标签:pil 实现 构建 ali 一个 save 获取 _id 表达式
利用tensorflow2自带keras搭建BiLSTM+CRF的序列标注模型,完成中文的命名实体识别任务。这里使用数据集是提前处理过的,已经转成命名实体识别需要的“BIO”标注格式。
详细代码和数据:https://github.com/huanghao128/zh-nlp-demo
BiLSTM+CRF模型就是在双向LSTM模型的输出位置接上一个CRF层,这样可以学习到相邻输出之间的依赖关系,从而提高输出标签的整理准确率,模型结构图如下图:
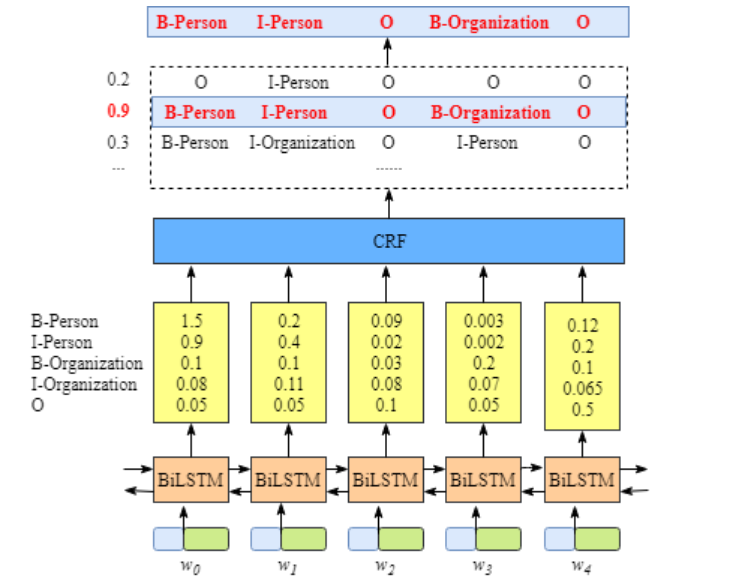
本文使用的数据是已经预处理过的,所以直接加载数据就好了,首先我们要加载字符词典文件,还有BIO标记类别的索引化。其中BIO标记中B-PER和I-PER表示人名,B-LOC和I-LOC表示地名,B-ORG和I-ORG表示机构名。
char_vocab_path = "./data/char_vocabs.txt" # 字典文件
train_data_path = "./data/train_data" # 训练数据
test_data_path = "./data/test_data" # 测试数据
special_words = [‘<PAD>‘, ‘<UNK>‘] # 特殊词表示
# "BIO"标记的标签
label2idx = {"O": 0,
"B-PER": 1, "I-PER": 2,
"B-LOC": 3, "I-LOC": 4,
"B-ORG": 5, "I-ORG": 6
}
# 索引和BIO标签对应
idx2label = {idx: label for label, idx in label2idx.items()}
# 读取字符词典文件
with open(char_vocab_path, "r", encoding="utf8") as fo:
char_vocabs = [line.strip() for line in fo]
char_vocabs = special_words + char_vocabs
# 字符和索引编号对应
idx2vocab = {idx: char for idx, char in enumerate(char_vocabs)}
vocab2idx = {char: idx for idx, char in idx2vocab.items()}
然后加载训练和测试集,并把原始数据和BIO标记转成索引和类别编号。
# 读取数据集语料
def read_corpus(corpus_path, vocab2idx, label2idx):
datas, labels = [], []
with open(corpus_path, encoding=‘utf-8‘) as fr:
lines = fr.readlines()
sent_, tag_ = [], []
for line in lines:
if line != ‘\n‘:
char, label = line.strip().split()
sent_.append(char)
tag_.append(label)
else:
sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx[‘<UNK>‘] for char in sent_]
tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]
datas.append(sent_ids)
labels.append(tag_ids)
sent_, tag_ = [], []
return datas, labels
# 加载训练集
train_datas, train_labels = read_corpus(train_data_path, vocab2idx, label2idx)
# 加载测试集
test_datas, test_labels = read_corpus(test_data_path, vocab2idx, label2idx)
数据的填充,以及类别的one-hot编码。
from tensorflow import keras
from keras.preprocessing import sequence
import numpy as np
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
# padding data
train_datas = sequence.pad_sequences(train_datas, maxlen=MAX_LEN)
train_labels = sequence.pad_sequences(train_labels, maxlen=MAX_LEN)
test_datas = sequence.pad_sequences(test_datas, maxlen=MAX_LEN)
test_labels = sequence.pad_sequences(test_labels, maxlen=MAX_LEN)
print(‘x_train shape:‘, train_datas.shape)
print(‘x_test shape:‘, test_datas.shape)
# encoder one-hot
train_labels = keras.utils.to_categorical(train_labels, CLASS_NUMS)
test_labels = keras.utils.to_categorical(test_labels, CLASS_NUMS)
print(‘trainlabels shape:‘, train_labels.shape)
print(‘testlabels shape:‘, test_labels.shape)
模型构建主要使用keras自带的基础模型组装,首先是双向LSTM模型,然后输出接CRF模型,输出对每个时刻的分类。
from tensorflow import keras
from tensorflow.keras import layers, models
from tensorflow.keras import backend as K
class CRF(layers.Layer):
def __init__(self, label_size):
super(CRF, self).__init__()
self.trans_params = tf.Variable(
tf.random.uniform(shape=(label_size, label_size)), name="transition")
@tf.function
def call(self, inputs, labels, seq_lens):
log_likelihood, self.trans_params = tfa.text.crf_log_likelihood(
inputs, labels, seq_lens,
transition_params=self.trans_params)
loss = tf.reduce_sum(-log_likelihood)
return loss
EPOCHS = 20
