标签:继承 mime ror 请求 bsp serve 不同 重写 默认值
Nginx
负载均衡
nginx的原理
Nginx 采用的是多进程(单线程) & 多路IO复用模型
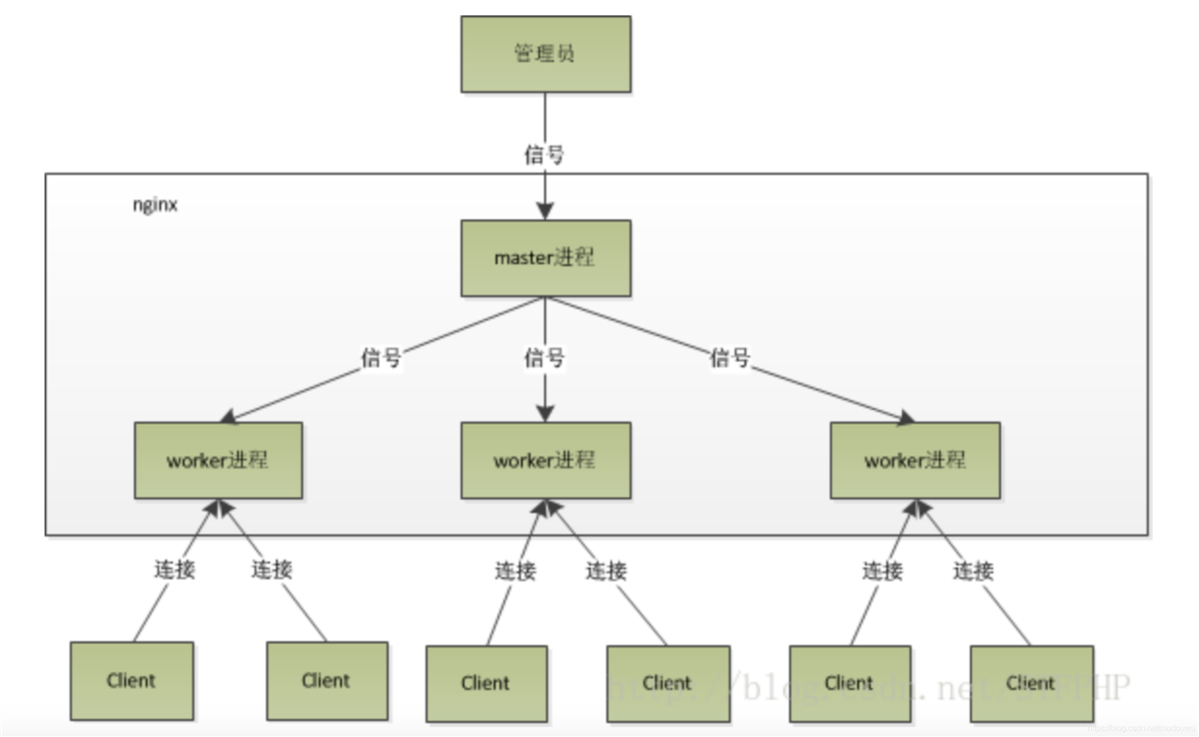
1、Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程
2、master进程接收来自外界的信号,向各worker进程发送信号,每个进程都有可能来处理这个连接
3、 master 进程能监控 worker 进程的运行状态,当 worker 进程退出后(异常情况下),会自动启动新的 worker 进程
worker 进程数,一般会设置成机器 cpu 核数。因为更多的worker 数,只会导致进程相互竞争 cpu,从而带来不必要的上下文切换
使用多进程模式,不仅能提高并发率,而且进程之间相互独立,一个 worker 进程挂了不会影响到其他 worker 进程
Nginx进程详解
Nginx在启动后,会有一个master进程和多个worker进程
master进程
主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程
master进程充当整个进程组与用户的交互接口,同时对进程进行监护。它不需要处理网络事件,不负责业务的执行,只会通过管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能
worker进程
基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。
当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了
Nginx 是如何实现高并发
异步,非阻塞,使用了epoll 和大量的底层代码优化
Nginx 的异步非阻塞工作方式把当中的等待时间利用起来了。在需要等待的时候,这些进程就空闲出来待命了,因此表现为少数几个进程就解决了大量的并发问题。
每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker很聪明,他会在发送完请求后,注册一个事件:“如果upstream返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走
这样,基于 多进程+epoll, Nginx 便能实现高并发
nginx的负载均衡策略
轮询 默认方式
weight 权重方式
ip_hash 依据ip分配方式
least_conn 最少连接方式
惊群现象
主进程(master 进程)首先通过 socket() 来创建一个 sock 文件描述符用来监听,然后fork生成子进程(workers 进程),子进程将继承父进程的 sockfd(socket 文件描述符),之后子进程 accept() 后将创建已连接描述符(connected descriptor)),然后通过已连接描述符来与客户端通信。
那么,由于所有子进程都继承了父进程的 sockfd,那么当连接进来时,所有子进程都将收到通知并“争着”与它建立连接,这就叫“惊群现象”。大量的进程被激活又挂起,只有一个进程可以accept() 到这个连接,这当然会消耗系统资源
Nginx对惊群现象的处理
Nginx 提供了一个 accept_mutex 这个东西,这是一个加在accept上的一把共享锁。即每个 worker 进程在执行 accept 之前都需要先获取锁,获取不到就放弃执行 accept()。有了这把锁之后,同一时刻,就只会有一个进程去 accpet(),这样就不会有惊群问题了。accept_mutex 是一个可控选项,我们可以显示地关掉,默认是打开的
nginx配置
ningx.conf配置文件示例
#user administrator administrators; #配置用户或者组,默认为nobody nobody。
#worker_processes 2; #允许生成的进程数,默认为1
#pid /nginx/pid/nginx.pid; #指定nginx进程运行文件存放地址
error_log log/error.log debug; #制定日志路径,级别。这个设置可以放入全局块,http块,server块,级别以此为:debug|info|notice|warn|error|crit|alert|emerg
events {
accept_mutex on; #设置网路连接序列化,防止惊群现象发生,默认为on
multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off
#use epoll; #事件驱动模型,select|poll|kqueue|epoll|resig|/dev/poll|eventport
worker_connections 1024; #最大连接数,默认为512
}
http {
include mime.types; #文件扩展名与文件类型映射表
