“A/B测试不一定是最好的评估方法。它不是万能的,但不会A/B测试肯定是不行的。”4月20日,首个火山引擎技术开放日在北京方恒时尚中心举办,字节跳动技术负责人杨震原以《聊聊数据驱动和用A/B测试解决问题》为题,分享了他对于A/B测试的理解。杨震原称,A/B测试是字节跳动一项非常基础的工具,从公司成立之初就在使用,支撑了抖音、今日头条等产品的增长迭代。目前,字节跳动A/B测试每日新增1500+实验,服务于400多项大大小小的业务,累计做了70多万次实验。这项工具已经实现产品化,通过火山引擎向企业客户开放。A/B测试广泛应用于字节跳动方方面面,包括产品命名、交互设计、推荐算法等。但杨震原表示,这项工具也存在很多应用局限,比如独立性、置信度、长短期等问题。杨震原透露,抖音产品名字,其实是综合了A/B测试和人为判断的结果,“‘抖音’这个名字在测试结果中排名第二。但大家觉得,这个名字更符合认知,更能体现它的形态,所以还是选了它。”

杨震原在火山引擎技术开放日现场
以下为杨震原演讲全文:大家好,我叫杨震原。非常高兴在火山引擎技术开放日上和大家交流分享,希望对大家有所帮助。
字节跳动做了很多产品,我们希望技术团队对待自家产品就像对待客户一样。我们不仅有内部客户,像抖音、今日头条,也希望有更多外部客户,把我们的技术能力输出,于是就有了火山引擎品牌。火山引擎技术开放日也是这个目的,希望把我们的技术对外,跟更多朋友分享交流。当然,也有点私心,希望我们的产品能卖到更多地方去。
今天我们聊的话题是“数据驱动和用A/B测试解决问题”。这里的关键词是“解决问题、数据驱动、A/B测试”。解决问题一定要有好的方法,每个人都想用更好的方法解决问题,这涉及用什么方法,达成什么目标。“数据驱动”是我们公司内非常看重的一系列方法,“A/B测试”是“数据驱动”中的一个具体方法。
 用户画像和使用时长不是好的目标
用户画像和使用时长不是好的目标要想解决问题,第一个问题是:目标是什么?很多人觉得:这个很简单啊!目标嘛,今天想干一个什么事情,我就确定一个目标,接下来就是照着这个目标去完成。但是,确认目标,以及这个目标是否可量化,其实是特别重要的。
我给大家举几个例子。我大概2014年初来到字节跳动。刚来时,张一鸣说把我们的推荐质量提升提升,想想办法怎么做改进。所以,当时我的目标就是提升今日头条产品的用户体验,把推荐做得更好。
很快我发现,这方面其实已经有很多项目在做了,其中有一个子方向的目标是“全面、精准的用户画像体系”。但在我看来,这个目标其实有很多问题。
我们的实际目标是“提升推荐的用户体验”。我们有很多方法来达成目标,用户画像只是方法之一。它是个子目标,不是我们要解决的目标,甚至可能都不是重要的方法。即使假设这个目标就是我们的主要目标,我们也还要评估它是不是可衡量的。
如何评估这一点非常难,比如衡量用户画像是不是好,很难量化。用户的实际兴趣是什么,很难评估。问用户喜欢不喜欢旅游,一般人都说喜欢,但是推荐旅游相关文章看不看?实际上很多人都不看。
因此,
用户画像不是一个好的目标。首先,这个目标优先级不一定高,其次,它的评估非常难,这就意味着,这个目标很难指导我们的具体工作。还有一种常用目标,叫“使用时长”。A做了一个算法,平均使用时长40分钟,B做的算法,平均使用时长45分钟,那是不是B就比A好?这个听起来似乎很科学。
但是我要跟大家讲一个例子。大概在2016年,有一个传统老牌外企,它在美国的PC端有一款产品是新闻推荐。这个公司在中国有一个研究所,其中一项工作是去提高新闻推荐质量,采用的评估标准是用户使用时长。对于用户在平台上阅读了多少时长,这个研究所每个季度都有KPI,连续几年他们每年都能完成目标,并且经常超额完成。但后来我跟他们聊的时候,这个研究所快要解散了。
原来,虽然使用时长在增加,但这个产品的用户规模其实是不好的,用户体验也不够理想,整个产品的留存在下降。我问他们,为什么你们的时长一直在涨,但是你们产品却不行了?对方说:时长是在涨,但时长增长有两种方式,一种是用户体验变好了、用户看的时间更长了;还有一种方式是用着很好的用户继续留下来了,而一些时长很短的用户看了看觉得这个产品不好,就走了。这些用户走了以后,平均时长继续变长。于是就变成了“不断驱赶体验差的用户,平均时长却变长了”这样一个过程。
这是很可怕的,看起来是个很好的目标,但却把产品做死了。可以预见,如果我们只用使用时长作为目标的话,是有风险的。
那怎么办呢?
