标签:一致性哈希 有一个 直接 拆分 value 服务 nlog 决定 限流
整体分成三部分缓存:应用Nginx本地缓存、分布式缓存、Tomcat堆缓存。
每层都用来解决相关问题,第一层解决热点缓存的问题,第二层减少访问回源率,第三层防止相关缓存失效/崩溃之后的冲击
11.2.1 过期与不过期
过不过期应该根据业务和数据量等因素决定
不过期缓存的场景
对于访问频率很高的场景,或者缓存空间足够,都可以考虑不过期缓存,比如用户、分类、商品、价格、订单等。当缓存满了,考虑使用LRU机制驱逐老缓存数据。
不过期缓存的更新设计
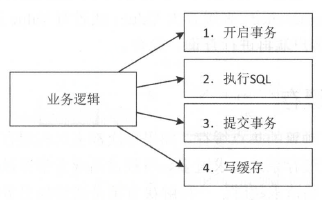
注意不要把写缓存放到事务中,特别是分布式缓存,因为网络抖动可能导致写缓存响应时间很慢,引起数据库事务阻塞。如果数据量不大且实时性要求不高,可以考虑全量同步缓存。
过期缓存的场景
一般用于缓存其他系统的数据(无法订阅变更消息或者成本很高)、缓存空间有限、低频热点缓存等场景。热点数据因为频繁更新,经常使用过期缓存。
11.2.2 维度化缓存与增量缓存
当全部更新成本很高时,只更新变化的部分
11.2.3 大Value缓存
使用Redis避免设置大Value,因为Redis是单线程操作,更新大Value将会占用很长时间造成其他请求等待超时。此时可以考虑使用多线程实现的缓存比如Memcached。或者对Value进行压缩,或者将Value拆分成多个小Value,由客户端进行查询和聚合。
11.2.4 热点缓存
对于访问非常频繁的热点缓存,如果每次都去远程缓存系统获取,可能会因为访问量太大导致远程缓存系统请求过多,负载过高或者贷款过高等问题。可以对分布式缓存做主从或集群,或者简单的在本地也做一个短时间的缓存。
11.3.1 缓存分布式
将缓存分散到多个实例或者多台服务器,使用一致性哈希分片,或者使用Redis集群
11.3.2 应用负载均衡
请求进入接入层Nginx,根据负载均衡算法将请求转发给应用Nginx,如果应用Nginx本地缓存命中,则直接返回数据,否则读取分布式缓存或者回源到Tomcat
一般采用轮询或一致性哈希。
轮询的优点是请求更加均匀,每个服务器负载基本一致,不会因为热点问题导致其中一台服务器负载过重,缺点是当Nginx服务器增加,缓存的命中率降低。
一致性哈希的优点是命中率高,且不会应为服务器的增加或减少而降低。缺点是如果热点数据在一台服务器上,会被打崩。解决方案:
(1)负载较低时,使用一致性哈希
(2)热点请求降级一致性哈希为轮询
(3)将热点数据推送到接入层Nginx,直接响应给用户
热点数据缓存方案
11.4.1 单机全量缓存+主从
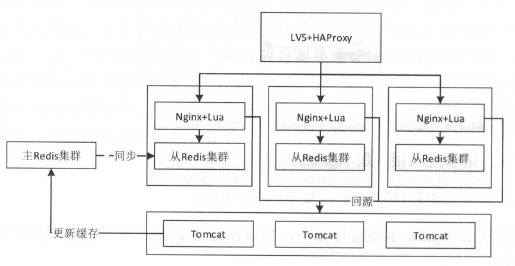
11.4.2 分布式缓存+应用本地热点
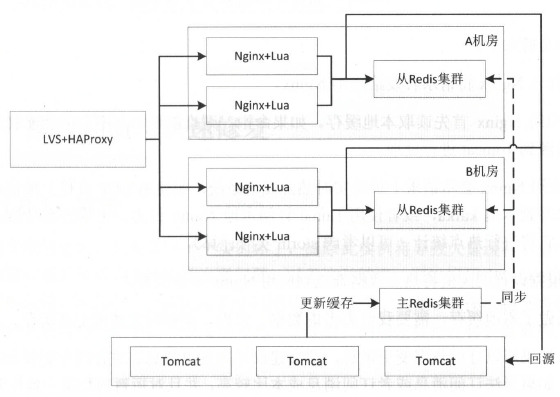
在应用层Nginx和分布式集群中都设置缓存,若不存在则回源Tomcat。
针对同时更新一份数据冲突的解决策略
1. 更新数据时使用更新时间戳或者版本对比,如果使用Redis,则可以利用单线程机制进行原子化更新
2. 使用canal订阅数据库binlog
3. 更新请求按照相应规则分散到多个队列,每个队列进行单线程更新,更新时拉取最新的数据保存
4. 使用分布式锁,在更新之前获取相关锁
11.6.1 取模
使用取模来实现负载均衡时,当集群中节点下线或者新增,都会导致大量缓存不命中。对于节点下线,可以使用主从解决。对于新增节点,一般是另起一个集群,将数据迁移到新集群,或者停机更新。
11.6.2 一致性哈希
采用一致性哈希实现负载均衡,新增或者节点下线,影响的只有一个节点的缓存。
11.6.3 快速恢复
1. 主从机制,做好冗余备份,主节点坏了从节点顶上
2. 如果已经出现缓存失效,为了避免造成雪崩,需要将部分用户降级或者限流,然后慢慢还原,在这段时间内,后台通过Worker预热缓存数据
标签:一致性哈希 有一个 直接 拆分 value 服务 nlog 决定 限流
原文地址:https://www.cnblogs.com/walker993/p/14701532.html