default_type application/octet-stream; #默认文件类型,默认为text/plain
#access_log off; #取消服务日志
log_format myFormat ‘$remote_addr–$remote_user [$time_local] $request $status $body_bytes_sent $http_referer $http_user_agent $http_x_forwarded_for‘; #自定义格式
access_log log/access.log myFormat; #combined为日志格式的默认值
sendfile on; #允许sendfile方式传输文件,默认为off,可以在http块,server块,location块。
sendfile_max_chunk 100k; #每个进程每次调用传输数量不能大于设定的值,默认为0,即不设上限。
keepalive_timeout 65; #连接超时时间,默认为75s,可以在http,server,location块。
upstream mysvr {
server 127.0.0.1:7878;
server 192.168.10.121:3333 backup; #热备
}
error_page 404 https://www.baidu.com; #错误页
server {
keepalive_requests 120; #单连接请求上限次数。
listen 4545; #监听端口
server_name 127.0.0.1; #监听地址
location ~*^.+$ { #请求的url过滤,正则匹配,~为区分大小写,~*为不区分大小写。
#root path; #根目录
#index vv.txt; #设置默认页
proxy_pass http://mysvr; #请求转向mysvr 定义的服务器列表
deny 127.0.0.1; #拒绝的ip
allow 172.18.5.54; #允许的ip
}
}
}
location匹配
把匹配到的url,可以通过proxy_pass等操作,截断发给其他ip地址如本机等等
语法
location [ = | ~ | * | ^ ] uri { … }
= :精确匹配(必须全部相等)
~ :大小写敏感
*:忽略大小写
^ :只需匹配uri部分
@ :内部服务跳转
=,精确匹配
location = / {
#规则
}
则匹配到 http://www.example.com/ 这种请求。
~,大小写敏感
location ~ /Example/ {
#规则
}
#请求示例
#http://www.example.com/Example/ [成功]
#http://www.example.com/example/ [失败]
~*,大小写忽略
location ~* /Example/ {
#规则
}
# 则会忽略 uri 部分的大小写
#http://www.example.com/Example/ [成功]
#http://www.example.com/example/ [成功]
^~,只匹配以 uri 开头
location ^~ /img/ {
#规则
}
#以 /img/ 开头的请求,都会匹配上
#http://www.example.com/img/a.jpg [成功]
#http://www.example.com/img/b.mp4 [成功]
@,nginx内部跳转
location /img/ {
error_page 404 @img_err;
}
location @img_err {
# 规则
}
#以 /img/ 开头的请求,如果链接的状态为 404。则会匹配到 @img_err 这条规则上。
rewrite 重写url
用法
Rewrite( URL 重写)指令可以出现在 server{} 下,也可以出现在 location{} 下。对于出现在 server{} 下的 rewrite 指令,它的执行会在 location 匹配之前;对于出现在 location{} 下的 rewrite 指令,它的执行当然是在 location 匹配之后,但是由于 rewrite 导致 HTTP 请求的 URI 发生了变化,所以 location{} 下的 rewrite 后的 URI 又需要重新匹配 location ,就好比一个新的 HTTP 请求一样
示例:
location /bbb.html {
rewrite "^/bbb\.html$" /ccc.html;
}
upstream
upstream backend {
sticky; # or simple round-robin
server 172.29.88.226:8080 weight=2;
server 172.29.88.226:8081 weight=1 max_fails=2 fail_timeout=30s ;
server 172.29.88.227:8080 weight=1 max_fails=2 fail_timeout=30s ;