我们也没有大招,只能是尽量将多个目标综合。既要考虑用户体验,也要考虑一些客观指标,同时可能辅以一些用户访谈的直观印象,最后综合去制定我们的方向。 好的目标层次合理、可衡量
好的目标层次合理、可衡量如何选一个合适的目标?我觉得至少有两个角度,需要去考虑。
第一个角度,目标层次合理性。
什么叫“层次合理性”?比如你是一家公司的首席技术官(CTO),CEO问你公司的技术目标是什么,你说“我要让我们的公司市值做得更大,原来估值5亿美元,10年之后估值50亿美元”。这个目标很泛、很高层次,跟最终目标很接近。通常大家也不会质疑说这个目标有错误。但是这个目标就不太能指导你的工作。CTO下面的总监、经理、工程师这个季度该干什么呢?这个目标能有些推导分解吗?很难。虽然目标层次很高,不容易偏离,但是对具体工作很难有指导。
那我们定非常具体的目标可以吗?比如像刚才的例子,以使用时长为目标。这种时候,会有另一个问题:这个目标很具体、很能指导工作,但是它偏离了怎么办?还有一个可能出现的问题是,这个目标没有偏离,但不可衡量,它不利于指导工作。
所以,
应该选一个不要太高、不要太低的目标,并且定期衡量特别重要。聊数据驱动思路时,当试图用数据驱动思路去细化目标时,有利于你仔细反思:我的目标是不是这个?我的目标能不能量化?它会逼你把目标想得很清楚。
第二个角度,目标可衡量。这一点特别重要。它跟数据驱动的理念互相帮助,定好目标,才能更好的应用数据驱动,当你用数据驱动的方法去做事情时,它就会push你的目标到底是不是合理。比如你想了想这个目标:哦,之前的目标就定错了,怪不得搞不清楚。
 什么是靠谱的评估方法?
什么是靠谱的评估方法?当目标想清楚了,那我们就评估吧。通常我们有哪些方法?
一是经验判断。不管什么公司,每天都在不停的用这个方法,这个方法非常靠谱的,但是有它的问题。
二是非A/B测试的数据分析。
三是A/B测试的数据分析。我特别把A/B测试和非A/B测试区分了一下,因为它是一个更接近真实、更能够把握住本质的一个方法。相信很多朋友都了解因果推断,做精准的A/B测试能够把因果说得更清楚,所以是更有效的方法。

经验判断是什么?本质上是就靠人,这个方法是普遍采用的。举个例子,大家都知道我们公司在做短视频,怎么评估质量好坏?很多时候都靠人去判断,如果你用客观指标判断它,会有另外的风险,所以很多时候用人判断。在很多公司,比如战略决策通常是人判断的,很难靠数据定你的战略方向,这是一个很重要的方法。