BATCH_SIZE = 64
EMBED_DIM = 128
HIDDEN_SIZE = 64
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
inputs = layers.Input(shape=(MAX_LEN,), name=‘input_ids‘, dtype=‘int32‘)
targets = layers.Input(shape=(MAX_LEN,), name=‘target_ids‘, dtype=‘int32‘)
seq_lens = layers.Input(shape=(), name=‘input_lens‘, dtype=‘int32‘)
x = layers.Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_DIM, mask_zero=True)(inputs)
x = layers.Bidirectional(layers.LSTM(HIDDEN_SIZE, return_sequences=True))(x)
logits = layers.Dense(CLASS_NUMS)(x)
loss = CRF(label_size=CLASS_NUMS)(logits, targets, seq_lens)
model = models.Model(inputs=[inputs, targets, seq_lens], outputs=loss)
print(model.summary())

由于构建模型时,输出对应的是loss,所以loss定义需要进行一些修改。
class CustomLoss(keras.losses.Loss):
def call(self, y_true, y_pred):
loss, pred = y_pred
return loss
# 自定义Loss
# model.compile(loss=CustomLoss(), optimizer=‘adam‘)
# 或者使用lambda表达式
model.compile(loss=lambda y_true, y_pred: y_pred, optimizer=‘adam‘)
# 训练
model.fit(x=[train_datas, train_labels, train_seq_lens], y=labels,
validation_split=0.1, batch_size=BATCH_SIZE, epochs=EPOCHS)
# 保存
model.save("output/bilstm_crf_ner")
结果预测是我们训练好模型后,重新加载模型,输入新的要预测文本,然后识别出文本中的命名实体。这里首先要加载字符词典,然后加载模型,之后对输入文本预处理成字符序列,然后模型预测每个时刻的输出类别,最后把类别转成BIO标记,BIO标记组合成正确的命名实体。
# 加载模型
model = models.load_model("output/bilstm_crf_ner", compile=False)
# 如果需要继续训练,需要下面的重新compile
# model.compile(loss=lambda y_true, y_pred: y_pred, optimizer=‘adam‘)
分别提取转移矩阵参数和BiLSTM的输出
# 提取转移矩阵参数
trans_params = model.get_layer(‘crf‘).get_weights()[0]
# 获得BiLSTM的输出logits
sub_model = models.Model(inputs=model.get_layer(‘input_ids‘).input,
outputs=model.get_layer(‘dense‘).output)
def predict(model, inputs, input_lens):
logits = sub_model.predict(inputs)
# 获取CRF层的转移矩阵
# crf_decode:viterbi解码获得结果
pred_seq, viterbi_score = tfa.text.crf_decode(logits, trans_params, input_lens)
return pred_seq
测试预测数据
maxlen = 100
sentence = "这里输入是需要实体识别的句子"
sent_chars = list(sentence)
sent2id = [vocab2idx[word] if word in vocab2idx else vocab2idx[‘<UNK>‘] for word in sent_chars]
sent2id_new = np.array([[0] * (maxlen-len(sent2id)) + sent2id[:maxlen]])
test_lens = np.array([100])
pred_seq = predict(model, sent2id_new, test_lens)
print(pred_seq)
对预测结果进行命名实体解析和提取
def get_valid_nertag(input_data, result_tags):
result_words = []
start, end =0, 1 # 实体开始结束位置标识
tag_label = "O" # 实体类型标识
for i, tag in enumerate(result_tags):
if tag.startswith("B"):
if tag_label != "O": # 当前实体tag之前有其他实体
result_words.append((input_data[start: end], tag_label)) # 获取实体
tag_label = tag.split("-")[1] # 获取当前实体类型
start, end = i, i+1 # 开始和结束位置变更
elif tag.startswith("I"):
temp_label = tag.split("-")[1]
if temp_label == tag_label: # 当前实体tag是之前实体的一部分
end += 1 # 结束位置end扩展
elif tag == "O":
if tag_label != "O": # 当前位置非实体 但是之前有实体
result_words.append((input_data[start: end], tag_label)) # 获取实体
tag_label = "O" # 实体类型置"O"
start, end = i, i+1 # 开始和结束位置变更
if tag_label != "O": # 最后结尾还有实体
result_words.append((input_data[start: end], tag_label)) # 获取结尾的实体
return result_words
详细代码和数据:https://github.com/huanghao128/zh-nlp-demo
Tensorflow2+keras实现BiLSTM+CRF中文命名实体识别
标签:pil 实现 构建 ali 一个 save 获取 _id 表达式
原文地址:https://www.cnblogs.com/huanghaocs/p/14673020.html