server 172.29.88.227:8081;
check interval=5000 rise=2 fall=3 timeout=1000 type=http;
check_http_send "HEAD / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
server {
location / {
proxy_pass http://backend;
}
location /status {
check_status;
access_log off;
allow 172.29.73.23;
deny all;
}
check指令只能出现在upstream中,可以检查出异常的后端服务器,这样后续就不会把请求转发过去:
interval : 向后端发送的健康检查包的间隔。
fall : 如果连续失败次数达到fall_count,服务器就被认为是down。
rise : 如果连续成功次数达到rise_count,服务器就被认为是up。
timeout : 后端健康请求的超时时间。
type:健康检查包的类型,现在支持以下多种类型
tcp:简单的tcp连接,如果连接成功,就说明后端正常。
http:发送HTTP请求,通过后端的回复包的状态来判断后端是否存活。
ajp:向后端发送AJP协议的Cping包,通过接收Cpong包来判断后端是否存活。
ssl_hello:发送一个初始的SSL hello包并接受服务器的SSL hello包。
mysql: 向mysql服务器连接,通过接收服务器的greeting包来判断后端是否存活。
fastcgi:发送一个fastcgi请求,通过接受解析fastcgi响应来判断后端是否存活
如果 type 为 http ,你还可以使用check_http_send来配置http监控检查包发送的请求内容,为了减少传输数据量,推荐采用 HEAD 方法。当采用长连接进行健康检查时,需在该指令中添加keep-alive请求头,如: HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n 。当采用 GET 方法的情况下,请求uri的size不宜过大,确保可以在1个interval内传输完成,否则会被健康检查模块视为后端服务器或网络异常
check_http_expect_alive指定HTTP回复的成功状态,默认认为 2XX 和 3XX 的状态是健康的
Nginx常见的优化配置
worker_processes
Nginx要生成的worker数量,最佳实践是每个CPU运行1个工作进程
最大化worker_connections
Nginx Web服务器可以同时提供服务的客户端数。与worker_processes结合使用时,获得每秒可以服务的最大客户端数
最大客户端数/秒=工作进程*工作者连接数
为了最大化Nginx的全部潜力,应将工作者连接设置为核心一次可以运行的允许的最大进程数1024
为静态文件启用缓存
为静态文件启用缓存,以减少带宽并提高性能,可以添加下面的命令,限定计算机缓存网页的静态文件
location ~* .(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d;
}
Timeouts
keepalive连接减少了打开和关闭连接所需的CPU和网络开销,获得最佳性能需要调整的变量
access_logs
访问日志记录,它记录每个nginx请求,因此消耗了大量CPU资源,从而降低了nginx性能
proxy_set_header
proxy_set_header用来重定义发往后端服务器的请求头
语法格式:
proxy_set_header Field Value;
Value值可以是包含文本、变量或者它们的组合。常见的设置如:
proxy_set_header Host $proxy_host; 请求头会被重新定义为新的转发地址的host
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $ host;它的值在请求包含“Host”请求头时为“Host”字段的值。相当于$http_host,在请求未携带“Host”请求头时为虚拟主机的主域名
proxy_set_header Host $http_host; 请求头设置成http的host,并且转发之后不会更改
案例
问题:nginx上配有aaa.example.com的虚拟主机,现在需要将访问http://aaa.example.com/api/x.x/client/ 的请求转到 http://bbb.example.com/api/x.x/client/,bbb.example.com 的虚拟主机在另外一台nginx上
于是添加配置
location ~ ^/api/([0-9]+)(\.[0-9]+)*/client/ {
proxy_pass http://bbb.example.com;
}
然而却报404.