但它的问题在于:执行层面很容易不一致,尤其对一个很大的公司来说,每天要决策的事情很多,并不是每个决策都由CEO或者高管来做,可能会分到公司很多团队很多部门,每个部门都有很多人,这些人在他们的点上去做希望对公司正确的决策,但他们的意见有可能是不一致的。而且每个人可能有每个人的偏好,这是很难避免的。尤其公司比较大的时候,就会带来非常多风险,比如不一致性和有偏性。
非A/B测试的数据分析。这个主要想强调关联跟因果的问题,我们来举个例子就很容易看到。暑假前,运营团队做了一波活动,声势非常浩大,到了暑假开始的时候,发现用户的活跃度大幅上升,这个提升是我们的运营活动带来的吗?二者是有关联的,但是关联并不代表因果。很明显,暑假就是一个因素,暑假带来的变化跟运营活动带来的变化,到底谁更大?这个事情很难归因的。每个人都觉得自己做的事情有用,关联分析中往往就会带有偏见。
我们再举个有趣的例子,诺贝尔奖和巧克力消费量的关系图。图片显示,巧克力吃得越多的国家,诺贝尔奖得主就越多。如果想改进中国的科技水平,多拿诺贝尔奖,我们应该多吃巧克力吗?这显然不靠谱。可能会变胖,但很难拿到诺贝尔奖。
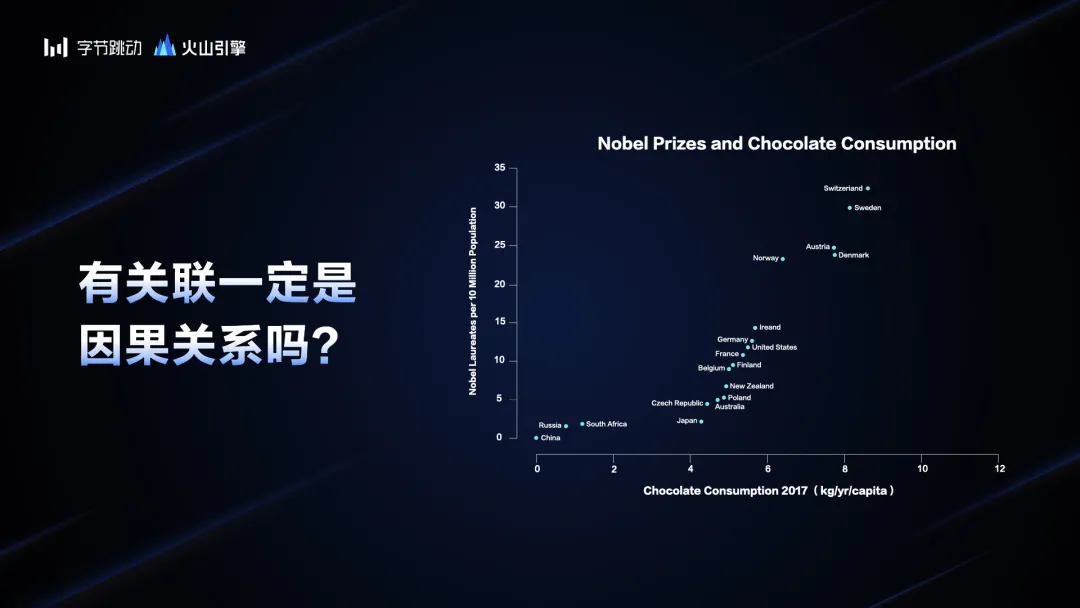
这可以说明一件事情,这两个事件有关联性,但是它不是因果性。从数据分析中得出结论,就会面临很多这样的风险,它会混淆关联性和因果性,并不能解决问题。
真正的完美解决方案是什么?得靠平行宇宙了。当前时空是这个状态,做了一波A操作,比如一些同事搞了一波活动,时间退回去,他没有做这个事情。我们再回过头来看这两个平行宇宙的差别是什么,这个差别就是这个活动所带来的,这个很好理解。但是我们没办法做平行宇宙的实验,就只能做A/B测试了。
怎么做A/B测试?当我们想观测某个方面,比如说人群或者某类产品,就把人群和产品分成A、B两组,比如你的操作是发红包,或者改了设计页面,又或者是做了运营活动。除了这些操作之外,其他的分布完全一样。当然了,这件事情只能无限逼近,不能做到理论上完全一样,除非是平行宇宙。
A/B测试看上去好像效率很低,非常复杂,要分组,还要看因素是不是剥离干净了。但是当你真正把一个事情搞清楚以后,就可以一个台阶一个台阶往上走。如果你搞不清楚,做得很快,有可能今天上一个台阶,明天下一个台阶,后天上一个台阶,不能保证一直在前进,这是非常大的差别。
