标签:这一 优秀 ons 原因 lazy 单引号 tail 额外信息 设计
查询语句写的很不好;
索引失效
select * from user where name=‘‘;
create index idx_user_name on user(name);
select * from user where name=‘‘ and password=‘‘;
create index idx_user_name on user(name, password);
关联查询太多的join(设计缺陷或不得已的需求)
服务器调优及各个参数的设置(缓冲、线程数等)
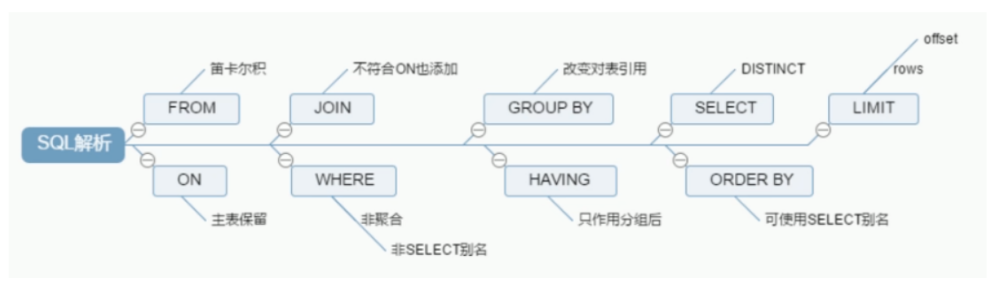
手写的顺序:
SELECT DISTINCT
<select_list>
FROM
<left_table> <join_type>
JOIN
<right_table>
ON
<join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT
<limit_number>
机器读取的顺序:
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
总结:
官方定义:索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。
可以简单理解为“排好序的快速查找数据结构”。
优势
类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本。
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的(占空间)
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。()
索引只是提高效率的一个因素,如果你的MysQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询。
总结:索引就是拿空间换时间
MySQL索引分类:
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
唯一索引:索引列的值必须唯一,但允许有空值。
复合索引:即一个索引包含多个列。
基本语法:
B树:
表记录太少
经常增删改的表
数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率天约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。一个索引的选择性越接近于1,这个索引的效率就越高。
作用:

id
三种情况:
select_type
select_type:查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
select_type有哪些?
table
table:显示这一行的数据是关于哪张表的。
type
访问类型排列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys
显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段火若存在索引,则该索引将被列出,但不一定被查询实际使用。
key
实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引仅出现在key列表中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
extra
包含不适合在其他列中显示但十分重要的额外信息。
原文链接:https://blog.csdn.net/u011863024/article/details/115470147
标签:这一 优秀 ons 原因 lazy 单引号 tail 额外信息 设计
原文地址:https://www.cnblogs.com/yuangaopan/p/14672619.html