解决方案:
location ~ ^/api/([0-9]+)(\.[0-9]+)*/client/ {
proxy_pass http://bbb.example.com;
proxy_set_header Host $proxy_host;
}
原因:
发现在nigxn文件里配置了proxy_set_header Host h t t p h o s t ; , 当 H o s t 设 置 为 http_host ;,当Host设置为http
h
?
ost;,当Host设置为http_host时,则不改变请求头的值,所以当要转发到bbb.example.com的时候,请求头还是aaa.example.com的Host信息,就会有问题;当Host设置为$proxy_host时,则会重新设置请求头为bbb.example.com的Host信息
常用命令
启动nginx ./sbin/nginx
停止nginx ./sbin/nginx -s stop ./sbin/nginx -s quit
重载配置 ./sbin/nginx -s reload(平滑重启) service nginx reload
检查配置文件是否正确 ./sbin/nginx -t
nginx中 $1,$2,$3是什么 ?$1表示路径中正则表达式匹配的第一个参数
参考博客:http://www.ha97.com/5194.html
Epoll
参考
select
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int fds[] = 存放需要监听的socket
while(1){
int n = select(..., fds, ...)
for(int i=0; i < fds.count; i++){
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理
}
}
}
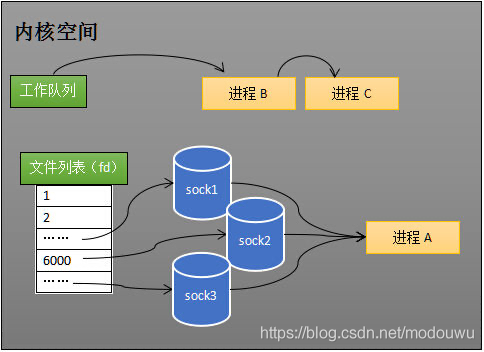
程序同时监视如下图的sock1、sock2和sock3三个socket,那么在调用select之后,操作系统把进程A分别加入这三个socket的等待队列中。当任何一个socket收到数据后,中断程序将唤起进程。
当进程A被唤醒后,将进程从所有的等待队列中移除,加入到工作队列里面。它知道至少有一个socket接收了数据。程序只需遍历一遍socket列表,就可以得到就绪的socket
epoll
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1){
int n = epoll_wait(...)
for(接收到数据的socket){
//处理
}
}
内核有一个eventpoll对象,和socket一样,它内部也有等待队列。当添加对一个socker的的监视时,内核将eventpoll对象引用放入socket的等待队列,进程对象加入eventpoll对象的等待队列中
当socker接收到数据后,中断程序一方面会给eventpoll的就绪队列rdlist添加“socket”引用,另一方面唤醒eventpoll等待队列中的进程,进程A再次进入运行状态(如下图)。也因为rdlist的存在,进程A可以知道哪些socket发生了变化
eventpoll对象相当于是socket和进程之间的中介,socket的数据接收并不直接影响进程,而是通过改变eventpoll的就绪列表来改变进程状态
Redis
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,但是请求每次都会打到数据库上面去
这种查询不存在数据的现象我们称为缓存穿透
解决方法
缓存空值、并设置过期时间
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
缓存击穿
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿
会造成某一时刻数据库请求量过大,压力剧增
解决方法
设置热点数据永远不过期
加互斥锁
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
解决方法
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
设置热点数据永远不过期
redis为什么快
纯内存操作
单线程操作,避免了频繁的上下文切换
采用了非阻塞I/O多路复用机制
Redis如何做持久化的
rdb(bgsave)做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态
redis集群
同步机制
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程## 架构原理
一致性
可以参考
网络
三次握手和四次挥手
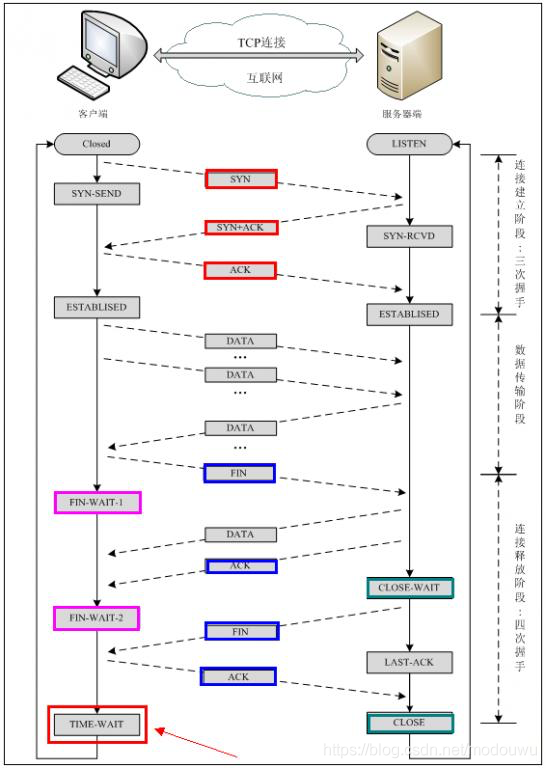
首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,“告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,“告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,“就知道可以断开连接了”。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了
标签:继承 mime ror 请求 bsp serve 不同 重写 默认值
原文地址:https://www.cnblogs.com/wangbin/p/14681742.html