字节跳动的A/B测试实践早期有记载的A/B测试,是在1747年,詹姆斯·林德治疗坏血病的临床实验。他们把患有坏血病的水手分成6组,每组2个人。在6天的时间内,他们把大家安排在同样的治疗室中,吃同样的食物,尽量排除实验的干扰。这个人群选择也很重要,我们应该选择各种年龄段的,各种国家地区的。这里没有写,没有足够的数量,这是它不严谨的地方。唯一的不同是每组的治疗方案,吃什么东西?柠檬、橘子、苹果汁、醋、海水等等。最后的实验结果是柠檬/橘子、苹果汁有用。
在此之前有很多玄学,这个病,有人说用这个方法有用,用那个方法有用,有的是碰上了,有的是有效了。这个实验虽然不够严谨,还可以做得更好,但是它真正确定了什么原因。当你非常确信这个结论时,就可以继续深入研究,比如从这个食物中分离出它所必要的真正有效物质是什么。在很确定结论的基础上不断演化,就能够往后走得很远。
知道了A/B测试的源头后,现在说下字节跳动做的A/B测试实践。

2012年公司成立,那时候我还没来。听说那会儿一鸣还在自己写代码,已经开始做A/B测试。
我大概是2014年来的,发现公司已经非常重视这方面。这跟我的理念非常像,我也在继续推动这件事情。比如定目标,推动A/B测试的平台化,让它更严谨,以及发现它的问题,在公司中更广泛地使用。
到2016年,已经变成一个内部广泛使用的平台了,叫Libra平台,它有很多的功能。到2019年时,我们已经不只是内部平台了,正式立项,开始做对外平台,给外部更多客户来用我们的产品。
内部来说,我们用A/B测试确实很多,现在每天大概新增1500个实验,服务了400多项业务,累计已经做了70万次实验。

应用在哪些方面呢?产品命名、交互设计,比如改一个字体、一个弹窗、界面大小,都会做A/B测试。推荐算法就不说了,从一鸣自己写代码开始,就一直在做了。广告优化,这是业界普遍做法。用户增长,也是这样。市场活动,我们做了一小部分。内部基本上就是,能用A/B测试的都用。
A/B测试不是万能的那A/B测试是不是就一统天下了呢?显然也不是。A/B测试不一定是最好的评估方法,它不是万能的,但是我觉得,不会A/B测试肯定是不行的。
为什么说它不一定是最好的评估方法?我们说说它的一些局限和问题。
首先是独立性的问题。如果你真的想做A/B测试,就要对你的实验对象进行分组,分组之后,去做一个操作,观测结果。这个分组要求两组是非常独立,除了你的这个操作之外,其他部分都一样,至少是分布一样。但有时候这点并不容易保证。
举个例子,网约车的司机分配策略,比如这个网约车分配什么司机?谁离你最近,我就分配,这是一个策略。我们还可以考虑价格,以及车型和时间等等,做别的策略。A同学做了A策略,B同学做了B策略,哪个策略更好?

