文本描述的标注信息;
UT-Zappos50k:这是一个包含 50000 张鞋子图片的数据集,同时还有一些标注信息,这里采用论文《Conditional similarity networks》提供的基于四个不同条件进行采样得到的三元组,包括鞋子类型、鞋子性别、鞋跟高度以及鞋子闭合机制。因此每种特性分别得到的三元组数量是训练集20 万组、验证集 2 万组以及测试集4 万组,不过在训练本文的模型的时候,将来自同个特征的三元组都聚集到一个单独的训练集中。
对于两个 Polyvore 数据集,采用一个 Resnet18 作为提取图片特征的网络模型,然后 embedding 大小是 64。对于文本描述的表示方法,这里采用了word2vec 的 HGLMM 费舍尔向量(fisher vector),并用 PCA 降维到 6000。另外,还增加了两个 loss,VSE 和 Sim,分别表示:
所以,最终的 loss 如下所示:
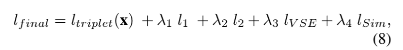
对于第三个数据集,因为采用三元组的输入,所以输入到条件权重分支的输入如下所示:
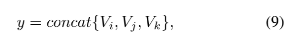
分别对应输入图片 ${x_i, x_j, x_k}$ 。
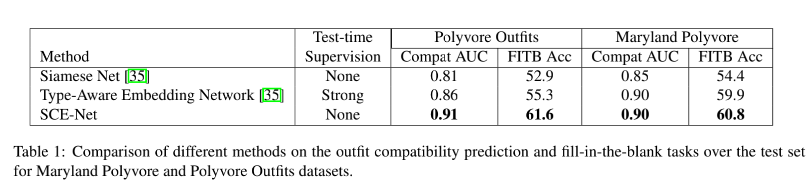
对于在两个 Polyvore 数据集上的实验结果,如下所示,对比的方法是 Siamese 网络和 Type-Aware Embedding 网络模型:
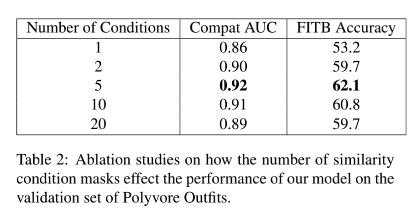
使用的条件数量的实验,如下所示,看到对于 Polyvore 数据集,当只用 5 个条件的时候,模型性能最佳。
标签:pos attention with The 子类 strong 降维 概念 att
原文地址:https://www.cnblogs.com/cai-study-ai-cv/p/14670409.html