标签:rdd ima http rds art lookup rtb nump 统计
一、词频统计:
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
lines.foreach(print)

words=lines.flatMap(lambda line:line.split())
words.foreach(print)
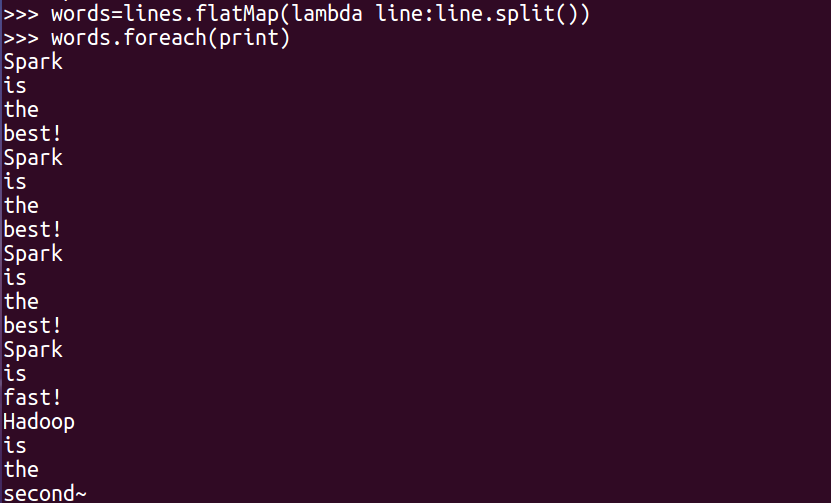
words1=lines.map(lambda word:word.lower())
words1.foreach(print)
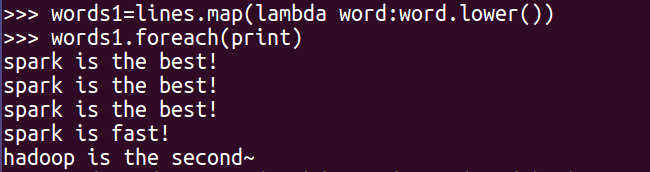
word=words.filter(lambda words:len(words)>2)
words.foreach(print)
with open("/usr/local/spark/mycode/rdd/stopwords.txt") as f:
stops=f.read().split()
lines.flatMap(lambda line:line.split()).filter(lambda word:word not in stops).collect()

words.map(lambda word:(word,1)).collect()

words.map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).collect()

words.map(lambda word : (word,1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[0]).collect()

words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[1],False).collect()

二、学生课程分数案例
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/chapter4-data01.txt")
lines.map(lambda line:line.split(‘,‘)[0]).distinct().count()

lines.map(lambda line:line.split(‘,‘)[1]).distinct().count()

name = lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[0],(line[1],line[2])))

name.take(5)

name.count()

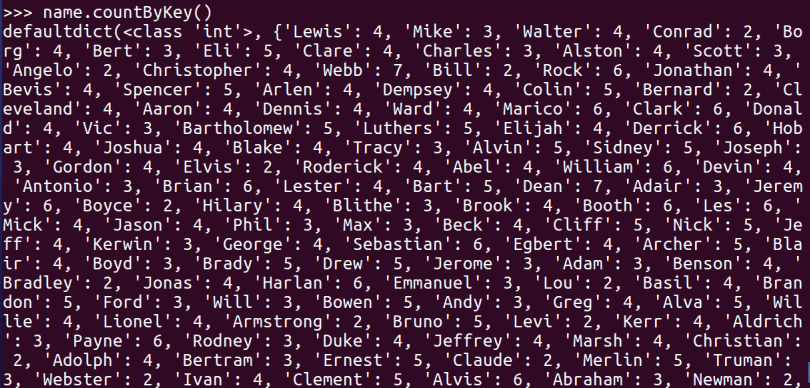
name.countByKey()
name=lines.map(lambda line:line.split(‘,‘)).map(lambda line:line[1])
name.countByValue()

Tom=lines.filter(lambda line:‘Tom‘ in line).map(lambda line:line.split(‘,‘))
Tom.collect()

lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[0],line[2])).lookup(‘Tom‘)

Tom.sortBy(lambda word:word[2],False).collect()

from numpy import mean
tomList=lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[0],line[2])).lookup(‘Tom‘)
mean([int(x) for x in tomList])

标签:rdd ima http rds art lookup rtb nump 统计
原文地址:https://www.cnblogs.com/DongDongQiangg/p/14667936.html