我们可以来做个A/B实验,把用户分成两组,A组是一部分用户,用A策略,B组是另一部分用户,用B策略。但这是有很多问题的。如果只按用户来分,A策略和B策略的用户有可能都用同一个司机,A策略的用户把这个司机订走了,B组的用户就订不到这个司机了。
也就是说,你最后观测到的统计指标,比如成单量、成单率,可能会有交叉影响,但具体是多少?单从这个实验数据来讲,是看不出来的,也不太容易分析,所以它不独立。交叉影响在哪?按用户分了,但是司机没有分开,两波用户有可能会联系到同一个司机,这就叫“独立性问题”。
更严谨的实验怎么做?应该把用户和司机都分开,把用户编个组,司机也编个组,用户司机A组,用户司机B组。
当你发现你要观测的对象不能被严格切分的话,就需要考虑独立性的问题,这时候你做的结论很可能是错的。我们再看一个置信度的问题。比如做搜索评估,我们评估100个随机测试,把它们分成A、B两个测试组,其中有22个变好了,有20个变差了,加起来是42个,剩下的58个两边一样。
请问,A组是比B组变好了吗?有人说,系统变好10%,效果非常明显。你相信吗?你要相信的话就被蒙蔽了。
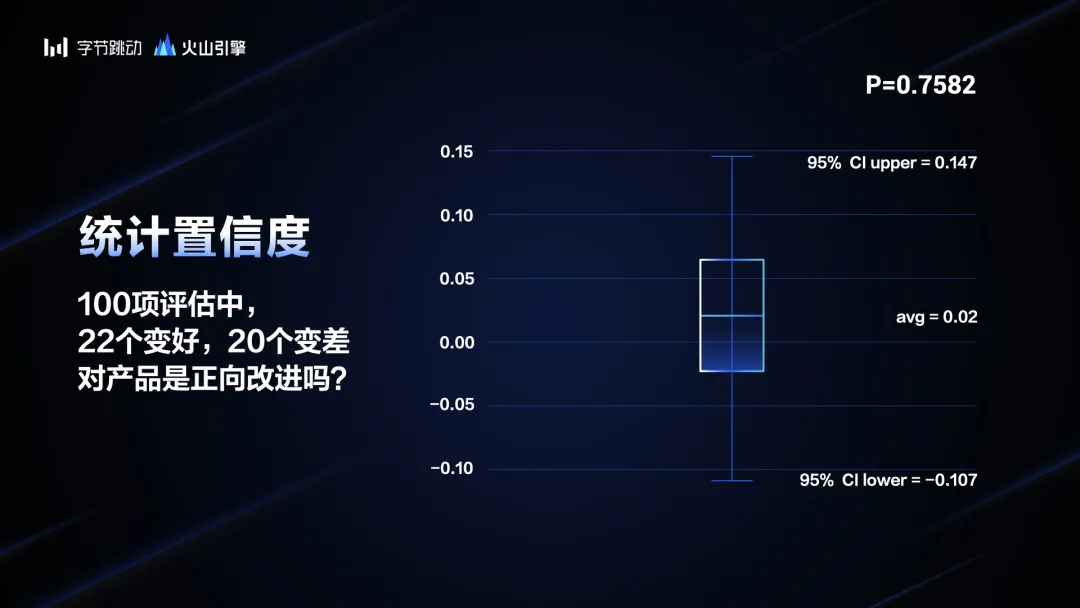
我这里写了一个置信度,P值=0.75,这是什么意思?我们通常认为,P值要小于0.05,这个数据才是可信的,也就是A比B好。0.75的意思是“A比B好”碰巧出现的概率是75%,这是不可信的。我们把这个箱型图画出来,它波动的范围如果按照95%的区间,从-0.1一直到0.147,是非常大的范围。把置信度画出来,发现这个实验完全不能说明A比B好。结论就是:这个实验不可信,没有显著性,完全不能从这个实验中得出A比B好的结论。
还有长短期的影响,这也是一个常见的问题。我举一个例子,比如说,我们对每个商品会有评价,现在兴趣电商比较热,电商的推荐主要会考虑它的评价,对于评价低的商品,我们会做一些控制和惩罚,让它的推荐少一些。如果加大惩罚力度,或者由不惩罚变成惩罚,交易量会怎么样变化?
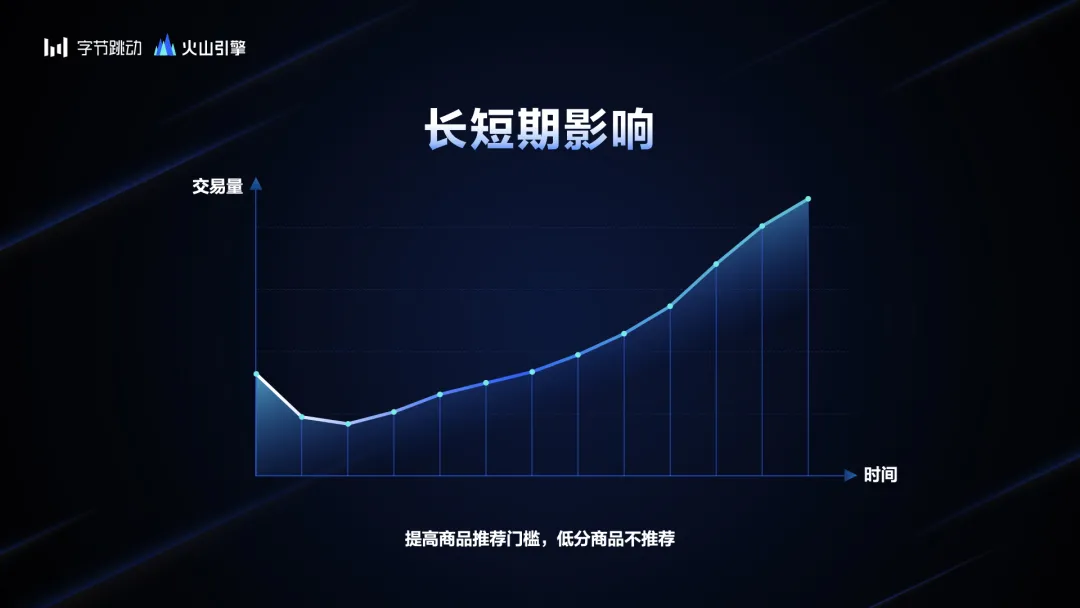
如果做A/B实验,会发现加上这个惩罚,它的交易量是下降的。这很显然,商品本来可以买,现在不让买了,那它的交易量肯定下降。如果你看了A/B测试,说我们不应该做,对这些差的产品就应该保持,那你很可能就错了。
有时候,靠人的经验相信这个事情是对的,坚持做,你很可能会得到一个正确的答案。为什么?我们这个实验不再测3天或者1个星期,而是测1个月,你会发现,这个交易量开始是下降的,但是慢慢持平了。随着时间再往前推移,它的交易量就变好了。
可以想象,
当你做了一些正确的事情,短期可能会受一定损失,但是积累了用户口碑,这些东西周期都很长的,慢慢效果就体现出来了。A/B测试通常不会做那么多时间。
所以有时候要结合判断相信背后本质的东西,可以用更长期的A/B测试验证它,这时候你会做出更正确的选择。如果相信短期,就掉到沟里了,得出错误的结论。
抖音的名字是怎么来的?最后再讲讲抖音取名字的故事。很多人都很关心这件事,甚至有人说抖音的名字是找大师算过的。起名字是可以做A/B测试的。当年,我们做了这个短视频产品,有很多候选名字,那会儿已经有一些产品demo了。
我们就把这个demo产品起成不同的名字,用不同的logo,在应用市场商店做A/B测试,同样的预算,同样的位置,这能测出用户对这个名字的关心程度,吸引力程度,下载转化率等等,但其实也是非常短期的。
做完这个测试之后,我们得出了一个排名,比如第一名是什么,第二名是什么。“抖音”是排名第二的,不是最好的名字。当时负责抖音的产品经理,讨论应该用哪个名字。
你去看这个分析和排名,看那个过程,就会发现有一些是符合你的感觉,有一些不是符合你的感觉,才知道,原来人们对这个东西可能会这么想。所以A/B测试的过程,有时不完全看它的结论,它也会给你带来很多认知,这就是经验带来的偏差。A/B测试可以纠正这些偏差,但是它也会有这样或那样的问题,有时候你不会完全采纳它的结论。
我们就没有采纳排名第一的名字,大家觉得,“抖音”长期来讲更符合认知,更能体现它的形态,所以就选择了“抖音”这个排名第二的选项。
从这个故事中可以看到,真正想去做一个科学决策,是很难有完美方法的,没有一招鲜的方法,只有最合适的方法。
充分地做A/B测试,这是一个能够在很大程度上补充信息的过程,能够消除很多偏见,能够带来很多客观的事实。但是它也不是完美的,需要补充其他方法一起来用。就像“抖音”起名字的例子一样。在公司中更广泛地使用A/B测试,我相信对提高整个公司的决策质量是很有帮助的。